Clover : Towards A Unified Video-Language Alignment and Fusion Model 리뷰 [CVPR 2023]
이번 논문은 V-T Retrieval과 VQA 두 downstream task에서 모두 좋은 성능을 보이며, 동시에 효율적인 Universal Video-Language pre-training 방법을 제안한 Clover입니다.
Video-Text / Text-Video Retrieval과 Video Question Answering(VQA)과 같은 Video-Language Understanding task을 잘 풀기 위해 대규모 비디오-텍스트 쌍 데이터셋에서 사전학습한 모델을 만들고자 하는 연구가 최근 몇 년간 활발히 진행되어 왔는데요. 이때, 각 downstream task가 요구하는 feature의 차이로 인해 특정 task에 강한 모델은 비교적 쉽게 만들 수 있었지만, 여러 downstream task를 모두 잘 수행하는 general 한 모델을 만드는 것은 어려운 일이었습니다.
Video-Text / Text-Video Retrieval에 사용된 모델들은 대게 별도의 단일 모달(uni-modal) 인코더를 통해 비디오와 텍스트를 각각의 representation으로 만들고, 같은 맥락적 정보(semantic information)를 가진 비디오와 텍스트에 대하여 두 인코더가 생성한 representation이 유사해지도록 contrastive learning을 통해 학습시켰습니다.
한편, Video Question Answering에 사용된 모델들은 비디오와 텍스트로부터 각각의 인코더를 통해 feature를 추출한 후, 이들을 멀티 모달 인코더에 입력하여 융합한 representation을 사용하였습니다. 이러한 멀티 모달 인코더는 Masked Language Modeling이나 Visual-Text Matching과 같은 pre-training task로 token-level cross modal fusion을 학습하였습니다.
ActBert, clipBert, VIOLET, ALPRO와 같은 일부 연구들은 이러한 백본 모델의 구조적 차이 없이 두 downstream task를 모두 수행할 수 있도록 하기 위하여 VQA에서 사용한 모델과 같이 멀티 모달 representation을 얻은 후, 이를 통해 영상과 텍스트의 유사도를 이진 분류 형식으로 얻어 Retrieval task도 수행하고자 하였는데요. 이러한 방식은 각각의 단일 모달 인코더를 통한 Retrieval이 $N$개의 텍스트와 $M$개의 비디오를 갖는 Retrieval 문제에서 $O(N+M)$의 복잡도를 갖는 반면, $O(NM)$의 복잡도를 가져 매우 큰 컴퓨팅 오버로드를 야기했습니다. (추가로 실제 적용을 고려해 보면, 앞선 방법은 검색 대상이 될 데이터베이스의 영상들의 feature를 미리 추출해 놓으면 $O(1)$의 복잡도 달성이 가능하지만, 멀티 모달 방법은 $O(NM)$ 연산을 매 검색 시 수행해야 합니다.)
HERO와 VLM과 같은 연구는 task-agnostic한 백본 모델을 설계하여 이러한 문제를 해결하고자 했으나 여전히 video feature를 사전에 추출해 놓아야 한다거나, end-to-end 학습이 불가능한 한계가 존재했습니다.
저자들이 제안한 Clover는 end-to-end 학습이 가능하며, 앞서 언급한 downstream task에 모두 적용이 가능하면서도 효율적이고, 성능이 좋은 사전학습 방법론입니다. 본 모델은 3개의 Retrieval task와 8개의 VQA task에서 꽤 큰 차이로 SOTA를 달성하였는데, 저자들은 다만 최근 V-L Understanding 분야에서 좋은 성과를 보이고 있는 CLIP을 적용하는 모델들과는 약간 거리를 두는데, Clover가 4억 개의 데이터를 사용하는 CLIP에 비해 적은 5백만 개의 데이터로 학습하기 때문에 효율적이라고 강조하고 있습니다. 찾아보니 CLIP 기반 방법들에 비해서는 성능이 확실히 낮네요.
