Background Suppression Network for Weakly-Supervised Temporal Action Localization 리뷰 [AAAI 2020]
이번 논문은 Weakly-Supervised Temporal Action Localization 분야의 논문으로, 무려 우리나라 연구진이 쓴 논문이다. 지금까지 많이 리뷰한 Temporal Action Localization (TAL)은 어떤 영상에서 어떤 액션이 등장하는 시간대와 액션의 종류를 찾아내는 task였다. 한편 이번에 리뷰할 Weakly-Supervised TAL (WTAL)은 같은 task에서 정답 라벨에 시간이 없이 액션의 클래스만 주어지는 task이다.
예를 들어 TAL에서 어떤 영상에 대한 라벨이 (2초~5초 다이빙)과 같이 주어졌다면, WTAL에서는 (다이빙)만 주어진다. 이러한 상황에서 당연히 액션이 일어난 시간까지 알아내도록 학습하려면 어려움이 따른다. 이 논문은 액션이 없는 background에 대한 추가 클래스를 할당하여 background frame을 억제하고 TAL 성능을 향상하는 새로운 Background Suppression Network (BaS-Net)을 제안한다.
기존의 WTAL 방법론들은 먼저 각 프레임이 어떤 액션에 속할 확률을 구한 뒤, 이들을 병합하는 식으로 영상에 대한 Action classification을 수행하도록 하여 결과적으로 frame level classification이 가능하게 하는 식의 접근을 주로 선택했다. (Multiple Instance Learning, MIL) 그러나 저자들은 이러한 MIL 방식이 background 프레임들을 그저 다른 프레임으로 분류하여 문제를 정확히 모델링하지 못하고, background 프레임들을 false positive로 학습되게 하여 성능 하락을 일으킨다고 지적한다.
저자들은 이러한 문제를 해결하기 위해 background 프레임들을 위한 추가 클래스를 생성하여 fully-supervised object detection이나 TAL과 비슷하게 WTAL에 접근하지만, 이러한 방식은 background frame에 대한 라벨이 없어 결국 background frame 분류에 대해 잘 학습되지 않게 되기에, 두 branch로 구성된 BaS-Net을 제안한다.
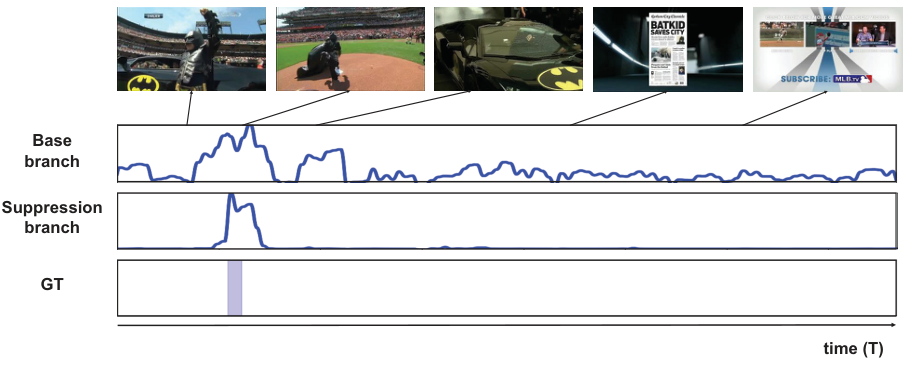
BaS-Net은 Base Branch와 Suppression Branch로 구성된다. Base Branch는 일반적인 MIL 구조와 비슷하게, Frame-wise feature를 입력받아 frame-wise class activation sequence (CAS)를 생성한다. 그와 동시에 Suppression Branch는 Base Network와 같은 구조, 공유된 가중치를 가지며 입력된 feature에서 background frame들의 activation score들을 감소시키는(attenuate) 필터링 역할을 수행한다. Suppression Branch의 목적은 Base Branch와 반대로 background class들의 score를 감소시키는 것인데, 두 branch가 가중치를 공유하기 때문에 두 branch는 무작정 score를 올리거나/내리도록 동시에 학습될 수 없다. 이러한 제한으로 인해 필터링 모듈은 background에 활성화 값만을 감소시키도록 학습되며, 결과적으로 action에 대한 정확도가 향상되게 된다고 한다.
