VVS: Video-to-Video Retrieval with Irrelevant Frame Suppression 리뷰
대규모 데이터를 다루는 콘텐츠 기반 비디오 검색(CBVR) 연구에서 효율성은 정확도만큼이나 중요하다. 그렇기에 지금까지 많은 Video-level feature 기반 연구가 진행되었지만, 긴 영상을 자르지(trim) 않고 하나의 feature로 만드는 것의 어려움으로 인해 지금까지는 Frame-level feature 기반 연구에 비하여 충분한 성과가 없었다.
이 논문에서, 저자들은 서로 무관한 프레임들을 적절히 suppression 하는 것이 video-level feature 기반 연구의 한계를 극복할 단서가 될 수 있음을 보이며, 나아가 Video-to-Video Suppression network(VVS)를 해법으로 제시한다.
Introduction
정보 검색(Information Retrieval)은 대규모 데이터 집합에서 가장 관련된 정보를 찾아내는 Task이다. 문서에서 특정한 텍스트를 찾는 것에서 시작되어, 이미지 집합에서 이미지를 찾아내는 task를 거쳐, 최근에는 콘텐츠를 기반으로 비디오를 찾아내는 CBVR까지 분야가 발전하였다.
CBVR 기술의 핵심은 서로 다른 길이의 비디오들 사이의 거리를 계산하는 것이라 할 수 있다. 두 비디오의 거리를 측정하는 이 기술은 크게 두 가지로 나누어지는데, 프레임 수준의 feature를 비교하는 방법과 비디오 전체 수준의 feature를 비교하는 방법이다.
프레임 수준에서 영상들을 비교하게 되면 영상의 길이나 영상이 트림(trim)되었는지 여부에 영향을 적게 받으면서 효과적으로 영상들을 비교할 수 있다. 덕분에 높은 정확도를 낼 수 있지만, 매우 많은 메모리 용량과 연산량을 필요로 하게 된다.
한편 영상 수준에서 영상들을 비교하게 되면 단 한번의 유사도 비교 연산만이 수행되어 연산량과 메모리 사용량이 크게 감소한다. 그러나, 영상 전체를 하나의 feature로 압축하는 것이 매우 어렵기 때문에 좋은 정확도를 얻기 어렵고, 영상의 길이나 트림 여부의 영향을 많이 받게 된다.
이상적으로는 영상 수준의 비교가 현실의 문제를 해결하기에 적합하겠으나, 아직까지는 해결해야 할 문제가 많은데, 대표적인 것이 영상의 주제와 무관한 프레임(Distractors)들이다.
논문에서는 정량적 분석을 통해 영상 주제와 무관한 프레임들을 제거하는 것이 비디오 검색 성능 향상에 도움이 됨을 보였다.
이 논문은 좋은 영상 수준의 feature들을 만들기 위해 어떤 프레임들을 제거해야할지 이해하는 것을 목표로, 이를 위한 end-to-end 모델인 VVS를 제안한다. VVS는 두 가지 단계로 구성된다.
- 쉽게 판단할 수 있는 distractor들의 제거하는 과정
- 1.을 수행하고 남은 프레임들의 제거 여부를 결정하는 가중치를 생성하는 과정
기존 모델들이 묵시적으로 프레임 제거를 위한 가중치를 생성한 것과 반대로 VVS는 명시적으로 이러한 가중치를 생성한 첫 모델이다.
VVS는 비디오 수준 특성 기반 모델을 이용한 CBVR task의 정확도 SOTA를 달성하였고, 동시에 프레임 수준 특성 기반 모델들과 비슷한 정확도를 내면서도 속도에서 5.7배 향상을 보였다.
논문의 contributions
- 적절한 frame suppression을 사용하면 비디오 수준 특성 기반 모델이 좋은 정확도와 속도를 보일 수 있음을 확인
- 다양한 신호를 사용해 frame suppression을 수행하고, 트림되지 않은 비디오를 feature로 임베딩하는 end-to-end 모델 VVS 제안
- 광범위한 실험을 통한 VVS 모델의 효과 입증, SOTA 달성
Related Work
Frame-level Feature 기반 방법
다이나믹 프로그래밍(DP) 방법은 frame-level similarity map의 대각 성분을 추출하여 Near-duplicate 영역을 검출한다. Temporal Network는 keypoint frame으로 구성된 그래프의 최장 경로를 이용해 두 영상 간의 시각적 유사도를 분석한다. Circulant Temporal Encoding(CTE)은 푸리에 변환을 이용해 frame-level feature를 비교한다. Video Similarity Learning(ViSiL)은 프레임 간 similarity map을 이용한 메트릭 러닝 기법을 활용한다. Compact Descriptors for Video Analysis(CDVA)는 두 종류의 transformation-resistant 키프레임 피쳐를 얻어 그들을 상호보완적으로 활용한다.
이런 방법들은 일반적으로 video-level feature 기반 방법에 비하여 더 정확한 검색 결과를 제공하지만, 그만큼 실행 시간도 상당히 증가하게 된다.
Video-level Feature 기반 방법
Hashing Code(HC)는 정확하고 scalable 한 처리를 위해 대량의 local, global feature를 해싱한다. Deep Metric Learning(DML)은 iMAC 기법으로 생성된 layer codebook 형태의 frame-level feature들을 융합해 video-level feature를 생성한다. Temporal Matching Kernel(TMK)은 frame descriptor와 timestamp를 고려하는 periodic kernel들을 이용해 영상이 가진 프레임의 수와 무관하게 고정된 길이의 시퀀스를 생성한다. Learning to Align and Match Videos(LAMV)는 TMK 기반의 학습가능한 feature transform coefficient를 만든다. Temporal Context Aggregation(TCA)은 셀프 어텐션과 큐 기반 학습 메커니즘을 통해 frame-level feature를 video-level feature로 변환한다. Video Region Attention Graph(VRAG)는 frame 내부의 region unit들의 관계를 포착하여 video를 임베딩하는 방법을 graph 어텐션 계층을 통해 학습한다.
일반적으로 이런 방법들은 frame-level feature 기반 방법들에 비하여 더 빠르지만, 상대적으로 더 부정확하다. 그러나 이 방법에 속하는 VVS는 frame-level feature 기반 방법들만큼이나 정확하면서도 충분히 빠른 속도로 동작한다. 특히, VVS와 유사한 방법인 DML, TCA, VRAG들은 각각 완전연결 계층, 셀프 어텐션 계층, 그래프 어텐션 계층을 통해 묵시적으로 frame-level feature들을 video-level feature로 융합하는데 비해(이는 융합된 feature의 대조적 손실 함수만이 목적 함수로 사용됨을 의미한다.) VVS는 low-level characteristiccs, temporal saliency, topic 등을 활용해 명시적으로 video-level feature를 생성한다.
