Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs 리뷰 (CVPR 2016)

이 논문은 2016년 소개된 Video Action Localization 논문으로, Object Detection을 위한 2-stage 방법들과 유사하게 Proposal Network와 Classification, Localization Network 총 3가지로 구성된 Multi Stage 3D CNN을 활용한 Action Localization을 수행한다.

Action Localization이란 영상이 어떤 Action을 담고 있는지 분류하는 Action Recognition에서 나아가, 영상의 어떤 구간이 어떤 행동을 담고 있는지, Temporal 한 정보까지 다루는 task이다. video recognition은 명백하게 하나의 action을 포함하도록 편집된 영상(trimmed video)을 사용하지만, 실생활에서 사용되는 영상은 대부분 그렇지 않은 비편집 영상(untrimmed video) 임을 고려하면 Action Localization이 더욱 실용적이고 중요한 분야임을 알 수 있다.
untrimmed video에는 아무런 행동이 일어나지 않는 background 구간이 있기도 하고, 한 영상에서 시간에 따라 다른 action들이 나타나기도 하기 때문에, 여러 종류와 갯수의 객체가 등장하는 object detection과의 유사점이 많다.
저자들은 당시 빠르게 발전하던 R-CNN 기반의 Object Detection 모델들과 유사하게, 영상에서 action이 일어나고 있는 구간을 proposal하는 신경망과 구체적으로 어떤 action이 일어나고 있는지 분류하는 classification / localization 세 가지 신경망을 통하여 Action Localization을 수행하였다. 저자들이 주장하는 contribution은 다음과 같다.
- 최초로 untrimeed long video에서 명시적인 Multi-Stage 구조의 3D CNN을 활용한 Temporal Action Localization을 수행
- 이를 위한 Multi-Stage Segment-CNN 방법을 제안함.
- 제안한 방법은 당시 MEXaction2, THUMOS 2014 대규모 벤치마크에서 SOTA를 달성함.
Annotation
$T$개의 프레임을 갖는 영상은 $X=\{ x_t\}^T_{t=1}$로 정의되며, $x_t$는 이 영상의 $t$번째 프레임을 나타낸다. 각 영상은 라벨 $\Psi = \{( \psi_m, \psi'_m, k_m )\}^M_{m=1}$를 갖는데, $M$은 해당 영상에 포함된 action의 수이며, $k_m\in\{ 1, \cdots, K\}$은 action의 종류, $\psi_m, \psi'_m$은 각각 action의 시작 프레임과 마지막 프레임이다. 학습 과정에서 trimmed video들의 집합인 $\mathcal{T}$와 untrimmed video들의 집합인 $\mathcal{U}$가 사용되는데, $\mathcal{T}$에 포함된 영상은 $\psi_m=1, \psi'_m=T, M=1$을 갖는다.
Segment-CNN
Multi-scale segment generation
먼저 영상을 다양한 크기의 segment로 나눈다. 각 프레임은 $171\times 128$크기로 조정되며, untrimmed video $X\in \mathcal{U}$의 경우 시간축으로 75%의 overlap을 갖는 $16, 32, 64, 128, 256, 512$ 프레임의 segment들로 분할한다.

분할된 segment들에서 16프레임을 균등하게 추출하여 결과적으로, untrimmed video $X\in \mathcal{U}$를 신경망에 입력할 $\Phi = \{(s_h, \phi_h, \phi'_h) \}^H_{h=1}$ 형태로 분할해 준다. $H$는 $X$에서 추출한 segment의 개수이고, $\phi_h, \phi'_h$는 각각 segment의 시작과 마지막 프레임, $s_h$는 $h$번째 segment를 의미한다. trimmed video $X\in \mathcal{T}$에 대해서는 분할을 수행하지 않고 바로 16 프레임을 균등하게 추출한다. 결과적으로 신경망에 입력되는 segment의 크기는 $171\times 128 \times 16$이다.
Proposal Network

proposal network $\Theta_{pro}$는 action이 일어나지 않는 background segment와 action이 일어나는 segment를 분류하는 이진 분류를 수행한다. 저자들은 trimmed video $X\in \mathcal{T}$들과 untrimmed video $X\in\mathcal{U}$에서 추출한 segment 중, action이 일어나는 영역과의 IOU(intersection over union)가 0.7 초과인 segment들을 positive(action이 있음)로 사용하고, IOU가 0.7 이하인 segment들을 negative(background)로 사용하여 모델을 학습시켰다. 만약 segment 중에 IOU가 0.7 초과인 segment가 없다면 기준을 0.5로 낮추었다고 한다.
Classification Network

