TSM: Temporal Shift Module for Efficient Video Understanding 리뷰 (ICCV 2019)

이 논문은 딥러닝 기반 Video Understanding 분야에서 속도가 빠르지만 정확도가 낮은 2D CNN과 정확도가 높지만 속도가 느린 3D CNN의 단점을 극복하여 빠르면서도 정확한 Video Understanding을 위한 방법인 TSM을 제안한다.
영상은 이미지의 공간적 정보에 더하여 시간적인 정보를 담고 있는데, 이는 영상의 내용을 파악하는데 아주 중요하다. 예를 들어, 상자를 여는 영상과 상자를 닫는 영상은 시간적인 순서가 역전되면 의미가 바뀌며, 시간적인 정보가 없으면 판별하기 매우 어렵다.
이러한 동영상의 시간적 정보를 활용하기 위하여 사용되는 합성곱 계층 기반의 두 가지 접근 방식이 있다.
하나는 이미지 분석에 흔히 사용되는 2D CNN을 활용하는 것이다. 영상의 각 프레임을 2D 합성곱 계층에 입력하여 공간적 정보를 추출하고, 이를 LSTM과 같은 시계열 데이터를 처리하는 신경망에 입력하여 시간적 정보를 처리하는 것이다. 이러한 방법들은 비교적 단순하고 연산량이 적지만, 프레임을 2D 합성곱을 거쳐 feature map으로 만드는 과정에서 low-level 시간적 정보가 손실된다. 다른 방법은 3D 합성곱 신경망을 사용하여 공간적 정보와 시간적 정보를 한 번에 뽑아내는 것이다. 이 방법은 비교적 정확도가 높지만, 2D 합성곱에 비하여 더 많은 파라미터가 필요하기 때문에 연산량이 크게 증가하고 연산 시간이 길어진다.
저자들은 영상의 일부 채널들을 시간축으로 Shift 하는 Temporal Shift를 적용하여 2D 합성곱으로도 시간적 정보를 얻을 수 있도록 하는 Temporal Shift Module(TSM)을 제안한다. 이때, 일반적으로는 각 채널을 시간축으로 ±1만큼 이동시키지만<그림 1의 (b)>, 실시간 스트리밍에서는 미래의 프레임을 미리 가져올 수 없기 때문에 한 방향으로만 이동시킨다.<그림 1의 (c)>
저자들이 주장하는 이 논문의 contribution은 다음과 같다.
- Temporal shift를 이용하여 컴퓨팅 성능을 크게 요구하지 않으면서도 시공간적 정보를 잘 잡아내는 video model design 제안
- 전체 채널을 아무렇게나 shift하는 것(naive shift)이 아닌, 일부 채널만 shift를 수행하고(partial shift), shift가 일어나더라도 기존의 정보를 유지할 수 있도록 하는 residual shift를 진행하여 성능과 효율을 향상
- offline video understanding을 위한 양방향 TSM을 제안하여 SOTA 달성
- edge device에서의 low latency로 online video understanding을 제공하기 위한 단방향 TSM을 제안
Related Works
Deep Video Recognition
2D CNN구조는 직관적이며, 효율적이지만 3D CNN에 비하여 시간적인 관계를 추론하지 못한다. 한편 3D CNN은 시공간적 특성을 모두 파악할 수 있지만 더 많은 파라미터를 갖기 때문에 무겁고, 오버피팅에 취약하다. 한편 TSM은 3D CNN과 같이 시공간적 특성을 얻을 수 있으면서도 2D CNN과 같은 컴퓨팅 자원을 요구한다.
Temporal Modeling
동영상의 시간적 정보를 얻는 직접적인 방법은 3D CNN을 이용하는 것이지만, 2D CNN으로 얻은 프레임 단위 특성을 LSTM이나 별도의 신경망을 통해 병합하는 방법도 존재한다. 그러나 이러한 방법들은 결국 추가적인 컴퓨팅 성능을 요구하며 특성 추출 과정에서 low-level temporal information을 잃는 것에 반하여, TSM은 2D CNN의 성능으로 시공간적 특성을 바로 추출할 수 있다.
Temporal Shift Module (TSM)
앞서 얘기한 것처럼 TSM은 주어진 C개의 채널 중 일부를 시간 축으로 ±1만큼 이동시킴으로써(온라인 영상의 경우 단방향) 2D 합성곱으로도 시간적 정보를 검출할 수 있게 되어 성능 향상을 이루었다. 그러나 이러한 shift를 아무렇게나 적용한다고 해서 이것이 성능 향상으로 직결되지는 않았다고 한다. naive shift는 두 가지 방식으로 성능을 감소시켰다.