Approach
Preliminaries
텐서 닷(Tensor Dot, TD) 연산은 주어진 두 텐서 $\mathcal{A, B} \in \mathbb{R}^{T\times S^2\times C}$의 특정한 축에 대한 덧셈으로 정의된다. $T, S, C$는 각각 동영상의 시간, 공간, 채널 축을 의미한다. 이 논문에서는 오로지 채널 축으로만 TD 연산을 수행하므로, TD 연산은 $\mathbb{R}^{T\times S^2\times S^2 \times T}$ 크기의 출력을 갖는다.
Chamfer Similarity(CS) 연산은 주어진 행렬 $\mathcal{D}\in \mathbb{R}^{N\times M}$의 각 열들의 최댓값들의 평균이다. 만약 주어진 데이터 $\mathcal{D}$이 $\mathbb{R}^{T\times S^2 \times S^2 \times T}$의 크기를 갖는다면 출력은 $\mathbb{R}^{T\times T}$ 크기가 되며, 이에 대해 다시 연산을 수행하면 출력은 $\mathbb{R}^{1}$ 크기가 된다.
$$ CS(\mathcal{D}) = \frac{1}{N}\sum^N_{i=1} \max_{j\in [1, M]} \mathcal{D}^{(i,j)}$$
시공간 글로벌 에버리지 풀링(Spatio-Temporal Global Average Pooling, ST-GAP)은 주어진 텐서 $\mathcal{A}\in \mathbb{R}^{T\times S^2\times C}$의 시간 및 공간 축에 대하여 global average pooling을 수행하여 $\mathbb{R}^C$ 크기의 출력을 만든다. 유사하게, 공간 글로벌 에버리지 풀링(Spatial Global Average Pooling, S-GAP)은 공간 축에 대한 풀링을 수행해 $\mathbb{R}^{T\times C}$ 크기의 출력을 만든다. 이런 연산들 후에는 L2 normalization을 통해 텐서들 간의 스케일 차이를 조정한다.
대각 샘플링(Diagonal Sampling, DS)은 주어진 정방행렬 $\epsilon \in \mathbb{R}^{T\times T\times C}$의 대각 성분들을 추출한다. 이 논문에서 이 연산은 항상 3개의 축을 가진 텐서에 적용되며, 출력은 $\mathbb{R}^{T\times C}$ 크기가 된다.
VVS Pipeline

길이 $T$의 영상이 주어졌을 때, 우리는 distractor 프레임들을 억제하면서 영상을 크기 $V$의 video-level feature로 만들고자 한다. 어떤 프레임을 얼마나 억제할지 결정하기 위해, 영상의 각 프레임들은 video-level feature $V$로 바로 변환되지 않고 먼저 frame-level features $X=\{x^{(t)}\}^T_{t=1}$로 임베딩된다. 그다음, 정보의 부족으로 쉽게 구분되는 easy distractor들을 제거한다.(easy distractor elimination) 그 후, 억제 가중치 생성 단계에서 남아있는 $T'$개의 프레임들의 필요도(necessary degree)를 의미하는 가중치 $W=\{ w^{(t)} \}^{T'}_{t=1}$를 생성한다. 마지막으로 이 가중치를 활용하여 frame-level feature들을 video-level feature로 누적하는 과정을 거친다. $V=\Psi (\{ w^{(t)} \otimes x^{(t)} \}^{T'}_{t=1})$ 이 식에서 $\Psi$가 ST-GAP, $\otimes$가 element-wise multiplication(아다마르 곱)을 뜻한다.
특성 추출
먼저, 각 프레임에서 $\text{L}_N\text{-iMAC}$ 방법으로 frame-level feature를 추출한다. 각 프레임은 백본 신경망 $\Phi$에 입력되고, 이 신경망의 중간 합성곱 계층들이 생성하는 feature map $\mathcal{M}^{(k)}\in \mathbb{R}^{S^2\times C^{(k)}(k=1, \cdots, K)}$들로부터 R-MAC이 추출되어 $\text{L}_N\text{-iMAC}$을 구성한다. 각 계층으로부터 동일한 $S^2$크기의 R-MAC feature가 추출되기 때문에, 이들을 채널 축으로 쌓으면 frame-level feature $x\in \mathbb{R}^{S^2\times C}$($C$는 합성곱 계층들이 생성한 feature map들의 채널들의 수의 합)을 얻을 수 있다. 각 $x$들에 PCA Whitening을 적용하면 $\text{L}_N\text{-iMAC}$ feature $X\in \mathbb{R}^{T\times S^2 \times C}$를 얻을 수 있다. PCA 과정에서 채널의 수 $C$가 변할 수 있지만, 편의상 이 논문에서는 $C$로 나타내었다고 한다.
Easy Distractor 제거 단계
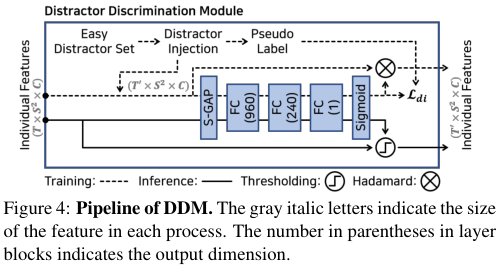
이 단계에서는 Distractor Discrimination Module(DDM)을 이용해 시각 정보가 적어 명백하게 distractor로 판단되는 프레임들을 제거한다. easy distractor는 픽셀을 비롯한 저수준 특성(엣지, 코너 등)들이 적은 프레임들을 의미한다. DDM의 학습 과정에서, easy distractor에 해당하는 프레임들의 frame-level feature들이 길이 $T$의 입력 영상에 삽입되며 DDM은 이들을 구분할 수 있도록 학습된다. 추론 단계에서 DDM은 이런 프레임들을 감지하며, 감지된 프레임들은 입력 영상에서 제거된다. 편의를 위해 DDM의 출력 길이는 항상 $T'$로 나타내겠다.
