CLIP-VIP: Adapting Pre-Trained Image-Text Model to Video-Language Alignment 리뷰 [ICLR 2023]
대규모의 이미지와 텍스트 쌍에서 사전학습을 수행한 CLIP이 많은 image task에서 좋은 성능을 보임에 따라 CLIP을 video task에서도 활용하고자 하는 연구들이 많이 수행되었고, 몇몇은 좋은 결과를 보이기도 했습니다.
그러나 이러한 모델들은 이미지에서 학습된 CLIP을 그대로 사용하였기에, 비디오-텍스트 데이터를 이용한 추가 사전학습(post-pretraining)을 통해 비디오 도메인에 CLIP을 더 최적화하고자 하는 연구들이 수행되었는데요. 이러한 연구들은 어째서인지 그다지 좋은 결과를 보이지 못하였다고 합니다.
따라서 본 논문은 CLIP이 비디오-텍스트 데이터에서 post-pretraining을 잘하지 못하는 이유를 찾고, 이를 해결하고자 합니다. 저자들은 여러 실험을 통해, 데이터셋의 규모(scale)와 비디오-텍스트 데이터셋에서 language source 간의 domain gap이 성능에 큰 영향을 미치는 것을 발견하였는데요.
이러한 발견을 기반으로 video-text 에서의 post-pretraining을 위한 방법인 Omnisource Cross-modal Learning method equipped with a Video Proxy mechanism on the basis of CLIP, CLIP-ViP를 제안합니다. 이 방법을 통해 Text-Video Retrieval 성능이 크게 개선되었으며, SOTA를 달성할 수 있었다고 합니다.
Introduction
이미지-텍스트 도메인에서 학습된 CLIP을 비디오-텍스트에서 post-pretraining 할 수 있다면 video task에서의 fine-tuning에 요구되는 학습량을 줄이고 성능을 한층 개선할 수 있겠지만, 막상 이러한 시도들은 큰 성과를 보이지 못하고 있었습니다.
Howto100M에서 얻은 프레임들을 CLIP에 입력하여 얻은 frame-level feature를 MeanPooling 하여 video-level feature를 얻는 CLIP4Clip과 같은 방법들에서 이러한 시도가 있었지만, zero-shot이나 파인튜닝에서 이러한 방법의 성능은 오히려 image-text pre-train 모델을 그냥 사용하는 것에 비해 낮았다고 합니다.
본 논문에서는 image-text pre-training 모델은 video-language representation learning에 효과적으로 적용하는 방법을 연구합니다.먼저, video를 사용한 post-pretraining을 방해하는 요소들을 찾기 위한 사전 실험을 수행하여 데이터셋의 규모와 데이터 상의 language source 간의 domain gap이 문제임을 발견하였습니다. 이어서 이러한 문제를 해결하기 위한 CLIP-ViP 구조를 제안하였습니다.
CLIP-ViP 구조의 특징은 다음과 같습니다.
-
- 먼저, language domain gap을 최소화하기 위해 auxiliary caption을 사용합니다.
- 이를 위해 image captioning 모델을 통해 각 영상의 중간 프레임에 대한 caption을 생성하였습니다.
- ViT기반 이미지 인코더를 최소한으로 수정하면서도 영상에서도 잘 작동하도록 고안한 video proxy token과 proxy-guided video 어텐션 메카니즘을 사용합니다.
- 이를 통해 적당한 양의 파라미터와 계산량만 증가시키면서도 ViT의 generalization과 확장성을 증가시켰다고 합니다.
- caption-frame과 video-subtitle 데이터 간의 cross-modal representation learning을 잘 하기 위해 Omnisource Cross-modal Learning (OCL) 방법을 사용합니다.
본 논문의 contribution은 다음과 같습니다.
-
- video post-pretraining on pre-trained image-text model을 방해하는 요소를 찾은 첫 논문입니다.
- 위 요소들을 극복하며 효과적으로 학습을 수행할 수 있는 CLIP-ViP를 제안하였습니다.
- SOTA를 달성하였습니다.
Related Work
주로 이미지를 설명하는 대체 텍스트로 구성되는 image-text 데이터와 달리, video-text 데이터는 주로 자막(subtitle)으로 구성됩니다. 이때 대체 텍스트에 비해 자막에는 훨씬 많은 noise가 존재하게 됩니다. 구독, 좋아요 요청이나 영상과는 무관한 얘기가 있기도 하고, 영상과 자막이 다루는 내용이 시간적으로 다르기도 하죠.
본 논문에서는 이러한 video-subtitle 데이터들의 단점을 회피할 방법을 제안합니다.
Preliminary Analysis
저자들은 먼저 video-language post-pretraining의 결과가 좋지 않은 이유를 파악하기 위해 사전 실험을 진행합니다.