저자들은 contribution을 세 가지로 정의한다.
- 저자들은 background를 의미하는 추가 클래스를 통해 WTAL 모델이 background에 적절히 대응하게 하였다.
- 대비되는 목적을 가진 비대칭 two-branch weight-sharing 구조를 통해 background 프레임에 대한 억제 수행
- THUMOS'14와 ActivityNet에서 WTAL SOTA 달성
Related Work
지도학습기반 TAL 방법들은 주로 Sliding Window 기반의 방법으로 영상을 작은 클립들로 나누어 분류를 수행하는 방식으로 수행되어 왔다. 최근에는 proposal generation에 더 정교한 방법을 사용하는 방식도 등장하였다.
약지도학습기반 TAL 방법은 video-level label만이 주어진 상황에서 TAL을 수행하여야 한다. 주로 앞서 언급한 것처럼, 프레임 단위로 class activation sequence를 생성하는 방법을 사용하는데, 이러한 방법은 일부 구별적인(discriminative) 프레임에만 집중하는 경향이 있다고 한다. 이외에도 MIL 방식과 같은 방법으로 WTAL을 푸는 시도들이 있었으나, 이들은 background frame들을 위한 bg class를 고려하지 않았다. 저자들이 주장하는 이 논문의 큰 contribution이 이러한 background class의 고려이다.
Proposed Method
$N$개의 학습 영상 $\{v_n\}^N_{n=1}$과 video-level label $\{\mathbb{y}_n\}^N_{n=1}$이 있다. $\mathbb{y}$는 $C$개의 클래스에 대한 $C$차원의 이진 벡터이다. 영상은 여러 개의 액션 클래스를 포함할 수도 있다. 각 영상은 신경망에 입력되어 frame-level class score 즉, Class Activation Sequence (CAS)를 생성한다. 모델은 생성된 스코어의 병합 과정을 거쳐 video-level 예측을 생성하도록 학습된다. Inference 시에는 frame 단위의 CAS에 임계값을 적용하여 localization을 수행한다.
Background Class
앞서 지적한 것처럼 background를 위한 별도의 클래스가 없으면, 영상의 background frame은 다른 액션 클래스들로 분류되어 정확한 localization을 방해한다. 저자들은 background를 위한 별도의 클래스를 추가하여 액션이 없는 프레임은 background class로 분류되도록 하였다. 이때, 자연스럽게 모든 영상은 background 프레임을 포함하고 있기 때문에 background에 대한 positive sample이 되는 반면, negative sample은 존재하지 않기 때문에 데이터 불균형이 초래된다.
Two-branch Architecture

앞서 언급한 문제를 극복하고 background class를 더 잘 다루기 위해, 저자들은 two-branch 구조를 사용하였다. 영상에서 추출된 feature들은 두 개의 브랜치로 입력된다. 두 브랜치는 가중치를 공유하며 feature map을 입력받아 CAS를 생성하는데, 이때 Suppression 브랜치는 background 프레임들을 필터링하여 이들의 CAS를 억제하는 필터링 모듈이 포함되어 있다. 두 브랜치는 가중치를 공유하지만 상반된 목표를 가지고 있는데, Base 브랜치는 입력 영상이 가지고 있는 액션 클래스와 background에 대한 positive sample로써 이들을 분류하기 위한 CAS를 생성하는 반면, Suppression 브랜치는 똑같이 분류 점수를 생성하되 background class의 스코어를 최소화하는 목표를 가지고 있다. 두 브랜치의 가중치를 공유하는 것은, 같은 입력이 주어졌을 때 두 브랜치가 모두 목표를 달성하지 못하도록 한다. (만약 Base 브랜치의 목표가 달성되면 Suppression 브랜치는 목표를 달성하지 못하고, 반대도 성립한다.) 그러므로 오직 필터링 모듈만이 Suppression 브랜치의 목표를 달성하기 위해 중요한 역할을 하게 되어, background를 잘 필터링하도록 학습된다.