Proposal network에서 background에 해당하는 segment들이 걸러진 후, $\Theta_{cls}$를 학습하였다. 이 신경망은 background와 더불어 $K$종류의 action들에 대한 분류를 수행한다. 각 action 클래스의 segment보다 background가 더 많기 때문에, 저자들은 각 클래스에 해당하는 학습 데이터의 수를 맞추고 학습을 진행하였다.
Classification Network는 실제로 추론을 수행할 때는 사용되지 않는다. 그 대신 후술할 Localization Network를 학습할 때, Classification Network를 사전학습하여 진행된다. 사실상 두 신경망이 같은 신경망이기 때문에 Classification이 Pretext task와 유사하게 보이는데 저자들이 굳이 다른 신경망인 것처럼 소개한 이유를 모르겠다.
Localization Network


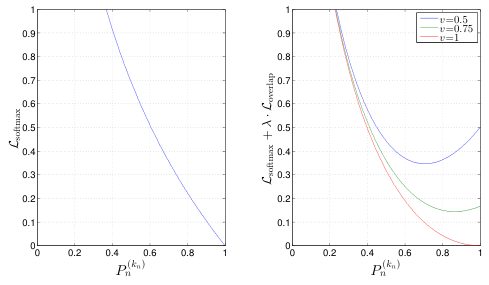
예측을 수행한 후 후처리 단계에서 action과 가장 overlap이 많은 segment를 선택하게 하려면, 결국 action과 overlap이 많은 segment에 더 높은 confidence score를 할당해야 한다. <그림 6>을 보면, 가장 label과 유사한 segment B가 더 높은 score를 갖는 segment B에 의해 삭제되는 안 좋은 사례를 볼 수 있다. 이를 방지하기 위해 $\Theta_{loc}$은 IOU를 고려하는 새로운 Loss로 학습된다. $\Theta_{loc}$의 학습 데이터는 앞서 $\Theta_{cls}$를 학습할 때 사용한 것에 overlap에 해당하는 $v$가 추가되어 구성된다. trimmed video의 경우 영상 전체가 action에 해당하므로 $v=1$이다. 신경망은 이번에도 각 segment의 action클래스, 혹은 background 여부를 분류한다. Localization Network의 Loss $\mathcal{L}$은 다음과 같이 정의된다.
$$\mathcal{L} = \mathcal{L}_{\text{softmax}} + \lambda \cdot \mathcal{L}_{\text{overlap}}$$
$\lambda$는 손실 함수의 비율 조절하는 하이퍼파라미터로, 저자들은 1을 설정하였다. $\mathcal{L}_{\text{softmax}}$는 일반적으로 분류 문제에 적용하는 소프트맥스 손실 함수이고, $\mathcal{L}_{\text{overlap}}$은 overlap의 정도에 따라 조절되는 손실 함수로 아래와 같다.
$$\mathcal{L}_{\text{overlap}} = \frac{1}{N} \sum_n (\frac{1}{2} \cdot (\frac{(P_n^{(k_n)})^2}{(v_n)^\alpha} - 1) \cdot [k_n > 0]). $$
$[k_n > 0]$은 학습 샘플이 action을 가진 positive 샘플일 때 1이 되고, background 샘플이라면 0이 되어 이 Loss는 적용하지 않게 된다. Softmax를 통과한 confidence score $P_n$의 제곱을 overlap 수준인 $v$의 $\alpha$ 제곱으로 나눔으로써 overlap이 큰 샘플에 높은 confidence를 부여하도록 학습시킨다. 이때 민감도를 조절하는 하이퍼파라미터 $\alpha$가 높을수록 overlap이 낮은 샘플에 높은 score를 부여할 경우 주어지는 페널티가 강해진다.
Prediction and post-processing
예측 시에는 다양한 segment로 분할한 영상을 $\Theta_{pro}$에 입력하여 proposal score $P_{pro}$를 얻고, $P_{pro}\geq0.7$인 segment들을 취한다. 이렇게 얻어진 후보 segment들을 $\Theta_{loc}$에 입력하여 action category prediction score $P_{loc}$을 얻는다. 후처리 과정에서, background로 분류된 segment들은 모두 제거하고, 분류된 segment들에 Non Max Suppression(NMS)을 적용하여 중복 예측을 제거한다.
Experiments