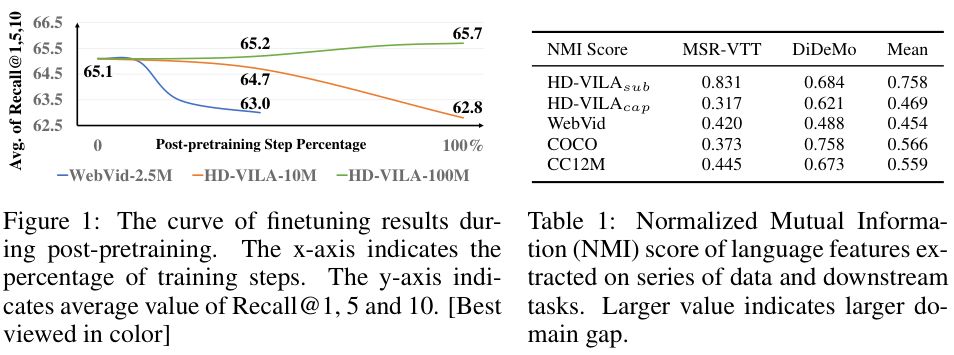
Post-Pretraining with Different Data Scales
먼저 저자들은 CLIP-ViT-B/32 모델을 baseline 삼아 CLIP4Clip과 frame-level feature 들의 Mean Pooling을 수행하는 방식으로 video-text 데이터셋에서의 post-pretraining을 수행하는 실험을 진행하였습니다. WebVid-2.5M과 HD-VILA-100M, HD-VILA-10M 데이터셋에서 실험을 진행하였고 post-pretraining 이후에 모델을 MSR-VTT에서 파인튜닝한 결과를 측정하였다고 합니다. 모든 실험에서 iteration은 HD-VILA-100M의 1 에포크와 맞췄으며 영상당 12 프레임을 추출해서 사용했습니다.
그림 1.에서 보이는 것처럼, post-pretraining이 오히려 성능을 감소시키는 경향이 있었으며 특히 크기가 작은 데이터셋에서 그러한 경향이 뚜렷했습니다. 한편 데이터셋의 크기가 큰 HD-VILA-100M에서는 조금이나마 성능이 개선되었는데, 이는 CLIP이 4억 개의 대규모 데이터에서 학습된 것에 비하여 post-pretraining 데이터가 적기 때문으로 보았습니다.
Language Domain Gap with Downstream Data
사전학습 데이터와 downstream 데이터가 같은 도메인인 것이 더 좋겠지만, 대부분의 Video-Text task에서 text가 영상을 설명하는 속성 (캡션 등)을 갖는 반면 본 논문에서 사전학습에 사용하는 HD-VILA-100M 데이터셋은 자동 생성된 자막을 사용하고 있습니다. 이로 인해 영상과의 무관성(irrelevance), 시간적 비정렬(misalignment), 자동 생성 오류(Automatic Speech Recognition Error)의 단점을 갖게 되는데요.
저자들은 이러한 사전학습 데이터와 downstream task 간의 language domain gap을 이해하기 위해, 두 language feature의 inconsistency를 계산해 보았습니다.
먼저, CLIP Text 인코더로 두 데이터셋의 텍스트 feature를 추출한 후, 사전학습 데이터와 downstream 데이터의 text feature를 합칩니다. 그다음, 합쳐진 feature들을 K-means로 두 개의 클러스터로 군집화했다. 마지막으로 클러스터링 된 라벨과 실제 두 데이터셋 라벨 간의 Normalized Mutual Information (NMI)를 구하였습니다. NMI가 크다는 것은 그만큼 두 종류의 feature가 쉽게 구분된다는 것이고, 이는 domain gap이 크다는 것이다.
각 비교별로 천 개의 텍스트를 각 데이터에서 뽑아서 수행하였으며 10번의 비교를 수행해 평균을 구했다고 합니다.
표 1. 을 보면 HD-VILAsub와 downstream 데이터의 NMI가 다른 것들에 비해 큰 것을 볼 수 있는데요, 이는 자막을 이용한 사전학습이 좋지 않을 수 있음을 시사합니다.
Approach
저자들은 이미지와 비디오 데이터셋 간의 language domain gap을 해결하기 위한 in-domain auxiliary data generation과 ViT가 이미지와 비디오 모두를 인코딩할 수 있도록 하는 Video Proxy 메커니즘, 비디오-텍스트와 이미지-텍스트 데이터로부터 cross-modal representation을 함께 학습할 수 있는 Cross-modal Learning (OCL) 방법을 포함한 CLIP-ViP video pre-training framework를 제안합니다.