Background Suppression Network
먼저 입력 영상 $v_n$를 16 frame의 겹치지 않는 $L_n$개의 세그먼트들로 나눈다. ($v_n = \{ s_{n,l} \}^{L_n}_{l=1}$) 영상의 길이가 매우 다양하기 때문에, 저자들은 각 영상에서 고정된 $T$개의 세그먼트를 추출하였다. 그다음, 각 세그먼트의 RGB 영상과 optical flow를 사전학습된 특징 추출기에 입력하여 $F$차원의 feature vector $x^{RGB}_{n, t}\in \mathbb{R}^F$와 $x^{flow}_{n, t} \in \mathbb{R}^F$를 추출한다. 두 vector를 합쳐 최종 특성 $f_{n, t}\in \mathbb{R}^{2F}$를 생성한다. ($X_n = [ x_{n, 1}, \cdots x_{n, T}] \in \mathbb{R}^{2F\times T}$)
Base Branch에서는 segment-level class score를 생성하기 위해, 각 클래스에 대한 확률을 담고 있는 CAS $\mathcal{A}_n$을 생성한다. CAS는 1D 합성곱으로 생성된다.
$$ \mathcal{A}_n = f_{conv}(X_n; \phi)$$
$\phi$는 합성곱 신경망의 학습 가능한 파라미터를 나타낸다. $\mathcal{A}_n \in \mathbb{R}^{(C+1) \times T}$가 성립하는데, $C+1$은 전체 액션 클래스의 수에 background 클래스를 추가한 것을 의미한다. segment-level class score를 담고 있는 CAS를 병합하여 video-level class score를 생성하여 실제 라벨과 비교하고 학습을 진행한다. 점수를 병합하는 방법으로는 top-k mean 방법을 사용했다고 한다. 클래스 c에 대한 video-level class score는 다음과 같이 나타낼 수 있다.
$$a_{n;c} = \text{aggregate}(\mathcal{A}_n, c) = \frac{1}{k} \max_{A\subset \mathcal{A}_n [c, :] |A|=k} \sum_{\forall a \in A} a$$
$k=[\frac{T}{r}]$이고 $r$은 선택된 세그먼트의 비율을 조정하는 하이퍼 파라미터이다. 얻어진 video-level class score를 softmax를 거쳐 영상을 분류하는데 활용된다.
$$p_n = \text{softmax}(a_n)$$
Base 브랜치는 다음과 같은 이진 크로스 엔트로피 손실로 학습된다.
$$\mathcal{L}_{base} = \frac{1}{N}\sum^N_{n=1}\sum^{C+1}_{c=1} -y^{base}_{n;c} \log(p_{n;c})$$
Suppression Branch는 base 브랜치와 다르게 필터링 모듈을 앞단에 가지고 있다. 이 모듈은 background 프레임들을 억제하도록 학습된다. 모듈은 두 개의 temporal 1D 합성곱 계층과 sigmoid 하수로 구성된다. 출력은 가중치 $\mathcal{W}_n\in \mathbb{R}^T$로 0~1의 범위를 가진다. 필터링 모듈의 출력은 feature map에 시간축으로 곱해져 background 프레임을 억제하게 된다.
$$X'_n = X_n \otimes \mathcal{W}_n$$
나머지 과정은 Base 브랜치와 똑같이 수행된다. 다만 입력만이 $X_n$에서 $X'_n$으로 바뀌어 $p'_n$을 얻게 된다. suppression 브랜치의 학습은 이진 크로스 엔트로피로 다음과 같이 수행된다. (이 역시 base와 똑같다.)
$$\mathcal{L}_{supp} = \frac{1}{N}\sum^N_{n=1}\sum^{C+1}_{c=1} -y^{supp}_{n;c} \log(p'_{n;c})$$
이때, $y^{supp}_n$에서 background label은 0으로 설정된다. 이를 통해 background frame이 적절히 필터링되도록 학습되는 것이다.