Distractor Discrimination Module이 easy distractor들을 잘 구분할 수 있도록 학습시키기 위해, 저자들은 frame-level feature들의 크기(magnitude)를 이용해 pseudo label을 생성한다. 적은 양의 저수준 정보를 가진 프레임들은 백본 신경망의 합성곱 계층에서 더 적은 값들을 활성화시키고, 이는 결국 $\text{L}_N\text{-iMAC}$의 크기가 작게 만들기 때문이다.

학습에 앞서, 학습 데이터 중 임계값 $\lambda_{mag}$ 이하의 크기를 갖는 프레임들을 사용해 easy distractor set을 구성한다. 학습 과정에서 이 set에 포함된 easy distractor를 랜덤 하게 frame-level features $X$에 섞어 넣는다. 논문에서는 $T$의 $20-50%$ 정도에 해당하는 양이 주입되었다. 이렇게 distractor가 주입된 프레임에 해당하는 pseudo label $Y_{di} = \{ y_{dt}^{(t)} \}^{T'}_{t=1}$를 0으로 설정하고, distractor가 주입되지 않은 원래 영상의 영역에는 1로 설정한다. 주입된 feature들은 DDM의 FC 계층들을 거쳐 confidence score $W_{di}=\{ w_{di}^{(t)} \}_{t=1}^{T'}$로 변환된다. 이는 이진 크로스 엔트로피 손실 함수 $\mathcal{L}_{di}$에 입력되어 학습된다.
DDM의 목적은 다음 신경망에 입력될 프레임을 선별하여 전달하는 것이다. 그러나 thresholding 연산이 미분 불가한 관계로, 학습 단계에서 DDM은 easy distractor로 판단되는 프레임을 제거(thresholding)하는 대신 element-wise 곱을 통해 confidence를 곱한다. 한편, 추론 단계에서 DDM은 임계값 $\lambda_{di}$보다 낮은 $W_{di}$를 가진 프레임들을 제거한다.
억제 가중치 생성 단계
이전 단계에서 easy distractor들을 제거하기는 하였지만, untrimmed video는 여전히 hard(어려운) distractor들을 포함하고 있다. 이 단계에서는 시간적 중요도 모듈(Temporal Saliency Module, TSM)과 주제 지도 모듈(Topic Guidance Module, TGM)을 통해 억제 가중치(suppression weights)를 생성하여 남은 프레임들이 얼마나 hard distractor인지 판단하도록 할 것이다. TSM은 프레임 수준 유사도로부터 얻어진 중요도 정보(saliency information)를 통해 각 프레임이 갖는 중요성을 평가하고, TGM은 영상의 주제와 각 프레임이 관련된 정도를 측정한다. 각 모듈에서 얻어진 가중치는 suppression weight $W$로 변환되어 element-wise 곱을 통해 frame-level feature들에 반영된다.
시간적 중요도 모듈 (Temporal Saliency Module)
각 프레임의 중요도를 평가하기 위해, 학습 과정에서 Saliency Information이 추출된다. 이는 학습 과정에서 frame-level 유사도맵을 추출하고 CS 연산을 통해 frame-level 유사도를 누적하는 ViSiL에서 영감을 받은 방법이다. 우리는 최댓값을 우선시하는 CS 연산이 모델이 학습됨에 따라, positive pair 간의 frame-level 유사도 맵 상에서 video-level 유사도를 증가시키는 위치의 값을 증가시킴을 발견했다. 영상 간의 유사도를 증가시키기 위해 값이 증가하는 영역은 유관한 주제의 영상들을 판단하는데 중요한 프레임들을 의미한다. 그러므로 Saliency Information은 이러한 영역에 포함되어 있다고 볼 수 있다.
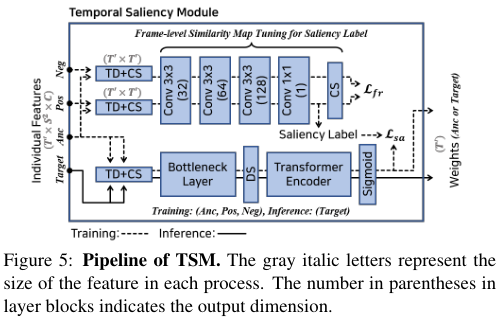
즉, 이 모듈은 이런 saliency information을 포함한 프레임들을 pseudo-label에 주입하여 각 프레임의 중요도가 측정될 수 있도록 모델을 유도한다. 먼저 ViSiL과 유사하게 frame-level 유사도를 계산한다. 먼저 트리플렛 형태에 따라 앵커, positive, negative 샘플로 구성된 3개의 frame-level feature($\mathbb{R}^{T'\times S^2\times C}$)들이 주어진다. 앵커와 positive 쌍 간의 TD 연산이 수행되어 $\mathbb{R}^{T'\times S^2 \times S^2 \times T'}$ 크기의 출력을 얻고, CS 연산을 수행하여 $\mathbb{R}^{T'\times T'}$ 크기의 frame-level 유사도 맵을 얻는다. 앵커와 negative 쌍에도 같은 방법으로 유사도 맵을 얻는다. 여기서 유사도 맵의 각 행은 앵커의 프레임의 인덱스에 해당된다. 두 유사도 맵은 각각 여러 계층의 신경망을 거쳐 $\mathcal{D}_p, \mathcal{D}_n \in \mathbb{R}^{T''\times T''}$ 크기로 조정(tune)된다. ($\mathcal{D}_p$은 앵커와 positive 쌍과의 유사도 맵, $\mathcal{D}_n$은 negative 쌍과의 유사도 맵을 의미하며, $T''$는 축소된 유사도 맵의 크기이다.) 이 유사도 맵들의 CS 연산 후 계산된 triplet margin loss는 합쳐져 regularization loss로 사용되어 이 tuned map들이 발산하지 않도록 한다. (그림에 $\mathcal{L}_{fr}$로 표기) frame-level 유사도 맵의 튜닝 과정에서 positive 쌍의 유사도 맵 $\mathcal{D}_p$ 상의 saliency information을 가지고 있는 영역들은 더욱 강조되게 된다. pseudo-label $Y_{sa}$는 이를 이용해 생성된다.
$$ \rho_i = \max_{j\in[1, T'']} \mathcal{D}_p^{(i,j)}, \\
\rho = [\rho_1, \rho_2, \cdots, \rho_i, \cdots, \rho_{T''}]^T, \\
Y_{sa} = H(\rho - \frac{1}{T''}\sum^{T''}_{i=1} \rho_i) \in \mathbb{R}^{T''}$$
$H$는 단위 계단 함수(heaviside step function)으로, 0보다 작은 값에 0, 0에 1/2, 0보다 큰 값에 1을 부여한다.