- 데이터 이동으로 인한 성능 감소: 동영상은 5D tensor 형태의 매우 큰 데이터이다. 이러한 데이터에 너무 많은 채널을 shift 할 경우 데이터 이동으로 인한 overhead가 발생하여 CPU와 GPU latency가 각각 최대 13.7%, 12.4% 증가하였으며, 이는 추론 및 학습 시간을 큰 폭으로 감소시켰다.
- 공간적 정보 손실로 인한 정확도 감소: 영상의 일부 채널을 시간 축으로 shift하는 것은 이웃한 프레임과의 시간적 정보를 얻을 수 있게 해 주지만, 프레임이 가지고 있는 공간적 정보를 파괴하는 단점도 있기 때문에, shift를 많은 채널에 가해질수록 정확도가 감소하였다.
저자들은 이 문제들을 채널의 일부분만 shift하는 partial shift와 shift로 인한 공간 정보 손실을 최소화하는 residual shift로 해결했다.
Partial Shift
데이터 이동으로 인한 오버헤드를 줄이기 위해, 저자들은 전체 채널 중 shift를 적용하는 채널의 비율인 Shift Proportion을 적절하게 설정하여 오버헤드를 최소화하면서 성능은 최대화하고자 하였다. <그림 2>에서 Shift Proportion에 따른 오버헤드와 정확도의 변화를 볼 수 있다.
Residual Shift
Temporal Shift는 채널들을 시간 축으로 섞어 2D 합성곱으로도 시간적 정보를 얻을 수 있게 하지만, 동시에 프레임이 원래 가지고 있던 공간적 정보는 일부 파괴한다. 이를 극복하기 위해 저자들은 ResNet 구조의 Redisual Branch에서 shift를 진행하는 Residual Shift를 도입하여 Shift가 일어나도 원래 공간적 정보를 유지하도록 하였다. ResNet에 대해 궁금하다면 필자의 ResNet 리뷰를 참고하기 바란다.
Residual Shift를 적용하면 프레임이 원래 가지고 있는 공간적 정보가 포함된 feature와 shift가 일어난 후 얻어진 feature가 별도로 계산되어 합쳐지게 되므로, 시간적 공간적 정보를 모두 활용할 수 있다.
Residual Shift를 적용한 결과 이를 적용하지 않은 In-Place TSM 대비 성능이 향상되었으며, 특히 Shift Proportion이 1까지 높아져도 shift를 적용하지 않은 모델에 비해 좋은 성능을 내었다. 저자들은 실험을 통해 가장 좋은 성능을 보인 1/4 Shift Proportion을 사용하였다.
Shift의 적용 방법
그렇다면 구체적으로 Shift는 어떻게 적용되는 것일까? 저자들이 공개한 코드를 통해 이해해보자. (필자가 일부 수정하였다.)
Temporal Shift Module은 다음과 같은 형태의 클래스로 구현된다.
class TemporalShift(nn.Module): def __init__(self, net, n_segment=3, fold_div=8): # net은 어떤 합성곱 계층이다. # 중략 def forward(self, x): # shift를 수행하고 입력된 합성곱 계층을 통과시켜 리턴한다. x = self.shift(x, self.n_segment, fold_div=self.fold_div, inplace=self.inplace) return self.net(x) def shift(x, n_segment=3, fold_div=8): nt, c, h, w = x.size() # nt에서 배치 n과 시간 축 t를 분리한다. n_batch = nt // n_segment x = x.view(n_batch, n_segment, c, h, w) fold = c // fold_div # 전체 채널 중 shift할 채널의 갯수 out = torch.zeros_like(x) out[:, :-1, :fold] = x[:, 1:, :fold] # shift left out[:, 1:, fold: 2 * fold] = x[:, :-1, fold: 2 * fold] # shift right out[:, :, 2 * fold:] = x[:, :, 2 * fold:] # not shift return out.view(nt, c, h, w) # n축과 t축을 다시 병합
TSM은 TSN 구조에 따라 영상을 segment 단위로 나누어 처리한다. segment가 t개의 프레임을 가지고 batch_size가 n일 때, 하나의 배치는 (n,t,c,w,h) 차원을 갖는다. 그런데 TSM은 2D CNN이므로, n 축과 t축을 합쳐서 (nt,c,w,h)의 형태로 입력받는다.
위 코드의 Temporal Shift 클래스는 입력된 데이터의 일부 채널을 시간축으로 shift한 뒤 주어진 신경망을 통과시켜 리턴한다.
시간축으로의 shift를 위해 nt 축을 분리해줄 필요가 있다. (코드 15-16번째 줄)
(n,t,c,w,h)의 형태로 분리된 feature map에서 일정 비율의 채널에 shift를 적용한다. (코드 18-22번째 줄)
shift를 완료한 후, 다시 2D CNN에 태울 수 있도록 (nt,c,w,h)채널로 변환하여 주어진 신경망을 통과하여 반환한다.