Joint Training. 두 브랜치는 동시에 학습된다. 추가로, filtering weight에 L1 규제를 적용한다. 그러므로 전체 손실함수는 다음과 같다.
$$\mathcal{L}_{overall} = \alpha \mathcal{L}_{base} + \beta \mathcal{L}_{supp} + \gamma \mathcal{L}_{norm}$$
$\alpha, \beta, \gamma$는 각 손실함수의 비율을 조절하는 하이퍼파라미터이다.
Classification and Localization
추론 단계에서는 background에 대한 억제가 진행된 suppression 브랜치의 출력을 사용한다. $p'_n$에서 먼저 임계값 $\theta_{class}$ 미만의 값을 갖는 클래스들을 제외하고, 남은 CAS를 다시 $\theta_{act}$로 걸러 후보 세그먼트를 선택했다. 그다음, 각 후보 세그먼트를 proposal 삼아 confidence score를 계산하였다.
Experiments
Experimental Settings
저자들은 TAL 분야에서 흔히 사용되는 THUMOS'14, ActivityNet 데이터셋을 사용하였다. 이때, 데이터셋에 원래는 temporal label이 포함되어 있으나 이는 사용하지 않았다. 평가는 mAP@IoU를 사용하였다. 저자들은 특성 추출기로 UntrimmedNet과 I3D net을 사용하였고, 이들은 ImageNet과 Kinetics에서 각각 사전학습되었다. 공정한 비교를 위해 특성 추출기에 대한 fine-tuning은 진행하지 않았다. 저자들은 TVL1 알고리즘을 통해 optical flow를 생성하였다.
저자들은 세그먼트의 개수 $T$를 750으로 설정하였고, 각 영상에서 세그먼트를 추출하기 위해 STPN과 같이 학습 단계에서는 random perturbation, 테스트 단계에서는 uniform sampling을 수행하였다. 하이퍼파라미터는 그리드 서치로 설정하여 $r=8, \alpha=1, \beta=1, \gamma=10^{-4}, \theta_{class}=0.25$를 적용하였고, $\theta_{act}$는 0~0.5 사이를 0.025 단위로 나누어 임계값을 설정하였다. 그 다음 임계값 0.7로 NMS를 수행하여 중복 예측을 제거했다.
