R-FCN: Object Detection via Region-based Fully Convolutional Networks 요약
대부분의 Object Detection 모델들이 Image Classification을 위해 학습된 VGG 등의 사전학습된 모델들을 가져와 backbone network로 사용한다. 그런데, 이때 Image Classification과 Object Detection Task의 차이 때문에 Translation Invariance 딜레마가 발생한다. R-FCN은 이 딜레마를 해결하여 성능을 향상시킨 2-stage detector이다.
Translation Invariance Dilemma
Image Classification Task에서는 이미지 안에 존재하는 어떤 객체 하나의 클래스를 출력한다.
모델이 이미지 안에서 객체가 어떤 위치에 존재하던 같은 결과를 내는, Translation Invariance한 속성을 가지는 것이다.
그런데 Object Detection에서는 이미지의 클래스 뿐만 아니라 위치를 예측해야 하기 때문에, 모델이 이미지 속 객체의 위치가 변함에 따라 출력 결과도 달라지는 Translation Equivalance 속성을 가져야 한다.
문제는 Object detector들의 앞부분에서 feature map을 추출하는 pretrained network들이 Translation Invariance한 Task를 위해 학습되었기 때문에, 위치 정보가 어느 정도 소실된 feature들을 만든다는 것이다.
이런 문제를 Translation Invariance Dilemma라고 한다.
Resnet + Faster R-CNN

Resnet+Fatser R-CNN이라는 모델에서는, Faster R-CNN처럼 pretrained resnet feature extractor를 통과한 feature maps를 Region Proposal Networks에 투입하여 ROI를 얻고, feature extractor에서 얻은 feature maps에 추가로 2번의 convolution을 진행한 후, ROI Pooling을 적용하고, 이를 다시 convolution 하여 최종적으로 Fast R-CNN shape detector에 투입하였다.
이를 통해 feature extractor에서 줄어든 region specific한 정보가 어느 정도 복원되어 translation equivalance 하게 되는 효과를 얻었으나, 각 ROI마다 추가적인 Conv 및 FC 연산이 추가되어 연산 시간이 매우 길어지는 단점이 있었다.
Fully Convolutional Layer
R-FCN은 ROI들의 중복된 연산을 공유하고 translation equivalance한 효과를 유지하기 위해 Fully Connection Layer없이 전체 모델을 Convolutional Layer로 구성한다. backbone network로 사용된 ResNet-101 모델에서 마지막 Pooling layer와 fc layer를 제거하고 모두 convolutional layer로 대체하였다.
base network부터 Region Proposal network(RPN), Detection network까지 모든 부분이 Convolutional Layer로 구성된 것이다.