Introduction
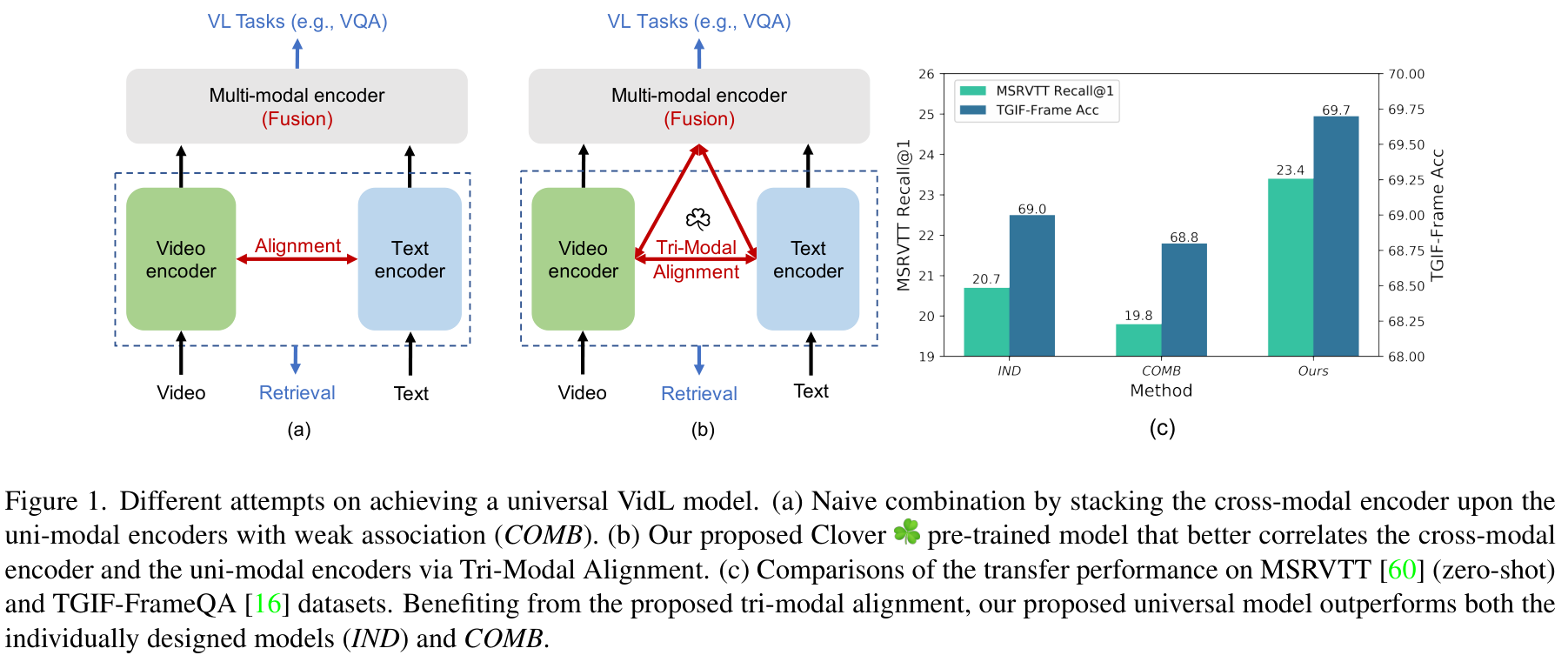
저자들은 먼저 Retrieval task나 VQA task에 특화되어 설계된 IND 모델들과, 나이브하게 단일 모달 인코더 위에 멀티 모달 인코더를 쌓은 후, 단일 모달 인코더가 생성한 representation은 Retrieval에, 멀티 모달 인코더가 생성한 representation은 VQA에 사용하는 COMB 방식(그림 1. 의 (a))의 모델의 성능을 비교하였습니다.
그림 1.의 (c)를 보면, 각 task에 특화된 IND 방식에 비해 Retrieval과 VQA 성능이 모두 하락한 것을 확인할 수 있는데요, (b)에 나타난 Clover 모델의 경우 두 task 모두에서 성능이 향상된 것을 확인할 수 있습니다.
저자들은 이러한 Universal VidL 사전학습 모델을 만듦에 있어 비디오와 텍스트 간의 feature alignment와 두 모달의 feature를 통합된 representation으로 잘 융합하는 것이 중요하다는 관측을 기반으로 저자들이 개발한 방법을 Correlated Video-Language pre-training (Clover)이라 명명하였습니다.
Clover는 비디오와 텍스트의 representation 뿐 아니라 이들이 융합된 멀티 모달 representation도 함께 align 하는 Tri-Modal Alignment (TMA)를 도입합니다. 이를 통해 멀티 모달 representation은 비디오와 텍스트 두 모달과 동시에 정렬되는데요. 때문에 비디오와 텍스트에 공통적으로 존재하는 일관된 맥락적 정보를 담게 됩니다. 한편, 비디오와 텍스트 representation 역시 이러한 멀티 모달 representation과 정렬되는 과정에서 멀티 모달 representation을 기준 삼아 더 잘 정렬되게 됩니다. 이러한 TMA는 기존의 pre-training task들 (Masked Language Modeling 등)과 합치기에 용이하며, 컴퓨팅 오버헤드도 무시할 만합니다.
추가로 모델이 VQA에서 특히 중요한 generalizability를 향상하면서도 Retrieval에 필요한 fine-grained discriminative capability를 유지하도록 하기 위하여 모델이 masked sample과 original sample 사이의 디테일한 정보 차이에 주의하도록 하는 pair-wise ranking loss를 제안합니다.
저자들은 세 개의 retrieval task (zero-shot과 fine-tune)와 8개의 VQA task에서 실험을 진행하여 SOTA를 달성하여 Clover가 cross-modal fusion과 alignment 성능을 상호적으로 향상할 수 있음을 확인하였습니다. 저자들의 Contribution을 요약하면 다음과 같습니다.