Comparison with SOTA methods
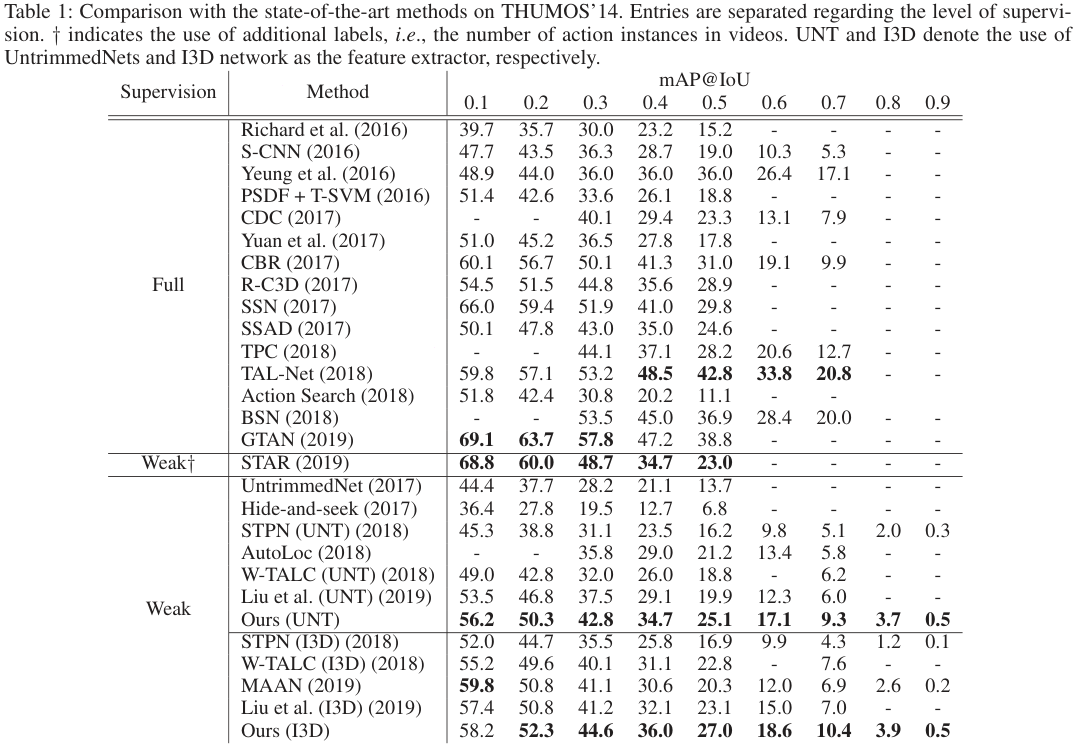
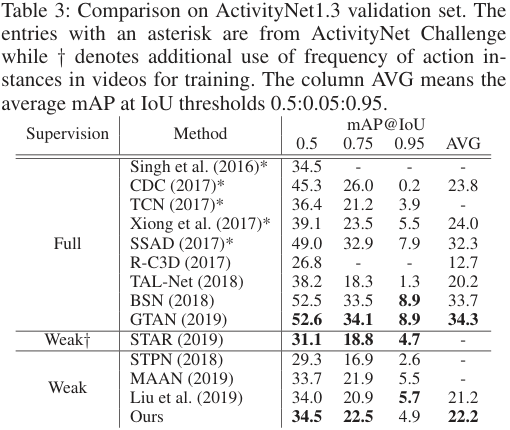
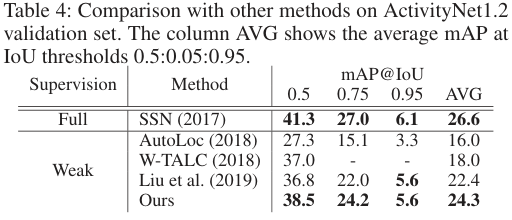
저자들은 제안한 BaS-Net과 기존 TAL, WTAL SOTA 방법들 간의 비교를 수행하였다. STAR는 WTAL이긴 하나 supervision의 정도가 달라 별도로 분류했다고 한다. 저자들이 제안한 BaS-Net이 Weakly supervised 모델 중에 가장 우수한 성능을 보여주는 것을 표에서 확인할 수 있다. 뿐만 아니라, BaS-Net은 더 supervision을 많이 받은 모델들도 일부 앞서기도 하였다.
Ablation Study

THUMOS 데이터셋에서의 비교 실험을 수행하였다. Baseline은 일반적인 MIL 설정으로, 별도의 background class가 없는 Base Branch를 생각하면 된다. Base branch는 추가 background class를 넣은 base branch로, 오히려 성능이 감소하였다. 이는 negative sample이 없는 background class에 대해 모델이 항상 높은 점수를 주기 때문으로 보았다. Suppression branch는 base 브랜치가 없는 버전으로, 이때 필터링 모듈은 일종의 어텐션처럼 작동한다고 한다. 이 경우 베이스라인 대비 성능이 향상되지만, 저자들은 background class에 대한 positive sample이 없기 때문에 이것이 background modeling을 통한 것은 아니라고 보았다.
BaS-Net은 두 브랜치를 통해 background class를 학습시킴으로써 성능을 크게 향상하였다.