TSM Video Network
TSM은 2D CNN과 정확히 같은 컴퓨팅 성능을 요구하면서도 3D와 같이 시간적 정보를 얻을 수 있다. 저자들은 ResNet-50 구조를 사용하여 TSM을 구현하였는데, 매 Residual Temporal Shift Module마다 모델이 갖는 Temporal Receptive Field가 2배로 커져, 모델이 매우 큰 Temporal Receptive Field를 가질 수 있었다. 또한 모델이 대중적인 2D 합성곱 연산을 사용하기 때문에 CuDNN, MKL-DNN 등 다양한 프레임워크와 하드웨어에서 이미 최적화되어 있는 장점이 있었다.
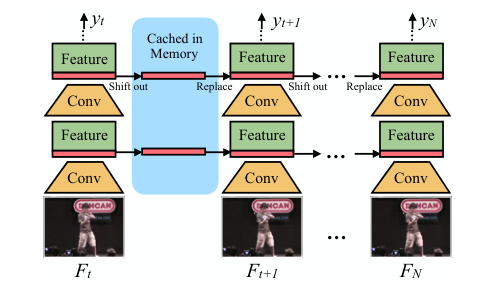
한편 online 환경에서의 실시간 영상을 처리할 때는 미래의 프레임을 가져올 수 없기 때문에 <그림 5>와 같이 TSM은 단방향 구조로 작동한다. 이때 현재 프레임의 feature map의 1/8은 캐시해 두었다가 다음 프레임의 TSM 연산에 사용한다.
Experiments
저자들은 Temporal Segment Networks(TSN)라는 2D CNN 구조를 Baseline 삼아 다른 모델들과 비교를 수행하였다. 실험 결과에서 TSM은 저자들이 TSN 구조에 TSM을 접목하여 실험한 결과이다.
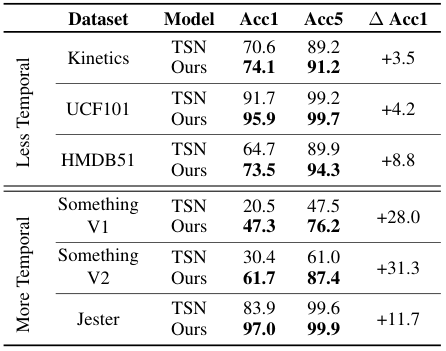
저자들이 제안한 모델은 다른 2D CNN 모델 대비 연산량 증가 없이 더욱 높은 성능을 보였다. <표 1>에서 TSN에 단순히 TSM을 추가하기만 하였음에도 성능이 향상되었음을 볼 수 있다. 특히, 시간적 정보가 중요한 Something-Something, Jester 데이터셋에서 성능이 크게 향상되었다.
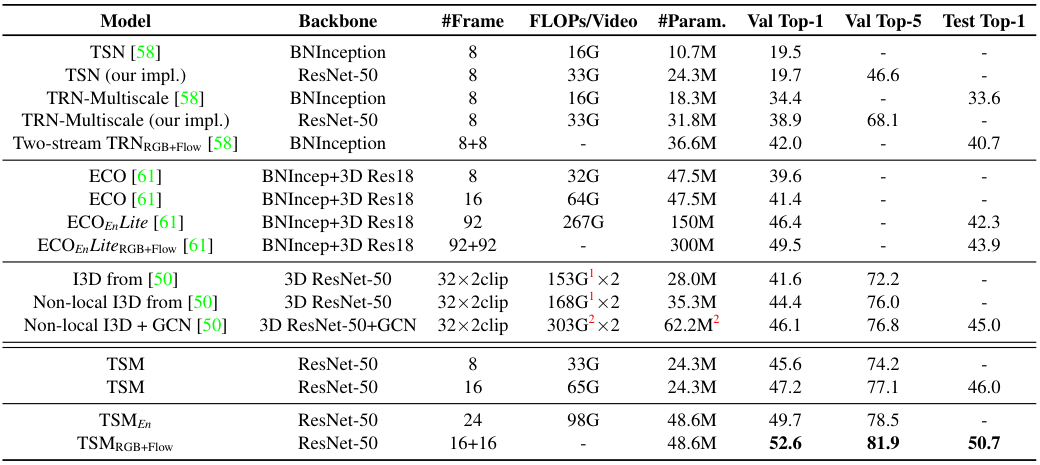
<표 2>는 Something-Something Dataset에서 TSM과 다른 모델들 간의 성능 비교 결과이다. 상단은 2D 기반 방법이며, 두 번째 구간은 2D로 시작하여 3D로 변환되는 구조를 사용하는 medium-level temporal fusion 방법이다. 세 번째 구간은 3D 기반 방법이다.
