Vision Transformer 리뷰 (ViT)
2017년, 그야말로 혜성처럼 등장한 트랜스포머는 자연어 처리 분야의 모든 분야에서 놀라운 성능을 보여주며 그야말로 분야를 정복해 버렸다. 트랜스포머의 강점은 컴퓨팅의 효율성과 scalability에 있었다.
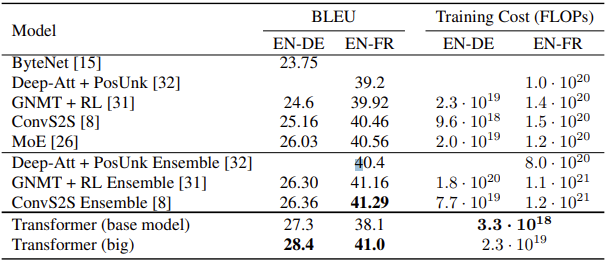
트랜스포머는 다른 모델에 비해 학습에 요구되는 연산량이 적었다. 또한, n개의 반복되는 인코더-디코더 구조로 구성되어 모델의 크기를 조절하기가 매우 용이했다. 덕분에 연구자들은 손쉽게 매우 큰 규모의 트랜스포머 기반 신경망을 설계할 수 있었으며, 트랜스포머 모델에서는 (데이터가 충분히 클 경우) 모델의 크기가 커짐에 따라 성능이 하락하는 saturation도 발생하지 않았다.
이러한 트랜스포머의 성공에 힘입어, 이미지를 다루는 컴퓨터 비전 분야에서도 트랜스포머나 셀프 어텐션 구조를 활용하려는 다양한 시도가 있었다. CNN에 셀프 어텐션을 활용하거나, 아예 합성곱 계층 자체를 어텐션으로 대체하는 등 다양한 시도가 있었지만, 이러한 방법들은 복잡한 어텐션 방식을 사용하여 하드웨어 가속기와 잘 호환되지 않았고, 때문에 트랜스포머의 장점인 scalability가 좋지 않았다. 때문에 여전히 ResNet 방식의 모델들이 SOTA를 달성하고 있는 상황이었다.
저자들은 최대한 NLP에서 사용되는 기존 트랜스포머의 구조를 유지하며 이를 컴퓨터 비전 분야에 적용하였다. 이미지를 패치 단위로 나누고, 1차원 벡터로 선형 임베딩을 수행하여 입력함으로써 이미지의 패치들이 NLP의 word tokens와 비슷한 형태로 입력되도록 한 것이다.
저자들은 이렇게 개발한 비전 트랜스포머(ViT)가 일반적인 경우에는 ResNet 기반의 방법들과 비슷하거나 더 적은 성능을 내지만, 대규모의 데이터셋을 사용하여 사전학습을 거치고 fine-tuning해서 사용할 경우 놀라운 성능을 보이는 것을 발견하였다. 저자들이 ImageNet-21k 데이터셋이나 구글 내부 데이터셋인 JFT-300M에서 사전학습을 진행하고 다른 task를 수행해 본 결과, ImageNet에서 88.55%, CIFAR-100에서 94.55%와 같이 매우 높은 성능을 보였다.
저자들은 ViT가 합성곱 계층이 제공하는 translation equivariance나 지역성(locality)과 같은 inductive bias를 가지고 있지 않아 데이터가 적은 상황에서는 CNN에 비해 generalization 성능이 낮지만, 충분한 데이터가 주어지면 이러한 단점을 극복할 수 있는 것으로 보았다. Inductive Bias에 대한 자세한 설명은 하단에서 다루었다.
만약 NLP에서의 트랜스포머를 잘 모른다면, 다음 내용에 앞서 필자의 이전 리뷰글을 참고해보길 권한다.
Related Work
트랜스포머의 성공에 힘입어, 많은 연구들이 컴퓨터 비전 분야에 다양한 방법으로 셀프 어텐션을 적용하고자 했다.
그러나 이미지의 모든 픽셀에 셀프 어텐션을 적용하는 것은 지수적인 연산량 증가를 의미하기에 불가능했고, 인접한 이웃 픽셀 간의 어텐션만을 진행하거나, 특정 영역 안의 픽셀에만 적용하는 등, 다양한 방법이 시도되었다. 이러한 방법들은 대체로 유망한 결과를 내었으나, 복잡한 구조를 사용하여 AI 연구에 필수적인 하드웨어(GPU) 가속 컴퓨팅을 적용하기 어려웠다.