- 고성능, 고효율로 Video-Text feature alignment와 fusion을 수행하여 다양한 video understanding task에 전이 가능한 통합된 사전학습 방법인 Clover 개발
- 멀티 모달 인코더와 단일 모달 인코더가 상호 향상하도록 하는 Tri-modal alignment pre-training task 제안
Method
Motivation and Overview
V-L pre-training에 있어 중요한 요소는 cross-modal alignment와 융합을 효율적으로 하는 것입니다. Cross-modal alignment는 각각 비디오와 텍스트를 투영하는 투영 함수 $f(\cdot)$와 $g(\cdot)$가 서로 의미론적으로 유사하고 일관된 데이터 간에는 유사도를 최대화하고 그렇지 않은 경우 최소화할 수 있는 공통 임베딩 공간으로 데이터를 투영할 수 있도록 하는 것을 의미합니다. 비디오 $V$를 기준으로, cross-modal alignment의 학습 목표를 식으로 나타내면 다음과 같이 나타낼 수 있습니다.
$$ \arg \max_{f, g} [s(f(V), g(T^+)) - s(f(V), g(T^-))] $$
이때, $T^+, T^-$는 각각 $V$와 의미론적으로 일관된(consistent) 텍스트와 그렇지 않은 텍스트이고, $s(\cdot, \cdot)$는 두 임베딩의 유사도를 계산하는 함수입니다. 이러한 cross-modal alignment는 특히 의미론적으로 잘 정렬된 비디오와 텍스트 representation을 요구하는 video-retrieval task에서 특히 중요합니다.
한편, Cross-modal fusion은 비디오와 텍스트 간의 상호관계를 통합된 멀티 모달 임베딩으로 만드는 것을 의미합니다. 이는 각기 다른 모달로부터 입력을 받아 통합된 representation을 출력하는 함수 $M=\text{Fusion}(\cdot, \cdot)$과 같이 정의할 수 있으며, VQA와 같은 downstream task에서 활용됩니다.
기존의 사전 학습 전략들은 간단한 지도학습이나 contrastive pre-text task에 의존하여 feature alignment와 fusion을 학습하였으나, cross-modal alignment와 fusion을 더 잘 수행하기 위해서 저자들은 Correlated Video-Language pre-training method (Clover)를 제안합니다. Clover는 세 가지의 pre-training innovations로 정의되는데, tri-modal alignment, pair-wise ranking loss, semantic enhanced masked language modeling입니다. 마지막 요소를 보면, 고전적인 masked language modeling task (MLM) 역시 본 모델에 통합한 것을 알 수 있는데, 저자들은 MLM을 개선하여 적용함으로써 모델의 visual과 language간의 상호 관계뿐 아니라 일반화 성능도 향상할 수 있었다고 합니다.
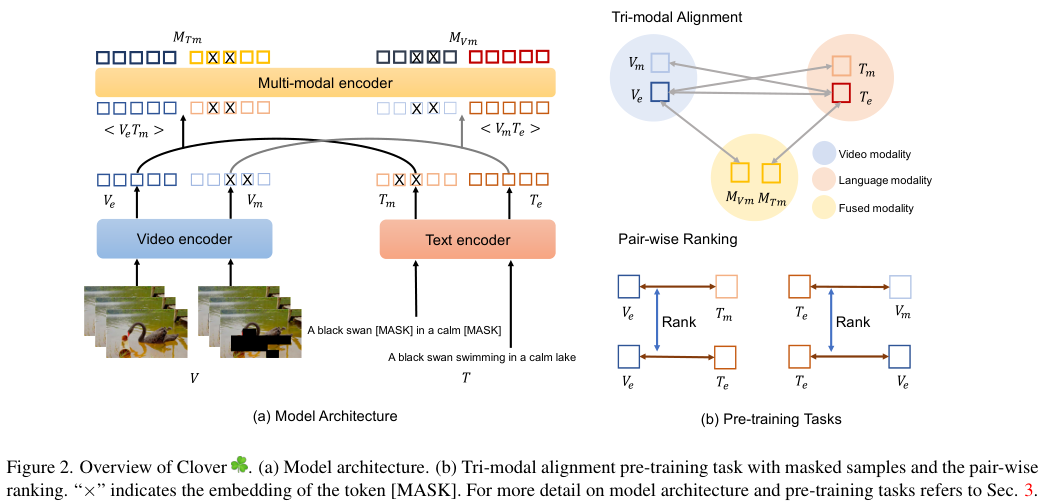
Architecture. Clover는 비디오 인코더, 텍스트 인코더, 멀티 모달 인코더로 구성됩니다. Violet과 같이 저자들은 VideoSwinTransformer를 비디오 인코더로 사용하였는데, 입력 비디오 $V$가 주어질 때 인코더는 $V_e = \{v_1, \cdots, v_K\} \subset \mathbb R^D$를 출력하는 구조입니다. 이때, $K$는 flatten된 패치의 수입니다. 텍스트 인코더는 12층의 양방향 트랜스포머 인코더 모델(BERT)로, 입력 텍스트 시퀀스 $T$를 $T_e = \{t_{cls}, t_1, \cdots , t_{L-1}\}\subset \mathbb R^D$로 변환합니다. 이때, $t_{cls}$는 [CLS] 토큰의 임베딩입니다. video-text 쌍의 cross-modal representation을 융합하는 멀티 모달 인코더는 3계층 양방향 트랜스포머 인코더를 사용하였는데, 이 모델은 비디오와 텍스트 임베딩을 concatenate 하여 입력받고, 융합된 멀티모달 임베딩 $M_e = \{m_{v_1}, \cdots, m_{v_K}, m_{cls}, c_{t_1}\cdots , m_{t_{L-1}}\}$을 출력합니다.