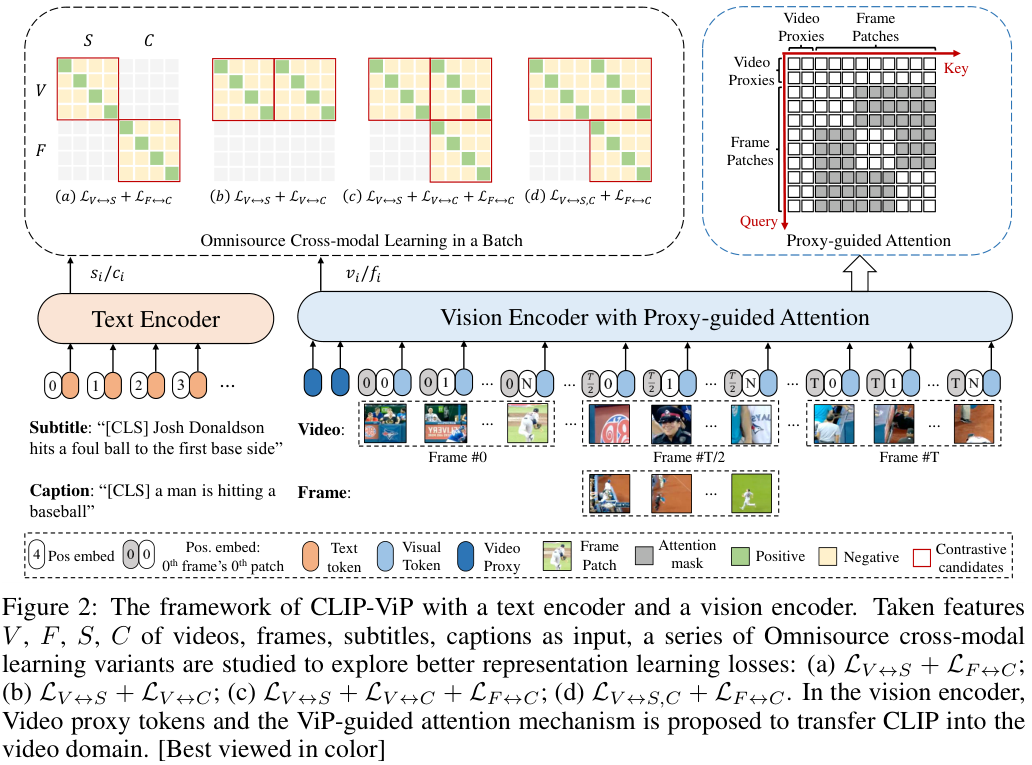
In-domain Auxiliary Data Generation
먼저, 사전학습 데이터와 downstream 데이터의 language domain gap을 줄이기 위해 auxiliary caption을 도입합니다. 앞서 설명한 것처럼, Video-Text 데이터셋들 중 일부는 비디오의 자막을 text로 사용하고, 어떤 데이터셋들은 영상을 소개하는 캡션을 text로 사용하여 domain gap 문제가 있었는데요. 이를 줄이기 위해 학습 영상에 대한 캡션을 생성하여 비디오-자막 데이터로 학습하여 생기는 domain gap 문제를 해결하고자 하였습니다.
저자들은 이때 video captioning 모델을 통해 영상에 대한 캡션을 생성하지 않고, 영상 중간에 위치한 프레임을 추출하여 image captioning 모델을 통해 캡션을 생성하였는데요. 그 이유는 다음과 같습니다.
1. 대부분의 SOTA 비디오 캡션 모델들은 video-text 데이터셋으로 학습되는데 이는 downstream task에도 사용되는 데이터셋이기에 data leaking 문제가 있습니다.
2. Video captioning 모델들은 이미지 캡션 모델 대비 성능이 한참 뒤처져 있다고 합니다.
저자들은 강력한 이미지 캡션 모델인 OFA-Caption을 통해 HD-VILA-100M 데이터셋의 각 영상의 중간 프레임에서 하나의 캡션들을 생성하였습니다. 이를 통해 최대 16 단어로 구성된 100M 개의 문장을 얻었으며, 이는 추후 연구를 위해 공개할 것이라 합니다..
Video Proxy Mechanism
CLIP을 video domain으로 transfer 시킬 때, 당연하게도 frame aggregation과 temporality를 학습하는 것이 매우 중요합니다. 저자들은 이러한 temporal modeling을 수행하면서도 동시에 기존 ViT 백본의 뛰어난 일반성과 확장성을 유지하기 위해 ViT를 최대한 수정하지 않으면서도 Video를 다룰 수 있도록 하는 단순하고 효과적인 Video Proxy Mechanism을 제안하였습니다.