Method
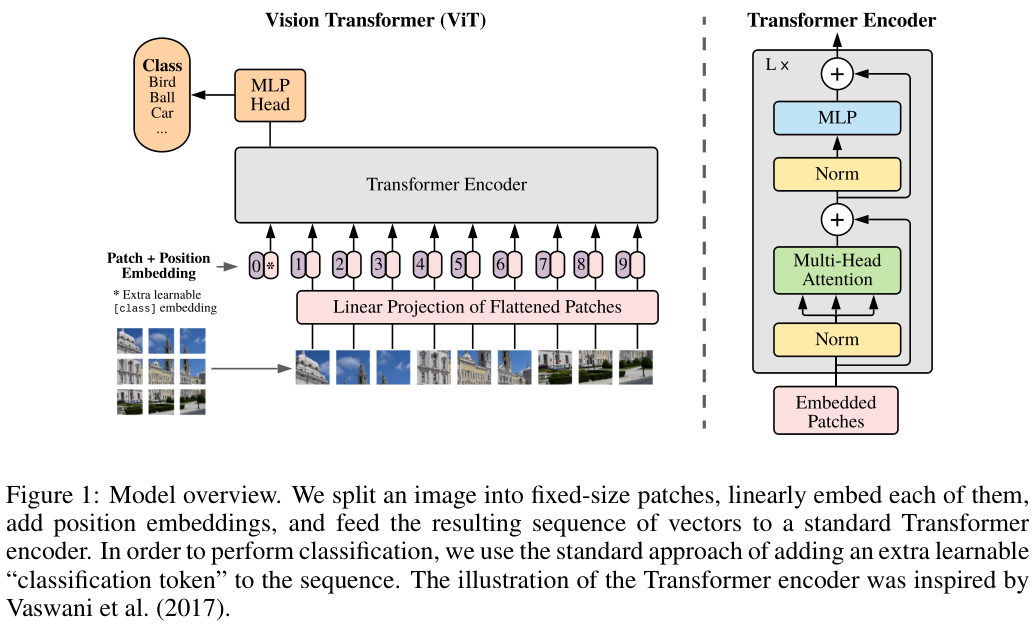
모델 구조는 전체적으로 원본 트랜스포머와 최대한 유사하게 설계되었다. 이를 통해 NLP의 트랜스포머와 같이 자유롭게 모델의 규모를 조절할 수 있었다. (scalability)
Vision Transformer (ViT)
$$\mathbb{z} = [\mathbb{x}_{class}; \mathbb{x}_p^1E, \mathbb{x}_p^2E, \cdots; \mathbb{x}_p^NE] + E_{pos}$$
$$\mathbb{y} = \text{LN}(z_L^0)$$
ViT는 입력된 2D 이미지 $\mathbb{x} \in \mathbb{R}^{H\times W \times C}$를 평탄화된 2D 패치들로 나누었다. 각 패치는 $(P, P)$의 가로세로 크기를 가지며, 평탄화된 토큰은 $\mathbb{x}_p \in \mathbb{R}^{N\times (P^2C)}$와 같은 크기를 가졌다. ($N$은 이미지를 가로세로 $P$의 패치로 나눈 개수이다.) ViT는 모델 전체에서 통일된 $D$의 벡터 크기를 사용하기 때문에, 각 패치들은 $E\in\mathbb{R}^{(P^2C)\times D}$를 통해 $D$ 차원의 벡터로 선형 변환(linear projection) 되었다. 이렇게 변환된 벡터를 패치 임베딩(patch embedding)이라 한다.
각 패치 임베딩에는 위치 정보를 부여하기 위한 positional embedding이 더해졌다. 이때, 삼각함수를 이용하여 생성된 고정 PE를 사용한 기존 트랜스포머와 달리, 학습 가능한 1D PE $E_{pos} \in \mathbb{R}^{(N+1) \times D}$를 사용하였다.
