TAL-Net: Rethinking the Faster R-CNN Architecture for Temporal Action Localization 리뷰 (CVPR 2018)
이 논문은 최근 필자가 자주 보고 있는 Video Action Localization Task를 위한 TAL-Net을 제안한 논문으로, 이전에 리뷰한 R-C3D와 유사하게 Faster R-CNN에서 영감을 받은 논문이라고 한다. 저자들은 THUMOS'14 데이터셋과 ActivityNet Challenge에서 action proposal과 localization에서 모두 SOTA를 달성하였다.
저자들은 Temporal Action Localization Task를 위해 Faster R-CNN 구조를 활용하며 다음 요소들에 주안점을 두었다.
- 매우 다양한 길이의 action들을 어떻게 다룰 것인가?
- action의 길이는 아주 큰 다양성을 갖는데, Faster R-CNN의 앵커 구조로는 담기 어렵다.
- Temporal Context를 어떻게 활용할 것인가?
- action을 판단함에 있어 temporal context는 spatial 한 정보 이상으로 매우 중요하다.
- Multi-stream feature를 어떻게 잘 fusion할 것인가?
- Action Localization에는 흔히 RGB, Optical Flow 두 feature를 사용하지만 정작 이 feature들을 잘 fusion 하는 연구가 되어있지 않다.
Related Work
Action Recognition은 어떤 하나의 action을 포함하고 있는 편집된 영상(trimmed video)의 action을 분류하는 task이다. 이러한 task는 실용성이 없기 때문에, 최근에는 아래에 설명할 Temporal Action Localization으로 연구가 넘어갔다.
Temporal Action Localization은 일반적으로 길이가 긴 편집되지 않은 영상(untrimmed video)에서 어떤 action과 해당 action의 시작 지점 및 끝 지점을 찾아내는 task이다. 초창기에는 temporal sliding window를 통해 영상을 분할하여 SVM과 같은 분류기에 입력하여 action classification으로 문제를 해결하였다. 그러나 이러한 방법은 매우 많은 연산이 필요하여 비효율적이다. 그 다음 방법은 frame, 혹은 snippet(영상을 분할한 작은 단위) 단위로 action labeling을 수행하는 방법이 있었는데, 이 또한 상술한 이유로 효율적이지 못하다.
(논문 당시) 최근에는 Region 기반 object detector의 성공에 따라 영상에서도 먼저 관심 영역을 추출하고 이에 대한 분류를 수행하는 2-stage 방법들이 많이 연구되었다. 이러한 연구들은 대부분 segment proposal의 성능을 향상하거나 classification 성능을 향상하는데 집중하였다. 그러나 이러한 방법들은 대부분 end-to-end 학습이 불가하고, 정해진 크기의 sliding window를 사용하여 다양한 길이의 action을 잡지 못하는 단점이 있었다. 그나마 R-C3D는 Faster R-CNN의 설계를 충실히 이식하여 좋은 성능을 내기는 하였다.
Faster R-CNN

먼저 TAL-Net의 기반이 된 Faster R-CNN 구조를 되짚어 보자. Faster R-CNN은 어떤 이미지 내부에서 물체의 위치 정보를 알아내는 것을 목적으로 한다. 먼저, 입력 이미지에서 2D ConvNet을 이용해 2D feature map을 생성한 후, 이를 Region Proposal Network(RPN)라 하는 2D CNN에 입력한다. 이 신경망은 사전에 정의된 다양한 크기의 앵커(anchor) 들을 이용하여 물체가 있을 것으로 추정되는 영역을 제안한다. 이때, 물체의 예상 boundary 또한 앵커 박스에 상대적인 크기로 회귀를 이용하여 얻어진다 그다음, 제안된 각 영역들에서 고정된 크기의 feature map을 풀링(RoI Pooling)하여 이를 이용해 각 물체의 클래스를 판별한다.