먼저 $T$개의 프레임을 가진 영상 $\{f_1, f_2, \cdots , f_T\}$이 주어질 때, CLIP을 따라 각 프레임을 $N$개의 패치로 나누어 줍니다. $\{ f_t^1, f_t^2, \cdots, f_t^N | t\in [1, T] \}$. 그다음, 평탄화된 2D 패치들에 spatio-temporal positional embedding을 더합니다.
$$ g(f_t^n) = Linear(f_t^n) + Pos_s(n) + Pos_t(t)$$
$Linear(*)$는 선형 계층이고, $Pos_s(n), Pos_t(t)$는 각각 학습 가능한 spatial, temporal positional embedding입니다. 이렇게 영상 하나는 $T\times N$ 크기의 패치 토큰으로 분할됩니다.
영상의 각 패치들의 시공간적 정보를 모델링하는 가장 단순한 방법은 모든 토큰을 한 번에 CLIP vision encoder에 입력하고 전체 토큰에 대한 어텐션을 수행하는 것이겠지만, CLIP이 이미지에서 학습되었기 때문에 이는 좋은 방법이 아니라고 합니다. (아래 표 2. 에서 비교를 수행하였습니다.) 때문에 저자들은 패치들이 기본적으로는 Image에서 그랬던 것처럼 spatial 한 정보들을 주고받되, 추가적인 Video Proxy token을 통해 각 프레임들이 temporal 정보를 주고받을 수 있게 하였습니다.
각 프레임을 CLIP에 입력하기 앞서, 학습 가능한 video proxy tokens $ \mathcal P=\{p_1, p_2, \cdots, p_M\}$을 패치 토큰에 붙여줍니다. 이때, $M$은 proxy token의 개수입니다. 이로써 $T\times N+M$ 개의 토큰이 CLIP의 ViT로 입력되게 되는데요, 이때 맨 첫 번째 proxy token의 출력은 영상 전체의 representation으로 간주합니다.
어텐션 연산 과정에서, 각 패치 토큰들은 같은 프레임에 속한 토큰들에만 어텐션을 수행할 수 있도록 어텐션 마스크 $\mathcal M_{ViP}$로 마스킹됩니다. 그러나 video proxy token들은 모든 토큰들에 어텐션을 수행할 수 있기 때문에, 모델은 기본적으로 이미지를 다루는 ViT처럼 동작하되 일부 proxy token을 통해 temporal 한 정보 역시 다룰 수 있게 됩니다. 저자들은 이를 proxy-guided attention이라 합니다.
$$ \mathcal V_{ViP}(q, k) = \begin{cases} 1 & \mbox{if } q\in \mathcal P \mbox{ or } k\in \mathcal P \mbox{ or } (q, k) \text{ in the same frame.} \\ 0 & \text{otherwise,} \end{cases}$$
$q, k$은 어텐션의 쿼리와 키입니다. 이러한 구조를 통해, patch token은 video proxy token들로부터 global information을 얻을 수 있으며 동시에 CLIP의 원래 연산 구조를 보존할 수 있습니다.
이 모델은 입력이 이미지 즉, 프레임일 경우 linear interpolation을 통해 중간 temporal positional embedding을 얻어, 이미지를 1 프레임짜리 영상으로 취급합니다. 이를 통해 비디오와 이미지를 같은 배치에서 학습할 수 있다. 이렇듯 proxy-guided 어텐션 구조는 비디오와 이미지 연산의 차이를 줄이는 역할을 합니다.
Omnisource Cross-Modal Learning
video-subtitle 쌍으로부터 풍부한 video-language 정렬을 얻은 후 language domain gap을 최소화하기 위해 Joint Cross-Modal Learning on the omnisource input을 도입합니다. 두 인코더를 사용한 multimodal alignment 연구가 대부분 그러하듯 저자들도 InfoNCE Loss를 통한 contrastive learning을 수행합니다.
CLIP-ViP의 visual source로는 video sequence와 single frame 두 종류가 주어지고 text source로는 자막과 캡션이 주어집니다. 이를 각각 $V,F,S,C$로 표현하겠습니다. 이때, source-wise InfoNCE는 다음과 같습니다.
$$\mathcal L_{v2t} = -\frac{1}{B}\sum^B_{i=1}\log\frac{e^{v_i^\top t_i /\tau}}{\sum^B_{j=1} e^{v_i^\top t_j / \tau}}, \mathcal L_{t2v} = -\frac{1}{B}\sum^B_{i=1}\log\frac{e^{t_i^\top v_i / \tau}}{\sum^B_{j=1} e^{t^\top _i v_j / \tau}}$$
$v_i, t_j$가 각각 $X\in \{V, F\}$의 $i$번째 visual feature와 $Y\in \{S, C\}$의 $j$번째 text feature의 normalized embedding이고, 배치 크기가 $B$이며, $\tau$는 학습 가능한 temperature입니다.
overall alignment loss $\mathcal L_{X\leftrightarrow Y}$는 $\mathcal L_{v2t}$과 $\mathcal L_{t2v}$의 평균입니다. 예를 들어, $\mathcal L_{V\leftrightarrow S}$은 배치에 포함된 비디오와 자막 쌍의 InfoNCE loss이 됩니다. 아시다시피 이러한 InfoNCE loss는 aligned pair는 가까이, misaligned pair는 멀리 밀어냅니다.