저자들은 패치 임베딩들 맨 앞에, 학습 가능한 [class] 토큰 임베딩($\mathbb{x}_{class}$)을 추가하여, 이렇게 구성된 데이터가 모든 인코더를 통과하였을 때($\mathbb{z}_L$), 클래스 토큰이 있던 위치의 토큰을 통해 라벨을 예측할 수 있도록 학습을 진행하였다.
$$\mathbb{z}'_l = \text{MSA}(\text{LN}(\mathbb{z}_{l-1})) + \mathbb{z}_{l-1}$$
$$\mathbb{z}_l = \text{MLP}(\text{LN}(\mathbb{z}'_l)) + \mathbb{z}'_l$$
트랜스포머 인코더는 멀티-헤드 셀프 어텐션(MSA)과 MLP 블록, Layer Normalization (LM)으로 구성되었으며, 각 블록에는 residual connection이 적용되었다.
Inductive Bias 문제
Bias(편향)는 머신러닝에서 예측값과 실제값의 차이(거리)를 나타낸다. Bias가 너무 높아 예측과 실제값의 차이가 크다면 언더피팅이 발생한다는 것을 한 번쯤 들어봤을 것이다. 한편 Inductive Bias는 직역하면 유도 편향이라는 뜻으로, 의도된 bias를 의미한다.
머신러닝 모델은 학습 데이터로 학습되는데, 실제 데이터는 학습 데이터와 차이가 있다. 이러한 차이를 고려하지 않고 무조건 예측값과 실제값의 차이가 전혀 없어지도록 학습한다면(즉, zero bias), 학습 데이터와 조금만 다른 데이터라도 예측을 잘 수행하지 못할 것이다.

이를 방지하기 위해, CNN을 포함한 머신러닝 모델들은 어떤 차이들에 대해서는 의도적으로 허용을 하게 되는데, 대표적인 것이 CNN의 translation invariance 속성이다. CNN의 합성곱 계층은 이미지 전체 영역에 대하여 공통된 kernel을 이용해 feature를 추출하여, 동일한 형태가 이미지의 다른 위치에 존재하더라도 해당 형태에 대해 같은 결과를 내는 특성을 갖는다. 이는 이미지에서 어떤 중요한 형태가 데이터마다 다른 위치에 등장하더라도 CNN이 예측을 잘 수행하도록 한다
기존에 컴퓨터 비전에서 활용되던 CNN은 이외에도 지역성(locality)이나 이미지의 2차원 구조를 고려하는 것, 계층적인 구조 등 다양한 inductive bias를 모델의 대부분 영역 활용한다. 그러나 ViT는 MLP만이 지역적인 정보를 고려하고, 셀프 어텐션은 전체의 정보를 모두 활용한다. 또한, 모델의 초반에 이미지를 패치로 분할하고, 각기 다른 해상도의 이미지들에 대한 positional embedding을 조정하는 fine-tuning 단계에서만 2차원 구조를 드물게 고려한다.
Fine-Tuning and Higher Resolution
일반적으로 ViT는 대규모 데이터셋에서 사전학습한 후, downstream task에 fine-tuning 한다. 이때, 사전학습에 사용한 prediction head를 제거하고 0으로 초기화된 $D\times K$ 크기의 새로운 레이어를 하나 추가한다. ($K$는 downstream class의 수) 일반적으로, fine-tuning을 더 높은 해상도의 이미지에서 진행하는 것이 더 좋은데, 더 높은 해상도의 이미지를 입력할 경우에도 패치의 크기는 바꾸지 않는다. ViT가 임의의 길이의 sequence를 입력받을 수 있기 때문이다. 그러나 이때, 사전 학습에서 학습된 positional embedding은 더 이상 활용하기 어려울 수 있기 때문에, 이에 대해 사전학습 데이터에서 PE가 맡는 영역을 고려해 2D interpolation을 수행해 준다. 이 부분만이 ViT 모델 내부에서 이미지의 2D 구조를 고려하는 유일한 inductive bias에 해당한다.
Hybrid Architecture
ViT에 이미지를 바로 패치로 나누어 입력하는 대신, 이미지를 합성곱 신경망에 입력하여 얻어진 2D feature map을 패치로 쪼개어 입력하는 하이브리드 구조도 사용할 수 있다. 저자들은 실험에서 ResNet(CNN), ViT, Hybrid ViT를 비교하였다.
Experiments
저자들은 크게 이미지넷 데이터셋과 JFT 데이터셋에서 실험을 진행하였다. 대량의 이미지를 포함한 이들 데이터셋에서 모델을 사전학습 시키고, 이를 여러 task들에 전이학습시켜 테스트를 진행한 것이다. 이때 JFT 데이터셋은 구글 내부에서만 사용할 수 있는 in-house 데이터셋이다.