Tri-Modal Alignment
현존하는 VidL 사전학습 모델들은 pair-wise contrastive learning을 통해 모달리티 간의 임베딩을 align하는 반면, Clover는 Tri-Modal Alignment (TMA)를 통해 비디오와 텍스트 모달리티 뿐 아니라 그들의 퓨전 모달리티까지 align 합니다.
먼저, 그림 2. (a)와 같이 비디오와 텍스트 쌍 $<V, T>$와 임베딩 $<V_e, T_e>$가 주어질 때, 비디오의 일부를 마스킹하여 $V_m$을 만들고 텍스트도 마스킹하여 $T_m$을 만들어 줍니다. 그다음, 마스킹된 샘플과 그렇지 않은 샘플의 쌍을 $<V_m, T_e>, <V_e, T_m>$과 같이 구성하고, 멀티 모달 인코더에 이 쌍을 입력하여 $M_{V_m}$과 $M_{T_m}$을 각각 만들게 하고, 이들의 [CLS] 토큰 임베딩을 $M_{V_mf}, M_{T_mf}$와 같이 나타냅니다.
$i, j$를 각 데이터 샘플의 인덱스로 사용하겠습니다. 비디오 representation $V_e^i$와 대응되는 텍스트 임베딩 $T_e^i, T_m^i$, 융합된 임베딩 $M_{V_mf}^i$를 positive pair로 정의하여 총 3가지 모달과의 representation을 align 하기 위해 저자들은 새로운 exclusive NCE loss를 제안하여 사용합니다. ($B$는 배치 사이즈, $\tau$는 temperature 값, $s(\cdot, \cdot)$는 닷 연산 기반의 유사도 함수를 의미합니다.)
$$ L_v = - \sum^B_{i=1}[\log\frac{e^{s(V_e^i, T_e^i)}/\tau}{e^{s(V_e^i, M_e^i)/\tau}+Z} + \log\frac{e^{s(V_e^i, T_m^i)/\tau}}{e^{s(V_e^i, T_m^i)/\tau}+Z} + \log\frac{e^{s(V_e^i, M_{V_mf}^i)/\tau}}{e^{s(V_e^i, M_{V_mf}^i)/\tau} + Z} ], \text{where} \\
Z = \sum^B_{j\neq i}[e^{s(V_e^i, T_e^j)/\tau} + e^{s(V_e^i, T_m^j)/\tau} + e^{s(V_e^i, M_{V_mf}^j)/\tau}]$$
$V_e^i$와 $T_e^i, T_m^i, M_{V_mf}^i$의 representation을 유사하게 만드는 일반적인 InfoNCE Loss에서 맞추고자 하는 모달리티와 다른 모달리티들과 관련된 항들이 분모에 추가된 모습인데요. 이를 통해 align 하고자 하는 모달, 예를 들어 첫 번째 항에서 $V_e^i, T_e^i$를 가깝게 만들면서 $T_e, T_m, M_{V_mf}$ 중 positive pair에 속하지 않는 샘플들은 멀어지도록 만드는 것이라고 합니다.
이어서 다른 모달리티 없이 맞추고자 하는 모달리티들만 사용한 align도 진행해 줍니다.
$$L_{v'} = -\sum^B_{i=1}[\log\frac{e^{s(T_e^i, V_e^i)/\tau}}{\sum^B_{j=1}e^{s(T_e^i, V_e^j)/\tau}} + \log\frac{e^{s(T_m^i, V_e^i)/\tau}}{\sum^B_{j=1}e^{s(T_m^i, V_e^j)/\tau}} + \log\frac{e^{s(M_{V_mf}^i, V_e^i)/\tau}}{\sum^B_{j=1}e^{s(M_{V_mf}^i, V_e^j)/\tau}}] $$
위 두 식을 더하여 비디오에 대한 $L_V = L_v + L_{v'}$를 정의해 줍니다. 같은 방식으로 텍스트에 대한 손실 함수 $L_T = L_t + L_{T'}$도 정의하고, 최종적인 tri-modal alignment 목적 함수 $L_{TmA} = L_V + L_T$를 정의한다고 합니다.
한편, 이 과정에서 마스킹은 아래와 같이 진행하였습니다.
Video-block masking strategy. 비디오에 등장하는 물체는 대게 연속되는 프레임에서 유사한 위치에 존재하여, 시공간적 관점에서 튜브를 형성합니다. 따라서 비디오를 masking 할 때, information leakage를 막기 위하여 block-wise masking을 통해 비디오 속 모든 프레임에서 같은 위치들을 마스킹하였습니다. 저자들은 랜덤한 20%의 패치를 학습 가능한 마스크 토큰으로 변환하였다고 합니다. 학습 가능한 마스킹 토큰도 특이하네요.