저자들은 이러한 Overall alignment Loss들의 다양한 변형들을 사용해 학습을 진행해 보았습니다. 앞서 설명한 비디오와 자막에 대한 $\mathcal L_{V\leftrightarrow S}$에 이어, (1) 비디오-자막, 프레임-캡션의 단순한 조합인 $\mathcal L_{V\leftrightarrow S} + \mathcal L_{F\leftrightarrow C}$, (2) 비디오와 자막과 비디오와 캡션의 조합인 $\mathcal L_{V\leftrightarrow S} + \mathcal L_{V\leftrightarrow C}$, (3) 비디오-자막과 비디오-캡션, 여기에 프레임-캡션까지 더한 $\mathcal L_{V\leftrightarrow S} + \mathcal L_{V\leftrightarrow C} + \mathcal L_{F\leftrightarrow C}$, (4) 비디오와 자막, 캡션 그리고 프레임과 캡션의 조합인 $\mathcal L_{V\leftrightarrow S,C} + \mathcal L_{F\leftrightarrow C}$까지를 실험 하였는데요. 이때, (4)는 (3)과 비교하여 $\mathcal L_{v2t}$의 negative pair가 늘어난 효과가 있습니다. 이러한 Loss 중, $\mathcal L_{V\leftrightarrow S,C}$에 포함된 $\mathcal L_{v2t}$는 다음과 같이 정의됩니다.
$$\mathcal L_{v2t} = -\frac{1}{2B}\sum^B_{i=1}(\log\frac{e^{v_i^\top s_i / \tau}}{\sum^B_{j=1} e^{v_i^\top s_j / \tau}+e^{v_i^\top c_{j=i}/\tau}} + \log\frac{e^{v_i^\top c_i /tau}}{\sum^B_{j=1} e^{v_i^\top c_j /\tau}+ e^{v_i^\top s_{j\neq i}/\tau}})$$
$s_i\in S, c_i\in C$입니다.. $\mathcal L_{V\leftrightarrow S,C}$안의 $\mathcal L_{t2v}$는 (3)과 같습니다. 저자들은 이러한 변종들을 기본 baseline $\mathcal L_{V\leftrightarrow S}$과 비교하였습니다.
Experiment
저자들은 먼저 CLIP-ViP를 사전학습하기 위해 평균 13.4초 길이의 영상 클립들로부터 uniform 하게 12 프레임을 추출한 후, $224\times 224$ 크기로 조정하였습니다. 텍스트는 CLIP 토크나이저를 통해 텍스트를 최대 70 길이의 토큰들로 변환하여 사용하였습니다. 학습은 AdamW에 initial learning rate $5e-6$, fixed weight decay $5e-2$를 사용했고, learning rate를 consine decay로 점차 감소시켰습니다. 학습은 1024 배치 사이즈에서 32장의 Tesla V100으로 진행했고, contrastive smilarity는 모든 GPU에서 생성된 feature에 대하여 계산하였습니다. ablation study는 HD-VILA-100M 데이터셋에서 1 에포크 학습하여 진행하였고, 최종 결과는 3 에포크 학습한 결과를 사용했다고 합니다.
downstream task에서의 파인튜닝 시에는 대부분의 하이퍼 파라미터를 사전학습과 동일하게 가져갔으나, 일부 예외가 있기는 했습니다. 배치 크기는 모든 downstream task에서 128로 하였고, Learning rate와 weight decay는 $1e-6$, $0.2$를 사용했다고 합니다. 학습은 데이터셋 별로 다르게 진행하였는데 MSR-VTT, DiDeMo, LSMDC, ActivityNet에서 각각 5, 20, 10, 20으로 하였습니다. 추출 프레임은 영상의 길이가 긴 ActivityNet Caption만 32로 하고, 나머지 데이터셋에서는 사전학습과 동일하게 12 프레임으로 했습니다.
Ablation Study

Video Proxy Mechanism. 저자들은 MSR-VTT VTT retrieval에서 비전 인코더에 저자들이 제안한 Video Proxy (ViP) 적용 시 video proxy token의 수에 따른 차이와 ViP 외의 모델 구조를 사용 시 성능 차이를 실험해 보았습니다. MeanPool은 전체 영상의 frame feature들에 단순히 평균을 구하는 방식이며, SeqTransformer는 CLIP4Clip의 seqTransf 형식을 사용한 결과입니다. Full Attention은 ViP와 달리 모든 패치들이 다른 프레임의 패치를 포함한 모든 패치들에게 어텐션을 수행할 수 있는 설정이라고 하는데, 성능이 가장 낮은 것이 저자들이 제안하는 구조에 설득력을 더해주는 것 같네요.