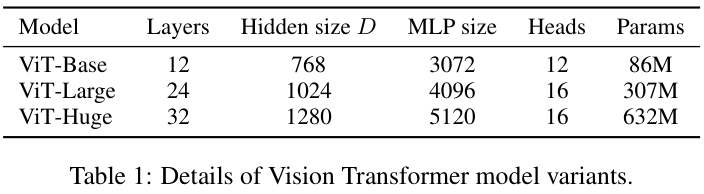
저자들은 BERT 모델과 유사하게 ViT를 설계하였는데 ViT-Base와 ViT-Large는 BERT에서 설계를 그대로 가져왔으며, 추가적으로 Huge 모델을 만들었다. 저자들은 위 표와 같은 세 가지 규모의 모델에 패치 크기를 다르게 하여 실험을 진행하였는데, 예를 들어 $16\times 16$의 패치 크기를 갖는 ViT-Large 모델은 $\text{ViT-L}/16$과 같이 표기했다. 패치 크기가 작을수록 패치의 수가 증가하므로, 연산량이 증가하는 것에 유의하여 실험을 살펴보자.
저자들은 비교를 위한 ResNet에서 batch normalization을 group normalization으로 변경하고 standardized convolution을 적용하여 개선한 모델을 사용하였다. 이를 ResNet (BiT)라 표기하였다. 하이브리드 모델의 경우 CNN 중간의 feature map을 ViT에 입력하였는데, 이때 패치 크기는 1로 하였다. feature map은 ResNet50의 stage 4에서 추출하거나, stage 4를 제거한 대신 같은 수의 레이어를 추가한 stage 3에서 추출하였다. 이를 통해 CNN의 레이어 수는 유지하면서 두 번째 경우 4배 긴 시퀀스 길이를 갖는 차이를 만들었다.
Comparison to SOTA models
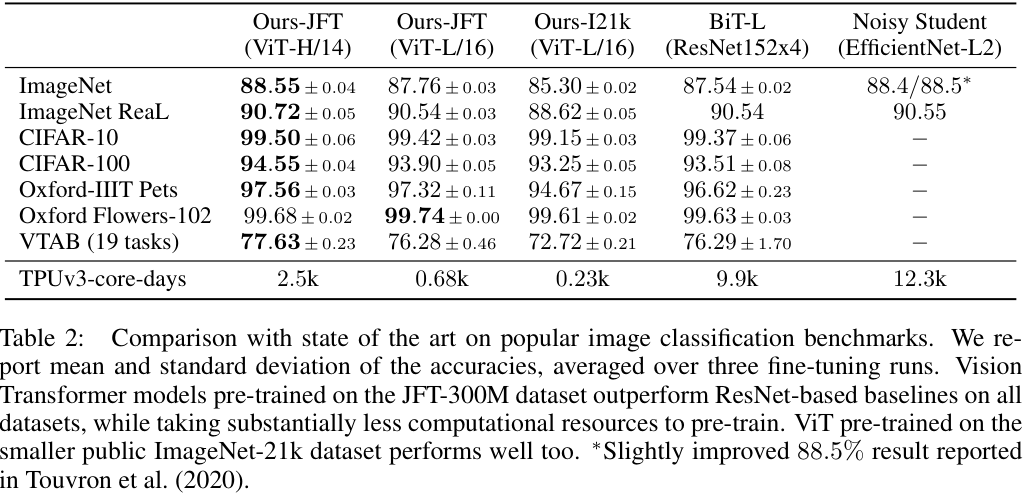
저자들은 기존 SOTA 모델인 BiT-L (ResNet을 수정한 CNN 모델), Noisy Student (EfficientNet 기반의 CNN)을 JFT와 ImageNet에서 사전학습한 모델들과 ViT를 비교하였다. ViT-L/16은 BiT-L 대비 작은 크기에도 비교하고 성능을 앞질렀고, 모델의 크기를 키운 ViT-H/14는 여전히 기존 SOTA 모델 대비 적은 연산양으로 기존 모델들을 앞질렀다. 저자들은 ViT가 기존 SOTA 모델들 대비 더 적은 자원으로 사전학습할 수 있음에도 높은 성능을 보임을 강조하였는데, 그럼에도 ViT-L/16의 학습에 8 코어 TPUv3로 30일이 걸렸다고 한다.