TSM이 전체적으로 가장 좋은 성능을 보이고 있으며, 특히 TSM 모듈을 적용하지 않은 TSN (our impl.) 버전에 비해 성능이 매우 큰 폭으로 향상된 것을 볼 수 있다. 연산량도 저자들이 주장하는 것처럼 3D fusion이나 3D 모델에 비해 더 적은 것을 확인할 수 있다.
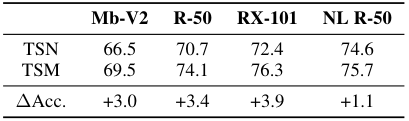
저자들은 MobileNet-V2, ResNet-50, ResNext-101, ResNet-50 + Non-local module과 같이 다양한 backbone에 TSM을 적용하였고, 그 결과 <표 3>처럼 성능의 향상이 있었으며, 이미 시간적 정보를 얻을 수 있는 NL R-50에서도 성능이 개선되었다.
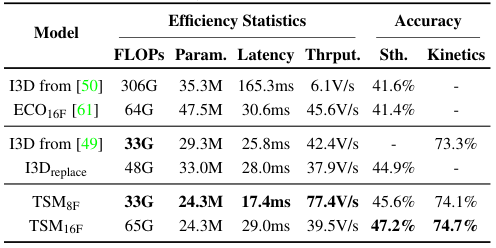
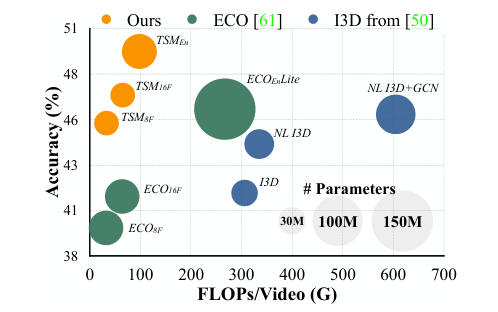
<표 2>, <표 4>, <그림 6>에서 나타난 것처럼, TSM은 타 모델들 대비 적은 연산량(FLOPs)과 Latency, 좋은 Throughput을 갖는다. TSM은 특히 효율성을 중시하여 설계된 ECO보다도 성능이 좋으며, I3D와는 비슷한 연산량을 갖지만 2D 합성곱이 하드웨어 친화적이기 때문에 더 좋은 속도를 보인다.

<표 5>를 보면, Onlnie TSM 모델이 2D baseline인 TSN 대비 0.1ms의 Latency만 증가하면서도 25%가량의 성능 향상을 이루는 것을 볼 수 있다.
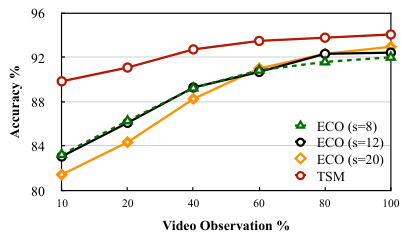
또한 TSM은 좋은 Early Recognition 성능을 갖는다. Early Recognition이란 영상의 일부만을 보고도 영상을 분류하는 것을 의미하는데, <그림 7>은 TSM의 Early Recognition 성능이 ECO에 비해 높으며, 특히 영상의 10%만을 보고도 90%에 가까운 정확도를 보임을 알 수 있다.
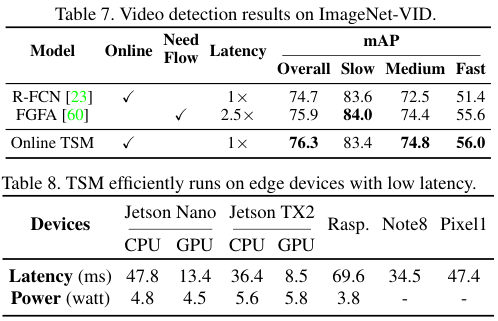
TSM은 Edge Device에서 적은 Latency와 power를 사용하며 높은 성능을 보인다. TSM은 특히 ImageNet-VID 데이터셋에서 빠르게 이동하는 물체들을 잘 잡아내었다.
이 논문에서는 동영상 분석에 2D 합성곱 신경망을 사용하여 높은 속도를 얻으면서도 동영상의 시간적 정보 손실을 최소화하기 위해 Temporal Shift Module을 제안하였다. 이 모듈은 프레임의 일부 채널에 시간 축에 대한 shift를 가하여 2D 이미지인 상태로 시간적 정보를 주입하고, 2D CNN이 공간적 정보뿐만 아니라 시간적 정보까지 활용할 수 있도록 한다.
이때 partial shift와 residual shift를 통하여 shift로 인한 공간적 정보의 손실을 최소화하고 Vanilla 2D CNN에서 아주 조금의 연산량만을 희생하여 SOTA 성능을 달성하였다.
댓글을 사용할 수 없습니다.