Semantic text masking strategy. 텍스트에 포함된 디테일한 맥락 정보는 대체로 동사와 명사에 존재합니다. 이러한 representation을 잘 학습하도록 하기 위해, 저자들은 동사와 명사, 형용사를 랜덤하게 마스킹하였습니다. 구체적으로, part-of-speech tagger를 통해 각 단어를 태그 하고, 동사구와 명사들을 선정하여 30%를 [MASK] 토큰으로 대체하였다고 합니다. 단, 의미가 너무 크게 변화하는 것을 막기 위해, have, should, will, would와 같은 일부 동사들은 마스킹하지 않았다고 합니다. 마스킹을 통해 텍스트는 디테일한 정보가 아닌 부분적인 정보를 가지게 됩니다.
Training Objective
Pair-wise ranking. TMA에서 마스크 된 페어 $<V_e, T_m>, <V_m, T_e>$를 positive pair로 간주했었는데요. 이때, 마스크된 샘플들이 더 부분적인 정보를 가지고 있기 때문에 마스킹된 모달리티가 여전히 상대 모달리티와 유사하기는 하지만, 그 유사도는 마스킹되지 않은 모달리티보다는 떨어진다는 가정이 가능합니다. 이러한 가정을 기반으로 저자들은 pair-wise ranking loss를 제안합니다. $<V_e, T_e>$의 유사도가 $<V_m, T_e>$, $<V_e, T_m>$의 유사도보다 어느 정도 이상 높도록 하는 것이죠.

$$L_{rank} = \max(0, -(s(V_e, T_e)/\tau - s(V_e, T_m)/\tau) +\lambda) + \max(0, -(s(V_e, T_e)/\tau - s(V_m, T_e)/\tau)+\lambda)$$
$\lambda > 0$는 마진 하이퍼 파라미터입니다. 위 손실 함수는 모델이 $<V_e, T_m>, <V_m, T_e>$와 같은 마스킹된 쌍과 마스킹되지 않은 $<V_e, T_e>$ 쌍 간의 디테일한 정보의 차이를 고려하도록 하여 모델이 fine-grained perceptual capability를 유지하고 generalizability를 향상하게 합니다.
Semantic enhanced masked language modeling. Masked language modeling (MLM)은 VidL에서 고전적인 pre-training task로, 예를 들어, $V_e, T_m$이 입력되었을 때, $T_m$에서 유실된 정보를 복원하기 위하여 $V_e$의 정보를 활용하도록 하여 서로 다른 모달리티가 멀티 모달 인코더에서 상호작용하도록 촉진한다고 합니다. 저자들은 고전적인 MLM과 semantic text masking 전략을 병합하여 Semantic Enhanced Masked Language Modeling task를 제안합니다. 이로써 representation learning에 동사, 명사, 형용사의 새로운 중요한 컨셉들을 도입하게 되며, 나아가 텍스트에서 이러한 단어들의 클래스 불균형을 해결하기 위해 일반적인 교차 엔트로피 손실 함수 대신 focal loss를 도입하였다고 합니다. 저자들은 MLM loss를 통해 모델이 마스킹된 텍스트 토큰을 복원하도록 하였습니다.
$$ L_{mlm} = -\frac{1}{B}\sum^B_{i=1}\sum_{m_{t_j}\in M^i_{T_m}} [(1-p^i_{t_j})^\gamma p^i_{t_j}]$$
$p^i_{t_j}$는 $i$번째 문장의 마스킹된 토큰 $t_j$의 예측 확률 분포이며 $\gamma$는 하이퍼 파라미터입니다.
최종적인 Clover의 목적 함수는 다음과 같습니다.
$$L = L_{TmA} + L_{rank} + L_{mlm}$$
Experiments
저자들은 Clover를 250만 개의 영상이 담긴 WebVid2M과 330만 개의 이미지가 담긴 Google Conceptual Captions (CC3M)에서 사전학습시켰습니다. (일부 이미지 링크가 깨져서 이미지는 280만 개만 사용했다고 합니다.) 사전학습 과정에서 이미지는 1 프레임의 영상으로 취급됩니다.
Text-to-Video Retrieval. MSRVTT, LSMDC, DiDeMo 데이터셋에서 평가를 진행하였습니다. DiDeMo에서는 paragraph-to-video retrieval 방식으로 문장들을 합쳐 하나의 텍스트 쿼리로 사용하였으며, 기존 연구들과의 공정한 비교를 통해 GT proposal은 사용하지 않았습니다.
Retrieval task에서는 Clover의 각 단일 모달 인코더를 파인튜닝하여 사용하였습니다. 각 인코더로 비디오와 텍스트의 임베딩을 얻은 후, 임베딩의 코사인 유사도를 계산하여 retrieval을 수행하였으며, QA task에서는 멀티 모달 인코더를 포함한 Clover 모델 전체를 파인튜닝하여 사용하였습니다.
Multiple-choice QA.TGIF-Action, TGIF-Transition, MSRVTT-MC, LSMDC-MC 데이터셋에서 테스트하였습니다.
Open-Ended QA. TGIF-Frame, MSRVTT-QA, MSVD-QA, LSMDC-FiB에서 테스트하였습니다.