결과를 보면, 시간적 구조를 거의 완전히 무시하는 MeanPool 방식 대비 SeqTransformer가 약간 향상된 결과를 보이며, Full Attention은 성능이 오히려 떨어지는 모습을 보이고 있습니다. ViP는 모든 설정에서 Mean Pooling과 SeqTransformer 봐 좋은 결과를 보이는데 특히 4개의 proxy를 사용하는 것이 좋은 결과를 보이고 있네요.
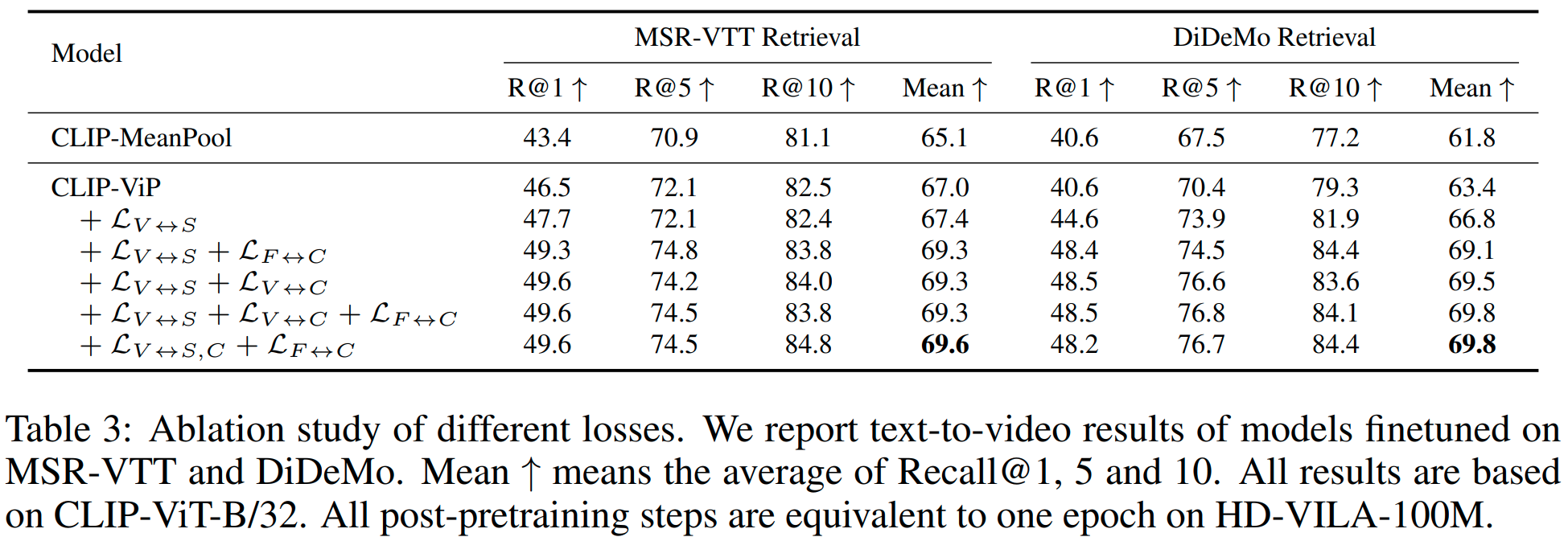
Omnisource Cross-modal Learning. 저자들은 제안한 OCL의 효과를 검증하기 위한 비교를 수행하였습니다. 먼저 기본적인 $\mathcal L_{V\leftrightarrow S}$만 사용한 경우에도 성능이 향상되었고, 여러 가지 OCL 변형을 사용함에 따라 성능이 향상되다가, $\mathcal L_{V\leftrightarrow S,C}, \mathcal L_{F\leftrightarrow C}$를 사용한 경우 성능이 가장 좋았습니다. 당연하게도, 가장 성능이 좋은 해당 손실함수를 최종 결과에 사용하였다고 합니다.