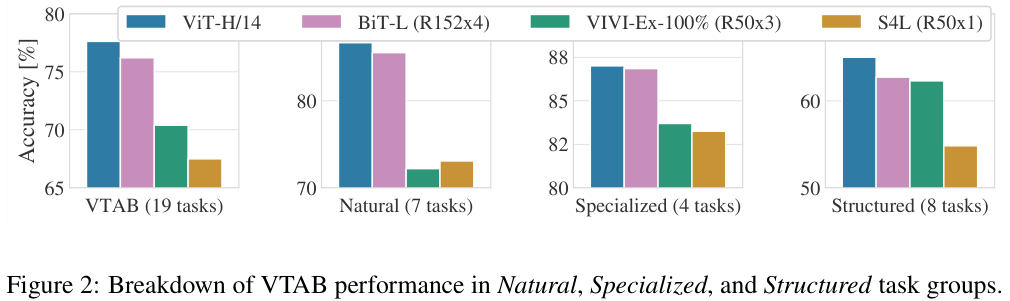
저자들은 여러 종류의 task에서 ViT와 다른 모델들의 성능을 비교했다. Natural은 CIFAR와 같은 일반적인 task, Specialized는 의료 영상이나 위성 영상 같은 task, Structured는 localization과 같이 geometric 한 정보를 요구하는 task이다. specialized에서는 ViT와 다른 모델이 유사한 성능을 보였으나 나머지에서는 더 높은 성능을 보였다.
Pre-training Data Requirements
앞서 언급한 것처럼, ViT는 충분한 데이터의 양이 뒷밤침된다면 CNN(ResNet) 대비 더 적은 inductive bias를 가짐에도 더 좋은 성능을 보였다. 저자들은 학습 데이터의 양과 성능의 관계를 알아보기 위한 실험을 진행하였다.
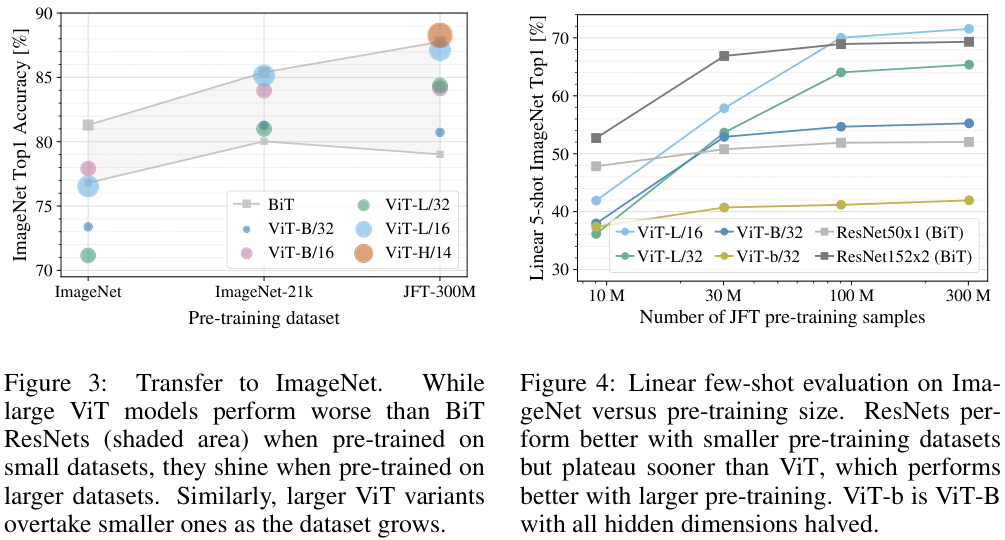
그림 3에서 볼 수 있는 것처럼, 사전학습에 사용하는 데이터가 증가함에 따라 처음에는 BiT(CNN)에 비해 확연히 낮은 정확도를 보이던 ViT가 성능이 향상되는 것을 확인할 수 있다. ImageNet-21k까지는 그럼에도 큰 BiT (두 BiT 차트 중 상단)가 ViT보다 조금 앞서는 성능을 보이는데, JFT-300M에서는 ViT가 앞선 성능을 보인다.
저자들은 그림 4에서 JFT-300M 데이터셋에서 일부 추출한 데이터로 사전학습한 모델들의 성능을 비교하였는데, 확실히 데이터의 양이 증가함에 따라 성능이 향상됨을 볼 수 있다. 특히 이 실험 결과에서, ViT-B/32가 ResNet50을 데이터의 양이 30M을 넘어가는 지점에서 급격히 앞서고 100M을 앞서면 상당히 앞서는 것을 볼 수 있는데, 이는 CNN이 가진 inductive bias가 작은 데이터셋에서 유용함을 보여준다.