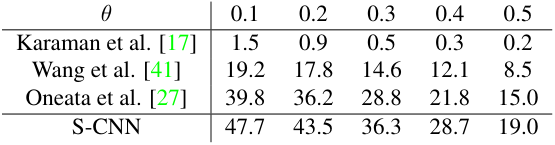
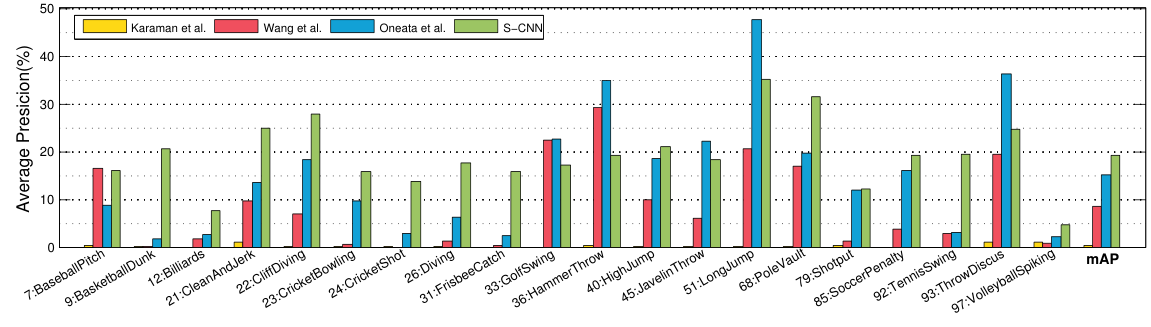
저자들은 MEXaction2, THUMOS 2014 데이터에서 제안한 S-CNN의 성능을 측정하였다. 그 결과 기존 방법론들에 비해 일부 클래스를 제외하고는 상대적으로 더 좋은 AP를 얻을 수 있었다. 또한 S-CNN은 기존 방법들에 비해 효율적이라고 하는데, 다른 모델들과의 구체적인 비교는 없고 저자들의 실험 환경에서 배치 당 1초 정도가 소요되었다고 한다.
ablation study
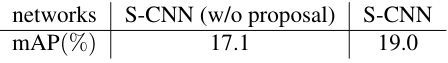
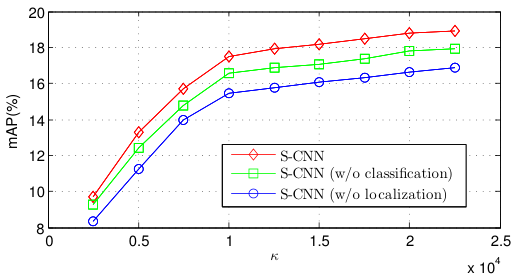
저자들은 모델의 각 요소들이 성능에 미치는 영향을 분석하였다. 그 결과 proposal network를 적용하여 1차적으로 background segment를 걸러주는 것이 mAP를 향상하였고, classification network를 통해 localization network를 사전학습하는 것, overlap을 고려하는 loss로 학습한 localization network를 사용하는 것이 성능을 향상함을 확인했다.
proposal network가 없어도 꽤나 성능이 나오는 것은 의외이다.
결론
저자들은 2-stage object detection과 유사하게 영상 속 action이 발생하는 구간을 proposal 하는 network와 이를 분류하는 network로 구성된 action localization 모델을 제안하였다. 시간이 많이 지난 논문이라 그런지 지금은 굳이 설명하지 않는 softmax 공식 같은 세부적인 내용도 논문에 소개되어 있어 신기했다.