$\rho$는 앵커 영상의 각 프레임에 대하여 가장 높은 유사도를 가진 positive 영상의 프레임의 유사도를 의미한다. $\rho$의 평균은 positive score, 즉, positive 쌍 간의 video-level 유사도이다. saliency label은 이 $\rho$ 값이 평균 이상으로 높은, 앵커 영상 속 프레임과의 유사도가 비디오 간의 유사도 이상으로 높은 프레임들에 대해 1, 그렇지 않은 프레임에 대해 0을 pseudo-label로 부여하여 특히나 영상 유사도 증가에 기여하고 있는 프레임들을 라벨링 한 $Y_{sa}$를 생성한다.
saliency label 생성 과정을 거친 후, 똑같은 앵커 영상 간의 TD, CS 연산을 통해 self-similarity map을 생성한다. 이는 병목 계층과 트랜스포머 인코더를 거쳐, 시그모이드 함수를 통해 saliency weight $W_{sa} = \{w_{sa}^{T'} \}^{T'}_{t=1}$로 가공된다. 이때, 트랜스포머 인코더의 입력을 변환하기 위해 DS가 적용된다. 마지막으로 saliency Loss $\mathcal{L}_{sa}$이 이진 크로스 엔트로피 함수를 통해 $W_{sa}, Y_{sa}$를 비교하여 계산된다. (이때, $T'$ 크기를 맞추기 위해 nearest interpolation이 적용된다.)
학습 과정에서 TSM은 $\mathcal{L}_{fr}, \mathcal{L}_{sa}$로 학습되며 추론 과정에서는 오직 self-similarity map을 통해 생성된 saliency weight만을 생성한다.
주제 지도 모듈 (Topic Guidance Module)
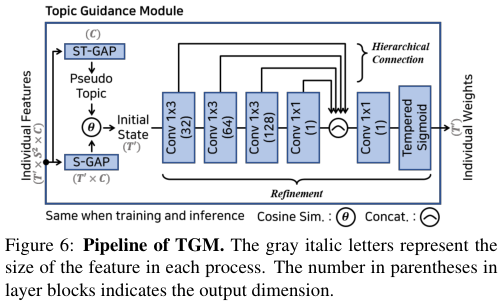
untrimmed video의 특성상, 영상 안에는 영상의 주제와 무관한 프레임들(예를 들어 뉴스 앵커의 설명, 편집 효과 등)들이 포함된다. 저자들은 영상 전체에 대해 시공간 글로벌 에버리지 풀링(ST-GAP)을 통해 영상의 주요 성분들만을 담은 pseudo topic $G\in \mathbb{R}^C$를 추출한다. 그다음, 영상의 시간 축을 남기고 공간 축에 대하여 글로벌 에버리지 풀링(S-GAP)을 수행해 $T'\times C$ 크기의 행렬을 얻고, 각 프레임과 $G$ 사이의 코사인 유사도를 구하여 초기 상태 $I\in \mathbb{T'}$를 얻는다. 이는 즉, $T'$개의 각 프레임이 영상의 주된 내용(주제)과 얼마만큼 유사한지를 대략적으로(rough) 나타낸다.
이 초기 상태를 신경망에 입력하여 정제함으로써 더욱 상세하게(coarse) 각 프레임이 영상의 주제와 얼마나 유관했는지를 나타내는 가중치 $W_{gu}=\{w_{gu}^{(t)}\}^{T'}_{t=1}$를 생성한다. 신경망은 위 그림처럼 $1\times 3$ 크기의 합성곱 커널을 통해 인접한 프레임들을 살펴보고, 최종적으로 $1\times 1$ 합성곱 커널을 통해 채널 수를 축소한다. 여러 계층을 쌓음으로써 receptive field는 점차 커지게 되는데, 이렇게 각기 다른 receptive field를 갖는 feature map들을 concat 하고 $1\times 1$ 커널을 한번 더 통과하여 출력 가중치를 만든다. 이 모듈은 활성화 함수로 tempered sigmoid를 사용하여 노이즈로부터 강건하게 가중치를 학습한다.
Video Embedding & Training Strategy
학습 단계에서, 각 트리플렛의 frame-level feature들은 억제 가중치 $W$와의 element-wise 곱(아다마르 곱)을 통해 video-level feature $V\in \mathbb{R}^C$로 누적된다. 이때, TSM은 positive와 negative 샘플에 대한 가중치를 다루지 않기 때문에 이들에 대해서는 오직 $W_{gu}$ 가중치만이 사용된다. 그 결과, $\mathcal{L}_{vi}$는 세 video-level feature들 간의 triplet margin loss로 계산된다. 전체 손실 함수는 아래 식과 같이 계산된다.
$$\mathcal{L} = \mathcal{L}_{vi} + \mathcal{L}_{fr} + \mathcal{L}_{sa} + \alpha\mathcal{L}_{di}$$
$\alpha$는 DDM의 학습 속도를 조절하는 파라미터로, 해당 모듈이 다른 모듈들에 비해 빠르게 학습되기 때문에 도입되었다. 이와 관련한 내용은 저자들이 supplementary에 적어 놓았다고 하는데, 분량이 ㅎㄷㄷ하여 요약에 담지는 못하였다.
Experiments
저자들은 두 가지 환경에서 실험을 진행하였는데, 흔히 사용되는 콘텐츠 기반 영상 검색 task인 FIVR(fine-grained incident video retrieval)과 NDVR(near-duplicate video retrieval)이다. 성능은 mAP로 측정하였고, 학습 데이터에는 VCDB, 테스트 데이터로는 FIVR과 CC_WEB_VIDEO를 사용하였다.
다른 방법론들과의 비교
video-level feature $V$의 채널 수 $C$에 따라, 저자들이 제안한 방법을 $\text{VVS}_C$로 표기하였다. $C$는 PCA 과정에서 frame-level feature $X$의 차원이 얼마나 축소되느냐에 따라 달라지는데, 축소가 적용되지 않으면 $\text{VVS}_{3840}$, 축소가 적용된 정도에 따라 $\text{VVS}_{500}, \text{VVS}_{512}, \text{VVS}_{1024}$를 실험했다.