Scaling Study
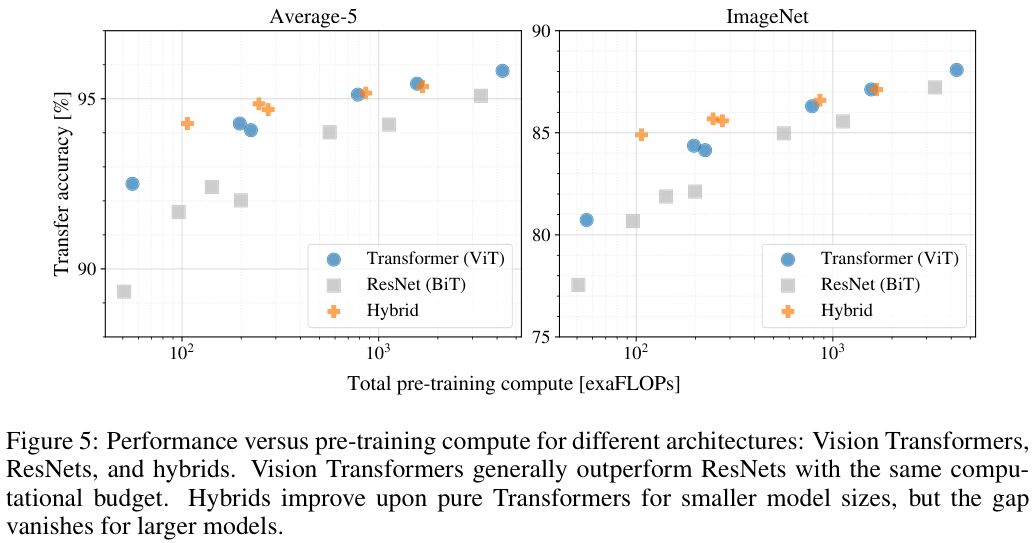
저자들은 JFT-300M에서의 전이학습 성능을 통해 사전학습에 요구되는 연산량 대비 성능의 변화를 실험하였다. 그 결과, ViT는 ResNet 대비 2-4배 적은 연산으로도 비슷한 성능을 낼 수 있음을 확인할 수 있었고, 하이브리드 방법은 연산량이 적을 때는 ViT를 앞서는 효율을 보였지만, 연산량이 증가함에 따라 ViT와 비슷하거나 부족한 모습을 보였다. 이는 합성곱이 무조건 ViT를 도울 것이라는 예측과는 달랐다고 한다. 마지막으로, ViT가 학습을 더 진행함에도 saturation이 발생하는 기미가 없었기에 모델의 추가적인 확장 가능성을 엿볼 수 있었다.
Inspecting Vision Transformer
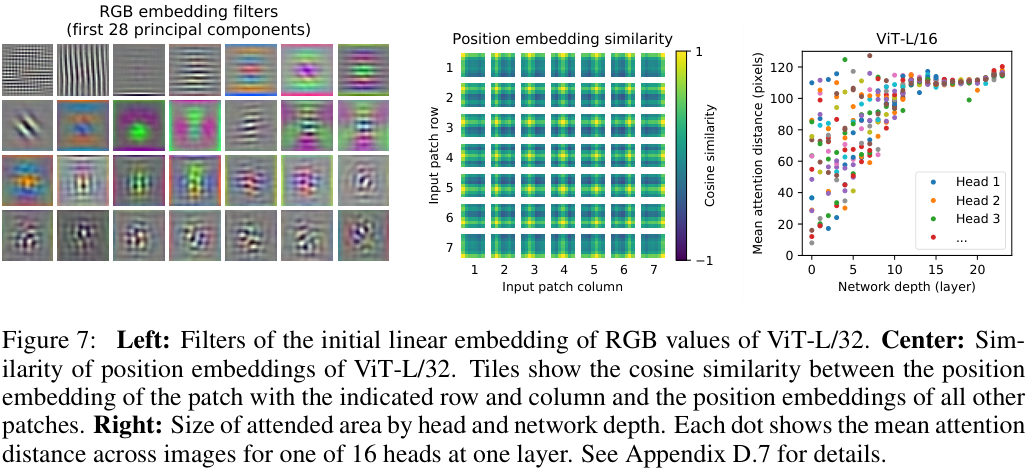
ViT가 이미지를 처리하는 과정을 더 잘 이해하기 위해, 저자들은 ViT 내부에서 일어나는 일을 분석해 보았다. ViT의 첫 계층은 패치들을 저차원 임베딩 공간으로 선형 투영하는데, 그림 7의 좌측을 보면 이렇게 학습된 embedding filter들의 상위 주성분(top principal components)들을 볼 수 있다. 각 성분들이 그럴듯한 형태를 형성함을 볼 수 있다.