물체의 2D 위치 정보를 파악하는 Object Detection과 어떤 action의 1D 시간 정보를 파악하는 Temporal Action Localization은 유사하다. 위 그림과 같이 이를 Object Detection 모델 형태로 나타낼 수 있다. 이 방법 또한 Object Detection과 유사하게 두 단계로 나타낼 수 있다. 먼저, 주어진 frame sequence에서 1D Feature Map을 추출하여 1D CNN인 Segment Proposal Network에 입력한다. 그 다음, 1D RoI Pooling과 DNN을 통해 각 proposal에 대한 classification을 수행한다.
TAL-Net
TAL-Net은 기본적으로 앞서 설명한 Faster R-CNN 구조를 따르지만, 3가지 중요한 변경점이 있다.
Receptive Field Alignment

Faster R-CNN에서는 Feature Map에 $K$개의 앵커에 해당하는 $K$개의 채널을 갖는 $1\times 1$ 합성곱을 진행하여 각 채널의 한 픽셀 값을 해당 위치의 특정 앵커 속 물체의 존재 확률로 보아 앵커를 적용했다. 이러한 방법은 Object Detection에서는 괜찮지만, action의 길이가 가질 수 있는 범위가 넓은 영상에서는 모든 앵커가 같은 receptive field를 갖는 것이 안 좋을 수 있다. receptive field는 너무 작거나 커서는 안되며, 다양한 스케일을 가져야 한다.
저자들은 앵커의 receptive field가 다양해지도록 하기 위해, multi-tower network와 dilated temporal convolution을 적용했다. 먼저, multi-tower network는 1D feature map이 주어질 때, Segment Proposal Network는 각각이 어떤 크기의 앵커 segment를 담당하는 $K$개의 temporal ConvNet을 적용한다. (위 그림의 우측) 각 ConvNet은 서로 다른 크기의 receptive field를 가지며 최종적으로 커널 크기 1의 합성곱을 수행해 action의 존재 여부를 예측한다.

또한, 각 ConvNet의 receptive field 크기 $s$를 조절하기 위해 dilated pooling을 활용하였다. 위 그림과 같이 receptive field size의 조절에 dilated convolution을 활용하여, 합성곱 계층을 추가하여 오버피팅의 위험을 감수하지 않고도 receptive field 크기를 조절할 수 있었다. 저자들은 첫 dilated convolution에 앞서 dilation late와 같은 크기의 max pooling을 통해 입력값을 smoothing 해줬다.
Context Feature Extraction
Action Localization에 있어 맥락(context) 정보는 아주 중요하다.
다이빙 보드 위에 서 있는 사람은 곧 "diving" action이 일어날 것임을 알려주고, 공중에 날아가고 있는 투포환은 방금 "javelin throw" action이 일어났음을 알려준다. 저자들은 이러한 중요한 context feature를 proposal 생성과 classification 단계에서 모두 활용하였다.
저자들은 앞서 Proposal 생성 단계에서 다양한 크기 $s$를 갖는 앵커들을 만들었지만, 이 앵커들은 결국 action이 벌어지는 범위만을 다룰 뿐 그 앞뒤의 맥락이 담겨있는 장면들까지는 고려하지 않는다. 저자들은 명시적으로 각 앵커의 앞 뒤 $s/2$만큼의 구간에서 얻은 정보를 추가해줌으로써 신경망이 맥락 정보도 고려하게 만들었다.

이를 위해 Proposal 단계에서 convolution의 dilation size를 2배로 늘렸다.