Implementation details. Violet과 유사하게, 비디오 인코더는 Kinetics-400에서 사전학습된 VideoSwin-Base, 텍스트 인코더는 사전학습된 Bert-Base, 멀티 모달 인코더는 Bert-Base 모델의 첫 3개 층의 가중치를 가져와 초기화하였습니다. 초기화 후 Clover는 사전학습과 파인튜닝 모두 end-to-end로 학습을 진행하였고, 사전학습은 64장의 A100 GPU에서 1024 배치 사이즈로 40 에포크 진행하였습니다. AdamW Optimizer를 사용하였고 weight decay 0.005, betas (0.9, 0.98), learning rate는 초반 4 에포크는 5e-5로 warm-up 후, cosine annealing decay schedule을 이용해 감소시켰습니다. 모든 비디오 프레임은 $224 \times 224$ 크기로 resize 하여 $32\times 32$ 크기의 패치로 분할하였습니다. 하이퍼 파라미터는 $\tau=0.05, \lambda =5, \gamma = 2$를 사용하였고, $D=768$을 사용하였습니다. 각 비디오에서 랜덤 하게 8 프레임을 추출하여 사용했습니다. Retrieval task의 파인 튜닝 시에는 단일 모달 인코더를 InfoNCE로 학습시켰고, VQA에서는 멀티 모달 인코더의 [CLS] 임베딩을 간단한 MLP에 태워 예측한 후, 교차 엔트로피 손실 함수로 학습시켰습니다. 파인튜닝 과정에서는 Violet과 CLIP4 Clip에서 사용한 일반적인 설정을 따랐고 8장의 A100 GPU를 사용했습니다.
Comparison with SOTAs
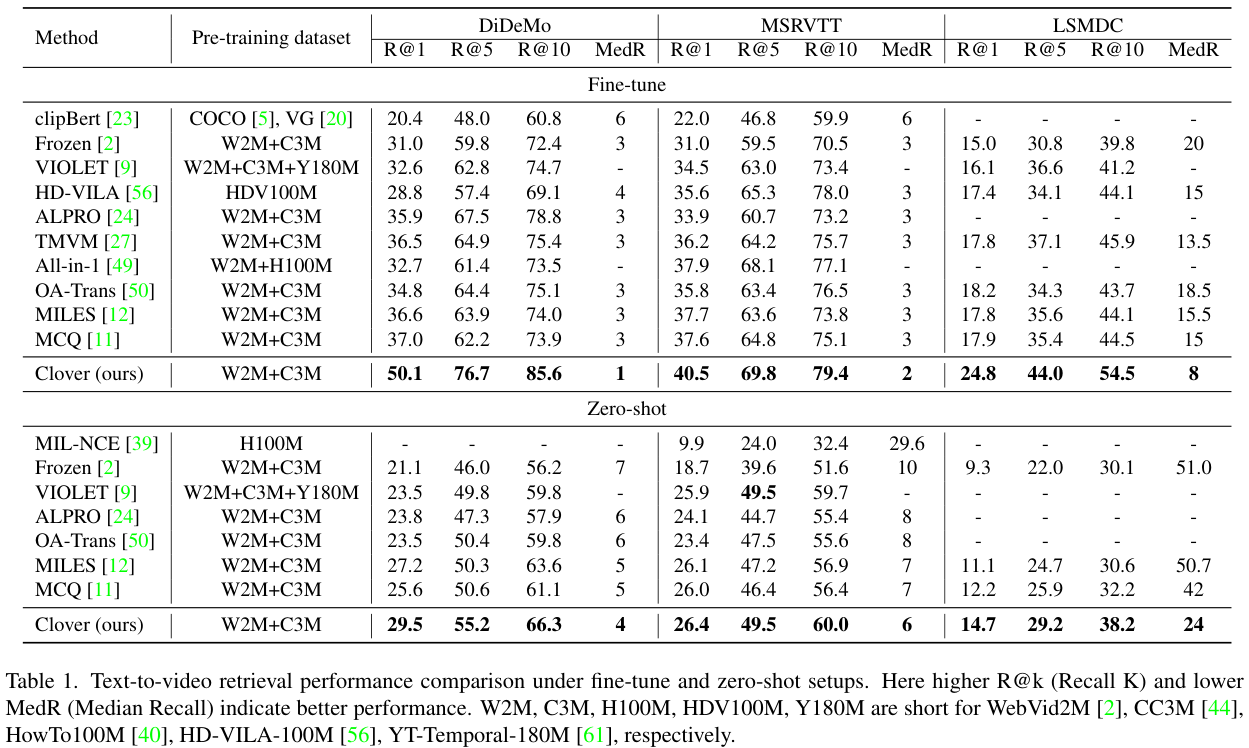
Text-to-video retrieval. Clover가 모든 기존 모델을 큰 차이로 앞서는 모습을 확인할 수 있습니다. 특히 zero-shot에서 성능향상이 크다는 점에서 Clover의 강력한 일반화 성능을 확인할 수 있습니다.