투영 이후, 학습된 positional embedding이 패치에 더해진다. 그림 7의 중앙은 모델이 이미지들 사이의 거리나 관계를 파악하여 embedding을 형성한 모습을 확인할 수 있다. 가까운 패치들은 서로 비슷한 positional embedding을 갖는 것이다.

ViT는 셀프 어텐션을 통해 전체 이미지의 정보들을 통합한다. 그림 7의 우측에 나타난 것처럼, 어텐션 헤드들 중 일부는 낮은 계층에서부터 이미지 전체 영역의 정보를 통합한다. 신경망이 깊어짐에 따라, 어텐션 헤드들은 점차 전체적으로 넓은 영역의 픽셀들을 통합하는 경향이 있다. 이는 CNN의 합성곱과 유사한 방식으로 이미지의 특성을 학습하는 것으로 보인다. 이러한 과정을 거쳐 ViT는 최종적으로 이미지에서 중요한 맥락의 영역에 집중하게 된다. (그림 6)
Self-Supervision
NLP에서 트랜스포머의 성공의 배경에는 scalability 이외에도 대규모의 자기지도학습 기반 사전학습이 있었다. 저자들은 ViT에 대해서도 masked patch prediction을 통한 자기지도학습이 유용한지 확인하고자 BERT의 masked language modeling과 유사한 실험을 진행하였다. 그 결과, ViT-B/16에서 사전학습을 아예 하지 않은 모델 대비 2%의 성능 향상이 있었지만 지도학습 기반 사전학습 모델보다는 4% 성능이 부족한 모습을 보였다.
결론
저자들은 기존에 컴퓨터 비전에서 셀프 어텐션을 적용하고자 했던 다른 시도들과 달리, 이미지에 특화된 inductive bias(즉, 합성곱)를 신경 쓰지 않고 이미지를 패치 시퀀스로 해석하여 NLP에서 사용하였던 트랜스포머 모델에 입력하였다. 이러한 간단하고 scalable 한 방법은 놀랍도록 대규모 데이터셋에서 놀랍도록 잘 동작하였고, 트랜스포머의 scalability 덕분에 고성능의 대형 사전학습 모델을 사용할 수 있게 되었다.
오랜만에 백본 논문을 읽었는데, 우선 실험 파트의 깊이와 길이가 인상 깊었다. 이 논문은 인용구 이전까지의 9페이지 중 4-5 페이지가 모두 실험으로 구성되어 있는데, 이조차도 최대한 차트나 표를 Appendix로 빼고 글로 가득 차있었다. 처음에는 뭘 이렇게 실험을 많이 했을까 싶었는데, 단순히 성능을 찍어보고 끝난 것이 아니라 어찌 보면 당연한 모델의 유효성을 검증하는 실험부터, 데이터의 양에 따른 성능 변화, self-supervision의 가능성을 확인하는 실험 등 꼼꼼하게, 독자가 의문을 가질만한 부분은 대부분 커버하고 있다는 느낌이 들었다. 모델의 방법론 설명도 상당히 깔끔해서 잘 읽혔고, 역시 이게 구글인가 싶은 논문이었다.
한편, JFT-300M과 같은 in-house 데이터셋의 사용은 솔직히 좀 별로였다. ImageNet에서 사전학습할 때까지는 사실 CNN과 성능이 비슷하다가, JFT-300M에서 성능이 확 오르기도 하고, JFT-300M만을 가지고 실험한 결과도 많은데 재현은 해볼 수가 없으니... 극단적으로 이렇게 재현성 없는 걸 논문이라고 봐도 되나 싶다. 물론 시간이 지난 지금은 ViT의 성능에 의심의 여지가 없음은 다들 알지만...
아무튼 오늘 리뷰는 여기까지다.
읽어주셔서 감사합니다!