분류 단계에서는, 앞서 얻은 proposal들로부터 고정된 크기 $7$의 feature map을 얻기 위하여 SoI Pooling을 수행하였다. 이때, 위 그림의 하단에 표기된 것처럼 $s$ 크기의 proposal에 대하여 앞뒤로 $s/2$의 영역을 추가로 pooling하여 context 정보를 추가했다. SoI Pooling이후, 저자들은 FC 계층 2개를 통해 최종적으로 action classification과 boundary regression을 수행하였다.
Late Feature Fusion
많은 video 관련 모델들이 영상의 RGB feature 이외에도 Optical Flow라고 하는 정보를 사용하여 좋은 성능을 내고있다. 일반적으로 이 모델들은 각 모달로 별도의 예측을 수행한 후, 두 결과를 합쳐 최종 점수를 생성하는데, 저자들은 Faster R-CNN 구조를 위한 late fusion 방법을 제안한다.
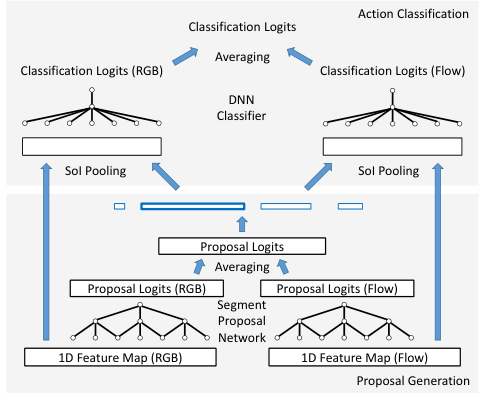
저자들은 먼저 각각의 모델로 Segment Proposal을 수행한 후, 그 결과를 평균하여 최종 Proposal을 생성한다. 이렇게 얻어진 proposal을 활용해 다시 각 모달에서 SoI Pooling을 수행하여 Classification을 진행한 후, 얻어진 두 모달의 결과를 평균하여 최종 결과를 생성한다. 다른 방법들이 결과만을 fusion 한 것과 달리, Proposal을 fuse 한 것이 차이점이다.
Experiments
논문의 실험 환경에 대한 설명이 상당히 친절하여 직접 읽어보기를 권한다.
저자들은 THUMOS'14 데이터셋에서 ablation study를 진행하였다. 지표는 Average Recall(AR)과 Average Number of Proposals per Video(AN), mAP를 사용하였다. 일반적으로 AN이 증가할 수록 위양성도 증가하기 때문에 AR은 상승하지만 mAP는 감소한다.
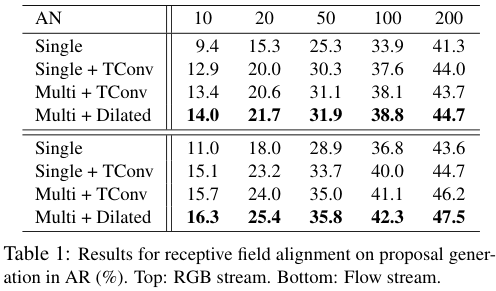
저자들은 실험(표 1)을 통해 Receptive Field Alignment의 효과를 확인했다. temporal convolution 없는 Single-Tower network를 통해 각 앵커가 오직 앵커의 중심부 feature만을 고려하여 예측을 수행한 결과 가장 성능이 좋지 않았고, Temporal Convolution, 특히 Dilated Temporal Convolution을 수행한 결과가 가장 좋았다.
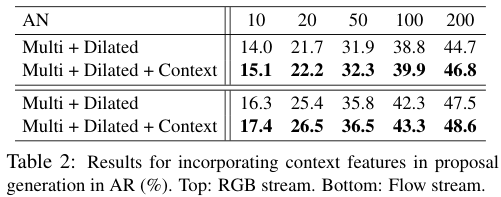
저자들은 실험(표 2)을 통해, proposal 생성 단계에서의 context feature extraction의 효과를 확인했다. 그 결과 context 정보를 더해주는 것이 성능을 향상하였다.