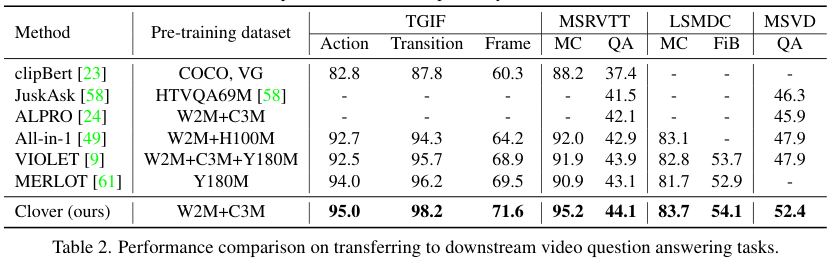
Video question answering. 다른 VQA 모델들에 비해 훨씬 적은 학습 데이터에도 불구하고, Clover가 가장 좋은 성능을 보여주었습니다. 특히, VQA를 위해 디자인된 대규모 데이터셋인 HTVQA69M, YTT180M을 사용한 JustAsk나 MERLOT 보다도 훨씬 적은 데이터로 좋은 성능을 보여주는 모습이 인상적이라 하네요.
Analysis
저자들은 DiDeMo와 MSRVTT Retrieval 데이터셋과 TGIF-Frame, LSMDC-MC VQA 데이터셋으로 비교 분석을 실행하였습니다. 이때, 실험 효율을 위해 WebVid2M에서 백만 개의 샘플을 뽑아 사전학습에 사용하였다고 합니다. 저자들은 Clover와 완전히 동일한 구조에서 MLM과 InfoNCE Loss로만 학습한 모델을 Baseline으로 설정하였습니다. 이는 Violet과 유사한 구조라 합니다. 모든 비교 실험은 배치 사이즈 1024로 32장의 A100에서 수행되었습니다.
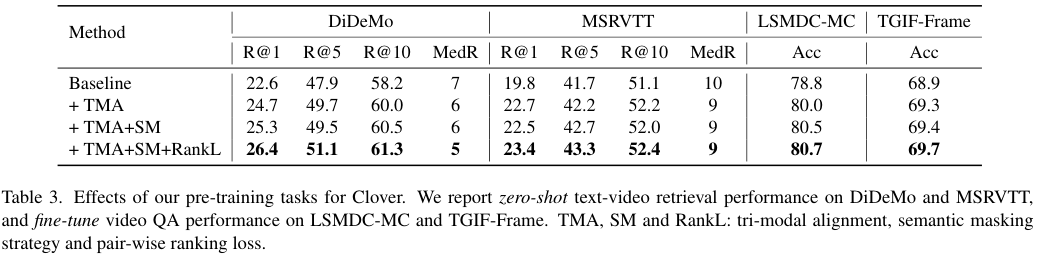
Effect of tri-modal alignment. TMA는 모달 간, 그리고 융합된 모달 간의 align을 잘하고자 고안되었습니다. TMA의 성능을 검증하기 위하여, pair-wise ranking loss와 semantic masking strategy 없이 MLM만 적용하여 baseline 삼아 비교를 진행했습니다. 그 결과, TMA를 사용할 경우 retrieval과 QA 모두에서 성능이 baseline보다 높아졌습니다.
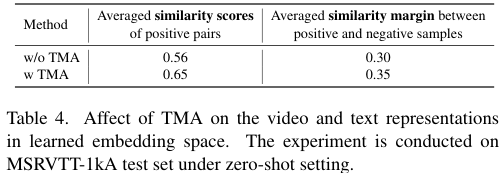
이어서 TMA 적용 여부에 따른 positive pair 간의 유사도 점수 평균과, positive pair, negative pair 간의 유사도 점수 차이의 평균을 구해보았는데 TMA를 적용한 경우 positive pair 간의 유사도 점수가 올라가고, positive pair와 negative pair의 구별력이 올랐다고 합니다. 이는 TMA를 통해 동일한 맥락 정보를 가진 비디오와 텍스트 간의 거리는 줄어들고, 그렇지 않은 경우 늘어난다는 것을 시사합니다.
Effect of semantic masking strategy. 다시 그림 3. 을 보면, Semantic Masking을 적용할 시, 비디오가 5개의 GT 텍스트와 묶여있는 DiDeMo와 같이 다양한 평가 방식을 가진 데이터에서 성능 향상이 더 큰 것을 볼 수 있습니다. Semantic masking을 통해 모델이 복잡한 scene에서 중요한 의미론적 정보를 포착하는 성능이 향상되었음을 볼 수 있습니다.
Effect of pair-wise ranking. 모델이 마스킹된 쌍과 그렇지 않은 쌍 간의 차이에 주의하게 하는 pair-wise ranking loss를 도입하자, 성능이 더욱 향상되는 것을 볼 수 있습니다.