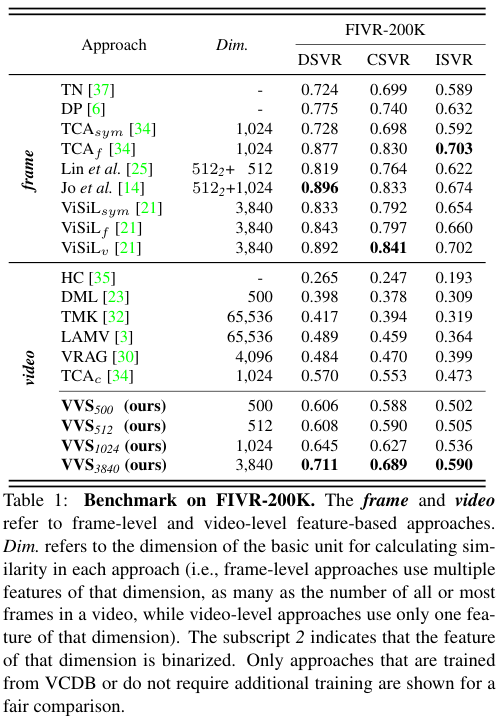
표 1은 FIVR-200K 대규모 데이터셋에서의 기존 SOTA 모델들과의 비교를 보여준다. 이 데이터셋에서 $\text{VVS}_{3840}$은 모든 video-level 방법들보다 약 $25%$ 높은 성능을 보여 frame-level 방법에 가까운 성능을 내었고, $\text{VVS}_{500}, \text{VVS}_{512}, \text{VVS}_{1024}$는 다른 video-level 방법들과 비슷하거나 더 적은 차원을 사용하고도 SOTA 성능을 내었다. 이러한 경향은 표 2의 CC_WEB_VIDEO 데이터셋에서도 유사하게 드러났다.
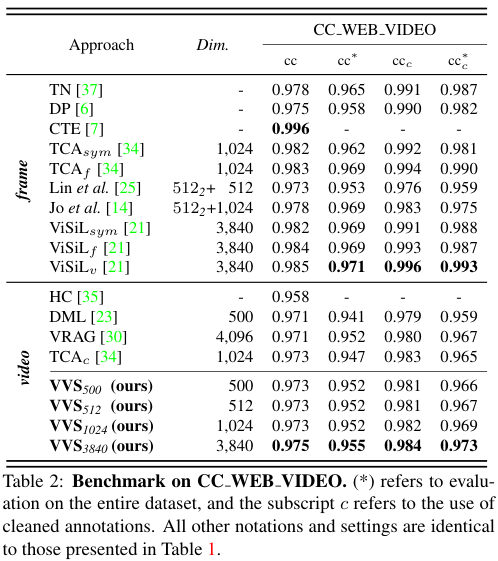
video-level 방법론들이 frame-level 방법론들에 비해 근본적으로 메모리와 속도 면에서 앞서는 것을 고려하면, 저자들이 제안한 VVS가 가장 효율적인 모델임을 알 수 있다.
Ablation Studies
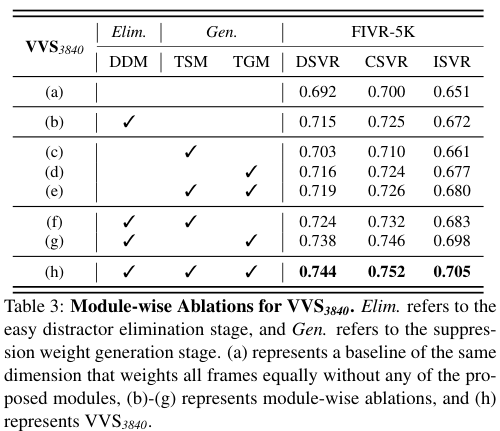
표 3은 VVS의 각 모듈이 각각 비슷한 수준으로 성능을 향상함을 보여준다.
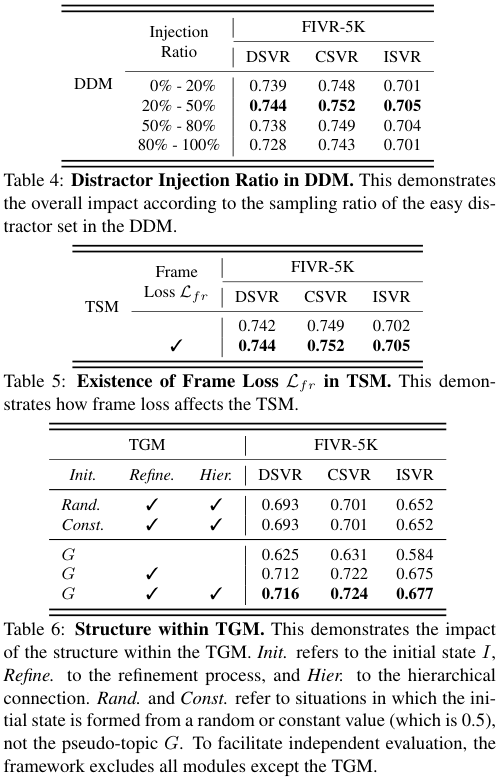
표 4-6 은 모델의 각 요소가 성능에 미치는 영향을 보여준다.

그림 7을 통해 모델이 실제로 잘 작동함을 볼 수 있는데, 영상에서 주제와 무관한 프레임들에는 낮은 가중치를 부여하고, 주제와 유관한 프레임들에 대해 높은 가중치를 부여하고 있음을 확인할 수 있다.
Conclusion
이 논문에서는 untrimmed video에서 video-level feature를 만들 때, 무관한 프레임들을 적절히 제거하는 것들이 매우 중요함을 보였다. 또한 이를 위해 end-to-end framework인 VVS를 제안하였는데, easy distractor를 제거하는 DDM, 각각 saliency information과 topic relevance를 기준으로 제거할 프레임을 선별하는 TSM, TGM 등의 모듈을 포함한다. 이는 이전 방법들과 달리 명시적으로 프레임 억제를 위한 모듈들을 학습시킨 첫 시도이며 이를 통해 뛰어난 메모리 효율성과 속도로 높은 정확도의 영상 검색을 수행하는 결과를 보였다.
Supplementary Material
Additional Details
Implementation Details
- 각 영상은 초당 1 프레임으로 샘플링 되었다.
- 학습 과정에서 영상 당 프레임의 수는 $T=64$로 설정되었지만, 추론 과정에서는 영상의 길이에 따라 다르게 하였다.
- $\text{L}_N\text{-iMAC}$에서 백본 신경망 $\phi$는 ResNet50을 사용하였다.
- 계층의 수 $K$는 4였고, region kernel의 수 $N$도 4였다.