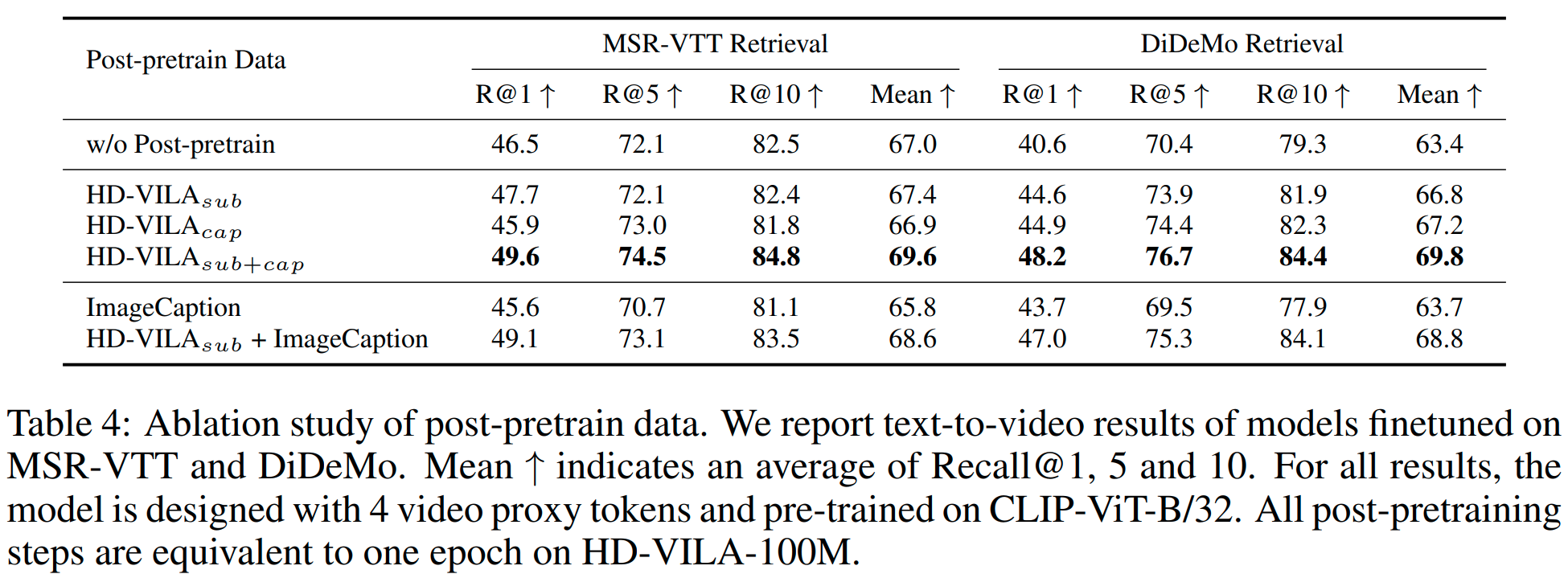
Auxiliary Data. 저자들은 이미지 데이터셋에서 사전학습된 CLIP을 비디오 데이터셋에서 추가 사전학습시켜 성능을 향상했습니다. 여기서는 이에 따른 성능 증가와 사용하는 데이터에 따른 성능 변화를 분석하였습니다. 먼저, HD-VILA 데이터셋에서 자막(sub)이나 캡션(cap)만을 사용한 uni-source 결과보다, 두 텍스트를 모두 사용한 omnisource 학습 시의 성능이 훨씬 크게 향상되었습니다. 또한, 학습 시에 MS-COCO, Visual Genome, Flickr-30K, SBU, CC3M, CC12M과 같은 이미지 데이터셋에서 OFA-Caption을 통해 캡션을 생성 후 이를 학습에 사용한 ImageCaption과 여기에 비디오 데이터인 HD-VILAsub를 추가로 사용한 결과를 보았는데, ImageCaption 만을 사용한 경우 오히려 추가 사전학습을 하지 않은 CLIP보다 성능이 감소했지만, HD-VILA에 이를 더하여 사용하자 성능이 개선되었습니다. 이러한 ImageCaption 데이터가 noisy 한 대규모 HD-VILA 데이터셋의 noise를 일부 완화해 주는 것으로 보인다고 합니다. 신기하네요.