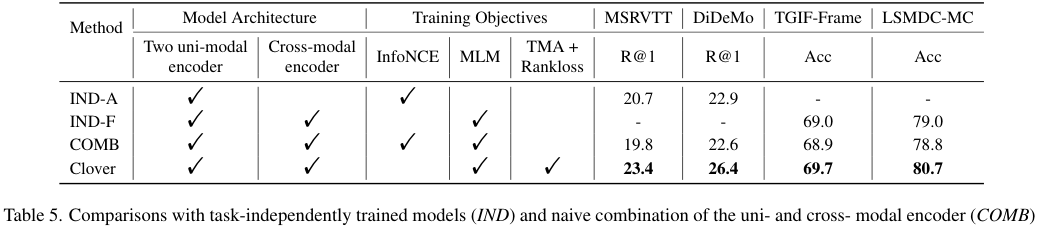
Clover makes cross-modal alignment and fusion mutually improving. Clover와 같은 구조를 가지지만 다른 사전학습 task를 가진 모델들과의 비교를 수행했다. IND-A는 cross-modal alignment를 InfoNCE Loss로만 학습한 결과이고 IND-F는 cross-modal fusion을 MLM으로만 학습한 결과이다. 멀티 모달 인코더를 단일 모달 인코더 위에 쌓아 COMB 방식으로 구성된 모델의 경우 오히려 성능이 감소하였다. Clover는 task에 맞게 학습된 IND-A, IND-F보다 좋은 성능을 보이며 Clover가 cross-modal alignment와 fusion 능력을 상호적으로 향상함을 알 수 있었습니다.

Qualitative analysis. 그림 3.을 보면, 주어진 비디오에 대하여 Clover가 단순히 종이를 접는 텍스트가 아니라 "종이비행기"를 포함한 텍스트를 상세히 retrieval 한 것을 확인할 수 있으며 그림 4. 에서도 질문에 대하여 베이스라인의 "Animal"보다 더 상세한 "Lion"을 답변한 것을 볼 수 있습니다.
Conclusion
이 논문에서는 video-text / text-video retrieval과 video question answering 모두를 효율적이고 효과적으로 수행할 수 있는 Video-Language pre-training 모델 Clover를 제안했습니다. Clover는 새로운 Tri-modal alignment를 통해 비디오, 텍스트, 융합 모달리티 모두를 더 잘 align 하고, 새로운 semantic masking strategy와 pair-wise ranking loss를 통해 cross modality training을 더욱 잘 수행합니다. 실험 결과, Clover는 기존 모델들에 비해 큰 차이로 여러 Video Understanding task에서 SOTA를 달성할 수 있었습니다.
CLIP 기반 논문들과 비교
논문에서 CLIP 기반 모델들과 선을 그으면서 성능 비교를 보여주지는 않지만, 본 모델과 CLIP 기반 방법론들의 성능을 간단히 비교해 보았습니다.
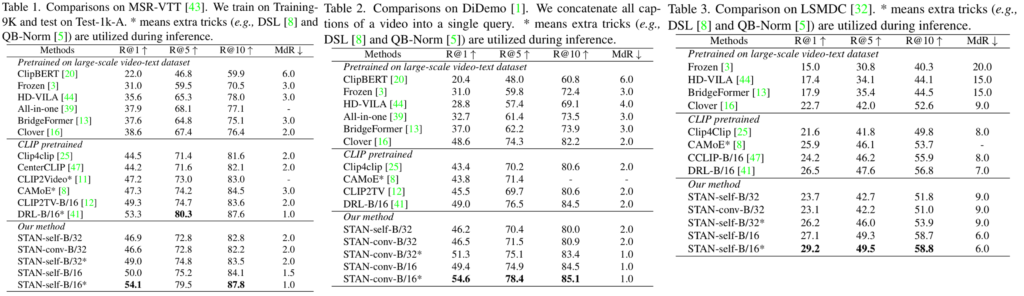
제가 일전에 리뷰한 Revisiting Temporal Modeling for CLIP-based Image-to-Video Knowledge Transferring (CVPR 2023)을 보면, Retrieval task에서의 비교가 잘 되어 있는데, Clover가 CLIP 기반 방법 중 하위권의 모델들과 비슷하거나 약간 모자란 성능을 보이고 있으며, CLIP을 사용한 방법 중 최신 방법론들보다는 조금 많이 아쉬운 성능을 보여주고 있는 것을 확인할 수 있었습니다.
다만 본 논문에서 제안한 Tri-modal alignment나 Pair-wise ranking loss 등을 CLIP 기반 방법론에도 적용할 수 있을 것 같은데, 그 경우 성능이 어떻게 될지 궁금하네요.
CLIP이 Image-Language 분야에서 universal 한 모델이 된 것처럼, Universal Video-Language Pre-training Model도 등장할 때가 다가오고 있는 것 같은데, 본 논문에서 제안한 다양한 방법들이 그 경지에 도달하는데 도움이 되겠다 싶은 논문이었습니다. 어서 이 흐름에 올라타고 싶은데, 점점 분야가 핫해지다 보니 논문 올라오는 속도도 빠르고, 컴퓨팅 자원도 많이 필요하고 쉽지 않네요.
가까운 시일 내에 Video-Language pre-training model에 대한 총정리를 하려고 하는데, 논문을 읽으면 읽을수록 더 읽어야 할 논문이 쌓여서 참 쉽지 않습니다.
아무튼, 읽어주셔서 감사합니다!