- 학습에 사용된 easy distractor 집합은 VCDB 데이터셋에 포함된 10만 개의 metadata-free 영상들로부터 추출되었다.
- magnitude threshold $\lambda_{mag}=40$으로 하여 추출했다.
- DDM의 threshold값 $\lambda_{di}$는 0.5로 하였다.
- TGM의 tempered sigmoid의 temperature는 512로 하였다.
- discrimination loss를 조절하는 $\alpha$값은 0.5로 하였다.
- frame loss와 video loss에 관여하는 margin도 0.5로 하였다.
- PCA는 VCDB의 metadata-free 영상들에서 점진적으로 학습되었다.
- 정확한 비교를 위해 속도와 관련된 실험들은 모두 동기적으로(synchronously) 진행되었다.
- pytorch에서의 CUDA call은 근본적으로 비동기적이다.
- total inference time은 model operation time, similarity calculation time, evaluation time 들을 포함한다.
- 논문에서 별도로 언급하지 ($\text{VVS}_{500}, \text{VVS}_{512}$ 등) 않는다면, 실험에는 기본적으로 $\text{VVS}_{3840}$이 사용되었다.
Training Strategy Details
학습은 Adam 옵티마이저로진행되었고, learning rate는 $2\times10^{-5}$로 고정되어 2000 iterations에 60 epoch 진행되었고, 이 중에 최고의 모델이 FIVR-5K 에서의 mAP로 선택되었다. VCDB의 데이터가 학습 과정에서 tiplet으로 사용되었다. DDM은 frame-level feture들을 PCA없이 입력받아 백본 신경망의 어떤 계층이 low-level characteristics를 출력했는지 판단한다.
Formulas Details
Discrimination Loss
판별 손실 $\mathcal{L}_{di}$은 confidence $W_{di}=\{w_{di}^{(t)}\}^{T'}_{t=1}$와 pseudo-label $Y_{di}=\{y_{di}^{(t)}\}^{T'}_{t=1}$간의 이진 교차 엔트로피이다. 이는 DDM이 easy distractor를 올바르게 판단했는지 평가한다.
$$\mathcal{L}_{di} = \frac{1}{T'}\sum^{T'}_{t=1}y_{di}^{(t)}\log(w_{di}^{(t)}) + (1-y_{di}^{(t)})\log(1-w_{di}^{(t)}). $$
Frame Loss
$\mathcal{L}_{fr}$은 TSM에서 saliency information을 다룰 때 사용되며, 유사도 맵을 위해 조정된 triplet margin loss와 regularization loss의 합이다. Triplet margin loss $\mathcal{L}_{tri}$은 tuned similarity map인 $\mathcal{D}_p, \mathcal{D}_n$간의 triplet margin loss로 다음과 같다.
$$ \mathcal{L}_{tri} = \max \{ 0, CS(\mathcal{D}_n) - CS(\mathcal{D}_p) + \gamma\} $$
$\gamma$는 margin이고, regularization loss $\mathcal{L}_{reg}$은 두 유사도 맵 간의 발산 제약(Divergence Constraint)으로 나타내었다.
$$ \psi(\mathcal{D}) = \sum | \max \{0, \mathcal{D} - J\} | + | \min \{0, \mathcal{D} + J |, \\
\mathcal{L}_{reg} = \psi(\mathcal{D}_p) + \psi(\mathcal{D}_n) $$
$0, J$는 각각 입력 $\mathcal{D}$와 동일한 크기의 0과 J로 채워진 행렬을 의미한다. frame loss $\mathcal{L}_{fr}$은 다음과 같은 weighted sum 형태로 나타난다.
$$ \mathcal{L}_{fr} = \mathcal{L}_{tri} + 0.5 * \mathcal{L}_{reg}$$
Saliency Loss
$\mathcal{L}_{sa}$는 saliency weight $W_{sa} = \{ w_{sa}^{(t)} \}^{T'}_{t=1}$와 saliency label $Y_{sa}=\{ y_{sa}^{(t)} \}^{T'}_{t=1}$ 간의 이진 교차 엔트로피로, TSM에서 각 프레임의 중요도를 평가하는데 사용한다.
$$\mathcal{L}_{sa} = \frac{1}{T'}\sum^{T'}_{t=1} y_{sa}^{(t)} \log(w_{sa}^{(t)}) + (1-y_{sa}^{(t)})\log (1-w_{sa}^{(t)}). $$
Video Loss
video loss $\mathcal{L}_{vi}$은 tiplet의 video-level feature 간의 triplet margin loss이다.
$$\mathcal{L}_{vi} = \max \{ 0, \theta(V, V^-) - \theta(V, V^+) + \gamma \}$$
$V, V^-, V^+$는 각각 triplet의 anchor, positive, negative 샘플의 video-level feature들이며 $\theta$는 코사인 유사도 이다. $\gamma$는 마진이다.
이 논문의 방법이 이 모든 손실함수들을 동시에 최적화하기 때문에, VVS는 "end-to-end framework"라 할 수 있다. 이때, MAC 특성을 추출하는 백본 신경망은 학습을 진행하지 않음에 유의해야 한다.