Model
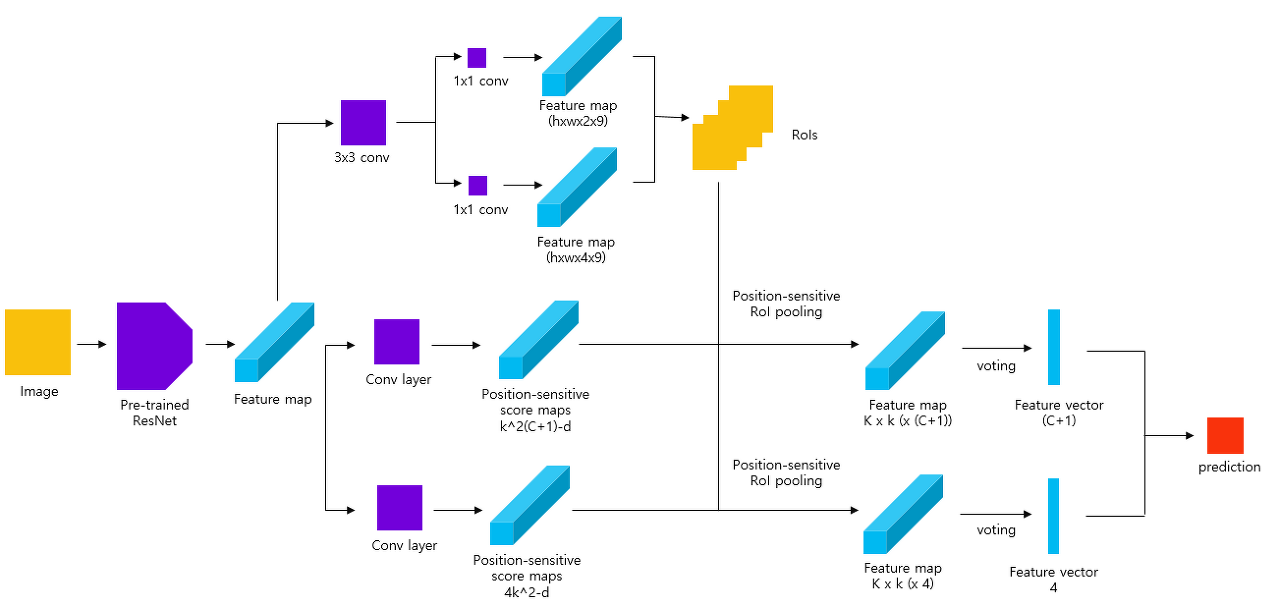
R-FCN은 Feature Extractor (ResNet)을 통과한 feature map을 RPN에 투입하고 별도로, Position-sensitive Score maps를 생성한다. score map은 ROI를 $k\timesk$격자(grid)로 나누어 클래스 $C$개에 대한 confidence score를 포함한 $k^2(c+1)$ 채널의 score map과, 각 격자속 bounding box offset에 대응되는 $4k^2$ 채널의 score map이 생성된다. (Convolution을 이용한 Detection이 잘 이해가 되지 않는다면, OverFeat 논문을 확인해보길 바란다.)
이렇게 생성된 2개의 feature map에 대해 RPN이 생성한 ROI들을 활용한 Position Sensitive ROI Pooling을 적용하고, ROI 별로 voting이라고 소개된 방법을 적용하여 최종 detection 결과를 생성한다.
Position Sensitive Pooling

ROI Pooling을 거쳐 얻은 $K$개의 ROI에 대해, $k\times k (C+1)$ 채널의 feature map으로부터 ROI속 $k\times k$격자 속값들을 뽑아내어 $k\times k$크기의 feature map을 $(C+1)$ 채널 수만큼 만든다.
Voting
위에서 만든 $k\times k$크기의 $(C+1)$채널의 feature maps에서 각 클래스에 해당하는 값의 평균을 구한다. 이것이 해당 ROI의 Confidence Score가 된다.
Bounding Box offset도 비슷한 방법으로 구하여 최종 결과를 만든다.
정리
간단하게 R-FCN을 알아봤다.
R-FCN은 Translation Invariance한 Feature Extractor의 feature map에 $k\times k$ 격자에 대한 positional 한 정보를 생성하도록 하여 Translation Equivalance 하도록 만들어 정확도를 향상시켰다.
이를 활용하여 예측을 수행하는 과정 전체를 Convolutional 하게 하여 동시에 속도 면에서도 큰 손해가 없도록 하였다.
결과적으로 PASCAL VOC2007에서 83.6 mAP를 달성하였고, ResNet + Faster R-CNN보다 빠른 속도를 달성하였다고 한다.
많은 논문들을 빠르게 봐야해서 정리를 상세히 못하여 아쉽다.
혹시 R-FCN을 더 자세히 알고 싶으신 분들은 참고자료의 블로그들을 참고해주시기 바란다.
참고자료
'Deep Learning > 공부 노트' 카테고리의 다른 글
| YOLO v2(YOLO9000: Better, Faster, Stronger) 요약 (0) | 2023.01.30 |
|---|---|
| FPPI, LAMR, MR: Object Detection을 위한 지표들 (0) | 2023.01.26 |
| SSD: Single Shot MultiBox Detector 요약 (0) | 2023.01.11 |
| YOLO: You Only Look Once 부수기 [백 병장의 CV 부수기 6편] (0) | 2022.12.11 |
| OHEM 부수기 [백 병장의 CV 부수기 5편] (1) | 2022.12.10 |