Classification 단계에서 역시 context feature를 더해주는 것이 더 좋은 성능을 보였다.
그러나 IoU 임계값이 높은 경우에는 오히려 성능이 감소하거나 비슷한 모습도 보였는데, 이는 context 정보의 추가로 인하여 모델이 anchor에 비해 조금 더 자유로운 예측을 하게 된 것이 boundary 예측을 약간 방해한 것이 아닌가 싶다. (필자의 추측임)
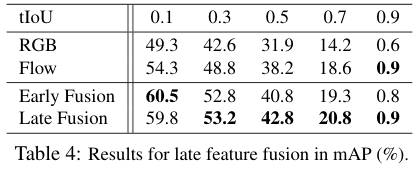
마지막으로 저자들은 각 모달의 성능과 Fusion 방법에 따른 성능 차이를 확인하였다. Fusion을 수행한 결과 중 Late Fusion이 Early Fusion보다 일반적으로 좋았다. tIoU가 0.1인 경우 Early Fusion이 좋았지만, 이는 예측의 질이 떨어짐을 의미하므로 대체로 저자들이 제안한 방법이 좋다고 할 수 있겠다.
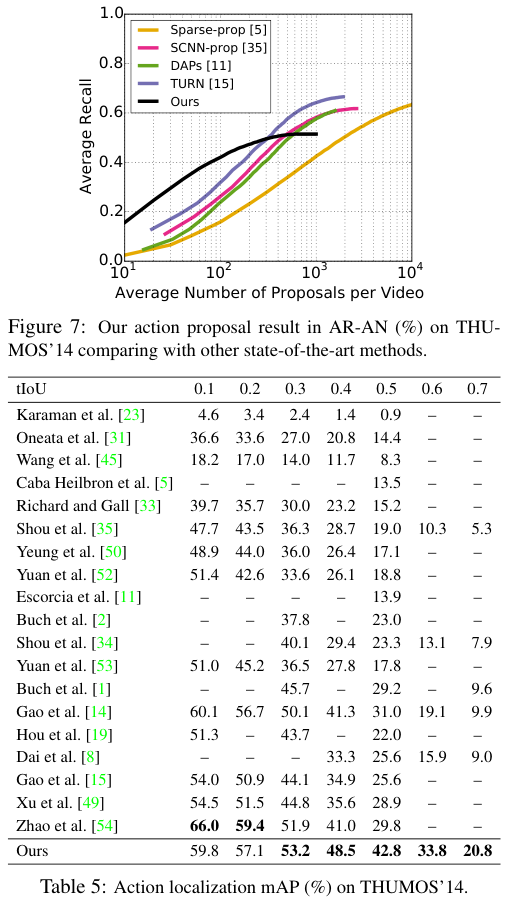
저자들은 THUMOS'14 데이터셋에서 기존 SOTA 모델들과의 비교를 수행하였고, 그 결과 일부 낮은 tIoU를 제외하고 가장 높은 성능을 보여 SOTA를 달성하였다. 다만 tIoU를 낮출수록 성능이 다른 모델 대비 떨어지는 경향이 있어 특이하다.

한편 ActivityNet에서는 다른 모델들에 비해 유독 좋지 못한 성능을 내고 있다. 이 부분에 대하여 저자들은 THUMOS'14 데이터셋이 평가에 더욱 적합하다는 말을 짤막하게 하는데, 해당 데이터셋에서 성능이 낮은 것에 대한 별다른 설명이 없어 아쉽다.
결론
저자들은 Faster R-CNN 구조를 따른 Temporal Action Localization을 위한 TAL-Net을 제안하였다.
이 모델은 다양한 범위의 Temporal Receptive Field를 갖는 앵커들을 얻기 위해 Dilated Convolution과 Multi-tower network 구조를 사용하였고, 앵커 주변의 context feature를 명시적으로 추가해 주었으며, proposal 단계에서 late feature fusion을 수행하였다.
전체적으로 좋은 시도가 많이 보였지만, 사실 Faster R-CNN 구조를 너무 신봉하는 것 아닌가 하는 생각도 들었다. (물론 나에게 더 나은 방법이 있냐고 물어보시면.. 할말이 없긴 하다.)
마지막에 ActivityNet에서의 성능이 낮은 부분도 의외였다.