Comparison to SOTA
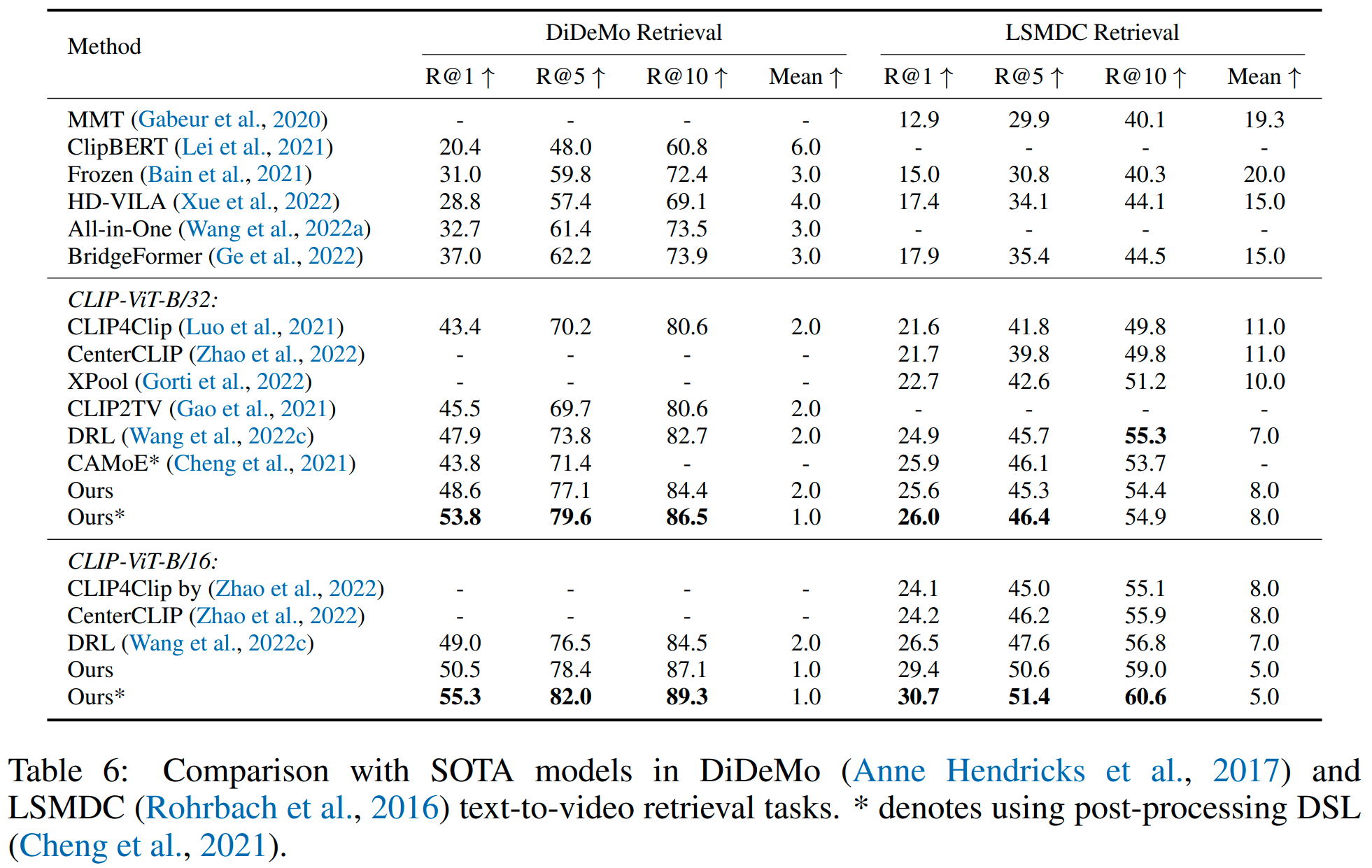
저자들은 제안한 CLIP-ViP와 기존 모델들의 DiDeMo, LSMDC Text-to-Video Retrieval 성능을 비교하였습니다. (이때, 파인튜닝은 MSR-VTT, DiDeMo, ActivityNet Captions, LSMDC에서 진행됐다고 합니다.) CLIP-ViP는 CLIP-ViT-B/32와 CLIP-ViT-B/16 기반 모델 중 SOTA를 달성하였으며, 일부 기존 방법들을 CLIP-ViP에 추가한다면 추가적인 성능향상도 기대할 수 있다고 합니다.
Conclusion
이 논문에서 저자들은 image-text에서 사전학습된 CLIP 모델을 대규모의 비디오 데이터를 통해 추가 사전학습(post pre-training)하는 방법을 제안했습니다. 저자들은 본격적인 연구에 앞서 비디오 데이터를 통한 추가 사전학습이 잘 되지 않는 이유를 탐색하였고, 이를 기반으로 Omnisource Cross-modal Learning과 Video Proxy 기법을 이용한 CLIP-ViP를 제안하였습니다. CLIP-ViP는 CLIP이 사전학습한 정보와 모델 구조를 최대한 보존하면서도, downstream task에 사용할 비디오와 자막(subtitle) 혹은 캡션(caption) 데이터와의 domain gap을 줄여 SOTA를 달성할 수 있었습니다.
CLIP을 비디오에 맞게 일부 수정한 모델이라 가볍게 생각하고 읽었는데, 생각보다 어려우면서도 기발한 아이디어들이 많은 논문이었습니다. 단순히 모델에 이것저것 붙여보고 잘된 거 들고 온 논문이 아니라, 사전에 세심하게 video domain에서의 post pretraining이 잘 안 되는 이유를 분석한 점에서 연구가 체계적이라는 생각이 들었습니다.
저자들이 제안한 Video Proxy mechanism의 경우 CLIP이 아니더라도 사전학습된 이미지 기반 트랜스포머를 비디오에서 추가 학습 시킬 때 응용하면 유용할 것으로 생각되며, OCL과 같이 domain gap을 줄이기 위한 loss도 언젠가 써먹을 수 있을 것 같아 얻은 게 많은 논문입니다.