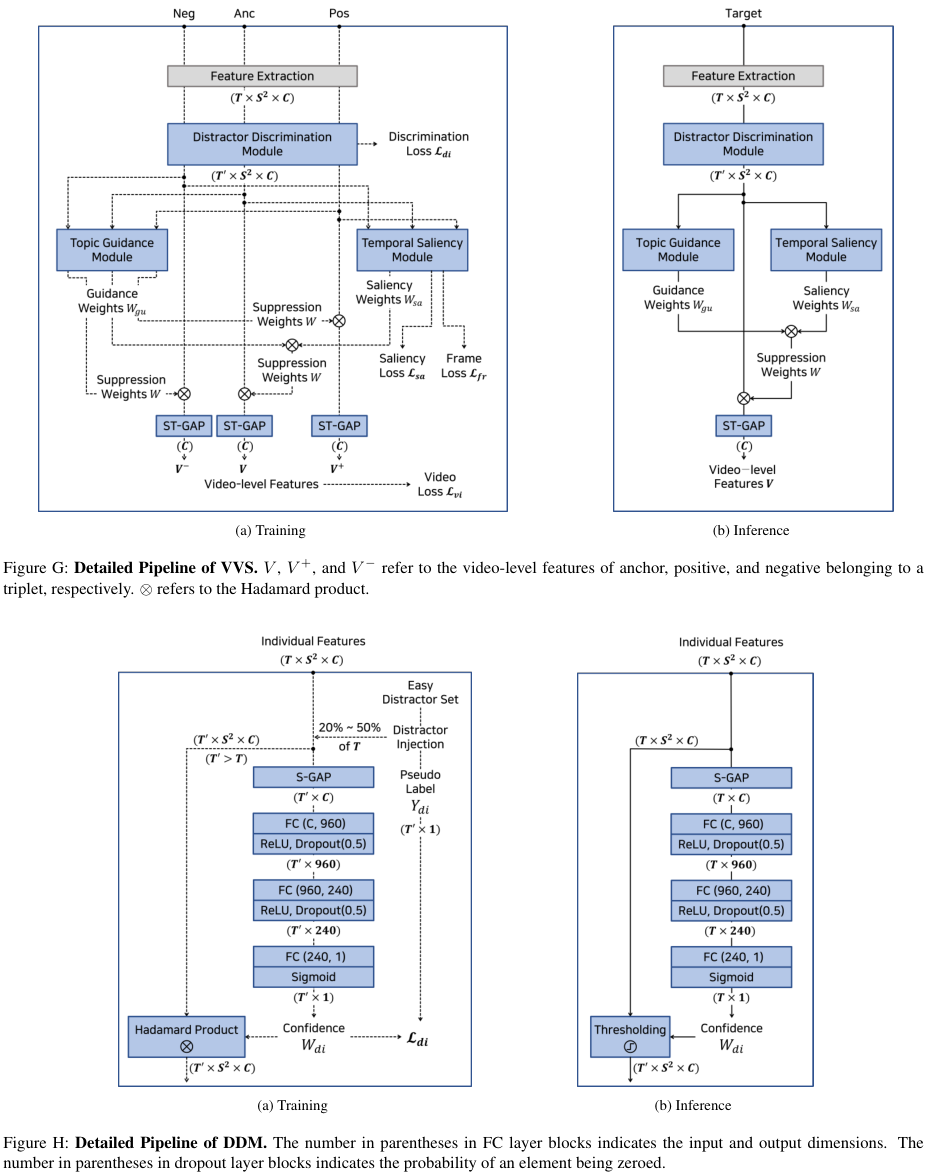
Architecture Details
그림 G는 전체 프레임워크의 상세한 흐름을 나타내고, 그림 H, I, J는 각각 DDM, TSM, TGM의 상세 구조를 나타낸다.
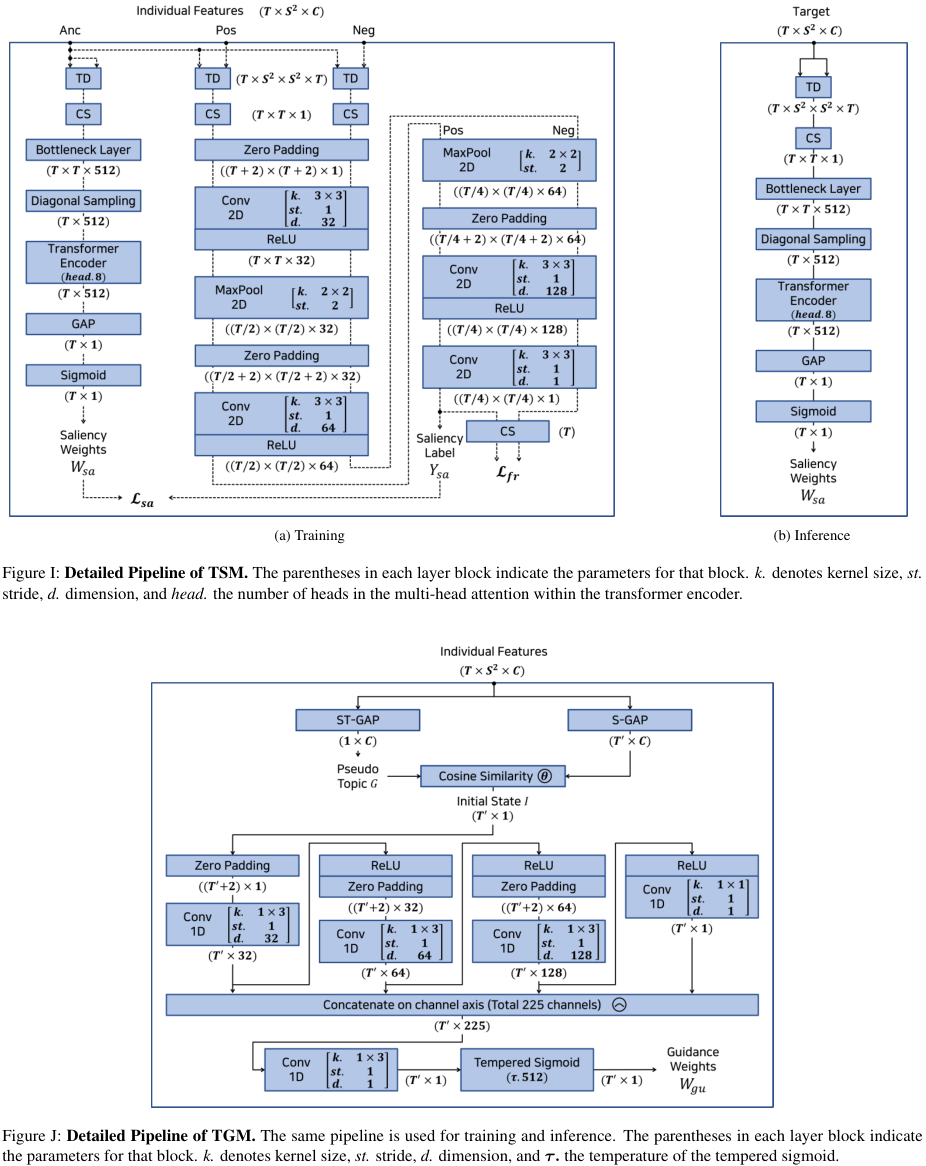
Additional Ablation Studies & Analyses
Quantitative Experiment on Ideal Suppression
이 문단에서는 video-level feature를 만들 때 무관한 프레임들을 억제하는 것의 중요성을 실험하고, 수동적으로나마 이들을 억제하여 기존 방법론들이 얼마나 성능 향상을 이룰 수 있는지 알아본다. 실험은 FIVR-5K에서 수행되며, temporal annotation을 통해 distractor들을 제거하였다. 그림 A에서 볼 수 있듯이 temporal annotation은 각 영상의 어떤 부분이 다른 영상의 어떤 부분과 연관이 있는지 상세히 기록되어있다.