Qualitative Results
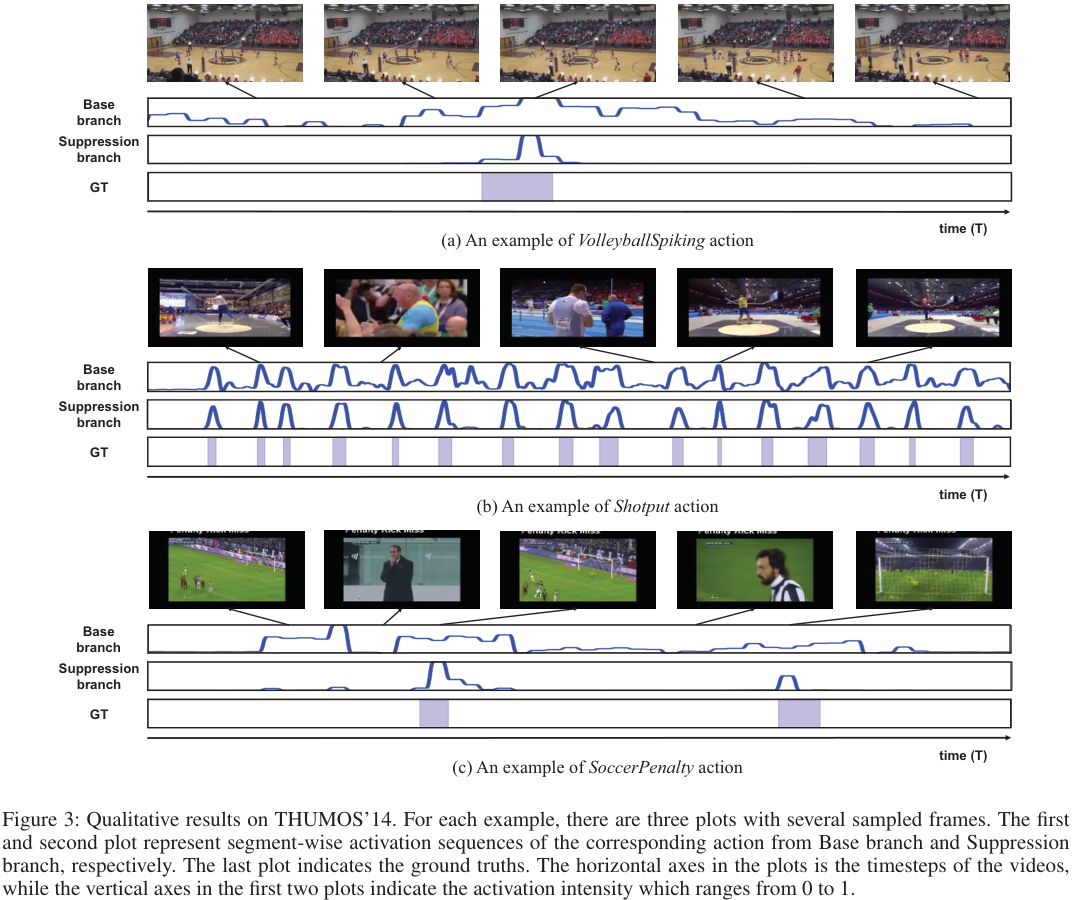
(a)는 사람이 매우 작게 보이고, 액션이 일어나는 프레임과 background의 차이가 미미하여 어려운 경우이지만 background suppression이 잘 일어나고 있음을 볼 수 있다. (b)는 액션이 매우 빈번하게 발생하는데, 역시 그런 상황에서도 정확하게 background와 액션을 나누고 있다. (c)는 background와 액션 영역의 구분이 시각적으로 어려운 샘플이나 역시 잘 구분한다고 한다.
결론
이 논문에서, 저자들은 Weakly-supervised temoral action localization을 더 잘하기 위해 background의 구분이 필요하다고 보았다. 이를 위해 backgrond class를 추가하여 모델이 액션이 일어나고 있는 장면과 그렇지 않은 장면을 명확히 구분하도록 하였고, 덕분에 큰 성능 향상을 달성할 수 있었다.
temporal annotation이 없는 상황에서, 두 개의 가중치를 공유하는 브랜치를 통해 background에 대한 positive / negative sample을 생성하고 이를 학습하도록 한 점이 매우 창의적인 것 같다.
이제 이 논문을 구현해 보며 TAL을 실제로 다뤄볼 예정인데, 어려울 것 같으면서도 기대된다. ㅎㅎ