temporal annotation은 N, S, H, F로 구성되는데, N은 영상의 해당 부분이 쿼리 영상과 촬영 각도, 시각 모두 비슷함을 의미하고, S는 시간적 유사함, 즉, 같은 사건을 다른 각도에서 촬영한 것을 의미한다. H는 촬영 각도와 시간 모두 다르지만 의미론적으로 유사한 것을 말하고, F는 인접한 시간에서 Fading 편집 효과가 들어간 영역이다. 아무런 라벨도 부여되지 않은 영역은 distractor들로, 영상의 주제와 관계없는 영역들이다.
FIVR-5K의 영상 중 1981개의 영상들이 temporal annotation을 활용하여 distractor들을 제거한 후 사용되었고, 나머지 3069개의 영상들은 원래대로 사용되었다. 이 실험에서 사용된 temporal annotation이 모델의 예측으로부터 얻어진 것이기 때문에, 이 결과는 어떤 면에서 치팅으로 볼 수 있다. 그러나 이 실험을 통해 우리는 기존 방법들이 달성할 수 있는 성능의 상한을 엿볼 수 있다.

그림 B는 FIVR-5K에서의 ISVR 성능을 나타낸다. temporal annotation을 통한 적절한 distractor frame의 억제가 전체적으로 1.24배에서 1.58배에 달하는 성능 향상을 이뤄낸 것을 볼 수 있다. 특히, video-level 기반 방법들의 약점으로 여겨진 정확도가 지금까지 가장 뛰어난 성능을 낸 frame-level 방법론인 ViSiL에 근접하게 향상된 것을 볼 수 있다.
Examples within Easy Distractor Set
DDM 학습에 사용된 Easy Distractor Set은 VCDB 데이터셋의 metadata-free video들로부터 추출되었다. (metadata-free video란, annotation이 없는 background video들을 의미함) 모든 영상들로부터 frame-level feature인 $\text{L}_N\text{-iMAC}$을 추출하였는데, 백본 신경망의 어떤 계층이 low-level characteristics를 생성하는지 알아보기 위해 PCA는 수행하지 않았다. 추출된 feature들의 magnitude가 임계값 $\lambda_{mag}$보다 낮다면 easy distractor set에 추가하였다. 이런 방법으로 easy distractor를 선별하는 것은 적은 low-level characteristics를 생성하고 적은 pixel variation을 갖는 것이 결국은 더 작은 스케일의, 더 적은 설명력을 갖는 frame-level feature를 생성하기 때문이다. 그러나, 이 과정이 너무 낮은 임계값으로 수행되면 easy distractor의 다양성(variance)가 감소하여 특정 패턴의 distractor에만 반응하게 과적합이 일어난다. 한편, 너무 높은 임계값을 적용하면 실제로는 유의미한 정보를 가진 많은 프레임들이 distractor로 여겨져 DDM에 의해 제거될 것이다. 적절한 임계값을 설정하기 위해 모든 frame-level feature들의 magnitude들을 표 A와 같이 분류하였다.
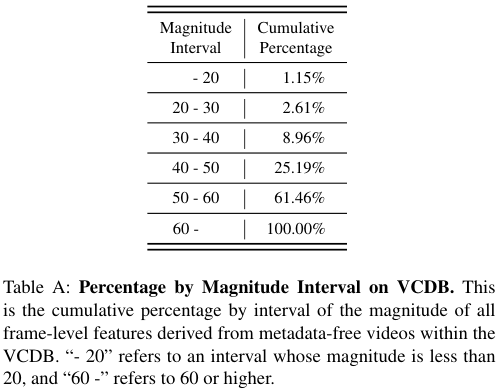
이를 참고하여 임계값을 40으로 적용하여 대략 10% 정도의 데이터가 distractor에 포함되도록 하였다. 그림 C를 보면 이렇게 선택된 easy distractor들이 있다. 정성적인 결과를 볼 때, 40의 임계값이 꽤나 적절함을 알 수 있다.
Advantages of Tempered Sigmoid
TGM에서, 시그모이드 함수 대신에 Tempered Sigmoid를 사용하였다. Tempered Sigmoid는 그래디언트의 노름(norm)을 조절하여 학습 단계에서 노이즈에 대한 강건함을 얻고자 제안되었다.
$$ \omega(h) = \frac{\sigma}{1+e^{-h/\tau}} - o $$
$\omega$로 표현된 tempered sigmoid 함수에서, $\sigma$는 활성화 값의 규모(scale)을 조절하는 값이고, $\tau$는 그래디언트 노름을 감소시켜 모델이 신중하게(carefully) 조정되도록 하는 temperature이다. $o$는 오프셋 값이다.
TGM은 DDM의 출력을 입력 받는데, 이때 영상의 주제와 관련된 easy distractor와 관련되지 않은 easy distractor 모두를 입력받게 된다. TGM은 전역 연산인 ST-GAP을 입력받아 거친 패턴들을 생성하게 되는데, 이는 다른 모듈에 비해 노이즈에 더 취약하게 된다. 이때 tempered sigmoid를 적용하면 TGM이 더 안정적으로 학습되도록 할 수 있다. 저자들은 $\sigma=1, o=0$으로 설정하여 TGM의 출력이 0~1이 되록 하였고 $\tau$는 512로 설정하였다.

표 B의 실험 결과를 통해, TGM에만 tempered sigmoid를 적용하는 것이 가장 적절했음을 알 수 있다. 다만 ISVR task에서는 tempered sigmoid를 적용하지 않는 것이 좋았다. TGM을 제외한 모델들에서는 noise가 영향을 적게 미치는 탓에, 오히려 tempered sigmoid가 불충분한 최적화를 유발하는 것을 확인헀다.
Effect of Saliency Signal on Representation
TSM에서 모델은 frame-level 유사도 맵의 saliency signal에 의해 생성된 pseudo-label로 학습된다. 이 부분에서는 salinency signal이 실제로 video-level feature의 표현력에 기여하는 부분을 해석해본다. saliency signal의 영향을 평가하기 위해, frame-level 유사도 맵에서 얻어진 가중치를 곧바로 추론 단계에서 사용하였다. 이 실험은 본문에서 $\text{VVS}_{3840}$의 ablation study에 사용한 베이스라인을 토대로, 모든 frame-level feature들이 다른 모듈들의 가중치 없이 그대로 사용되도록 하여 진행되었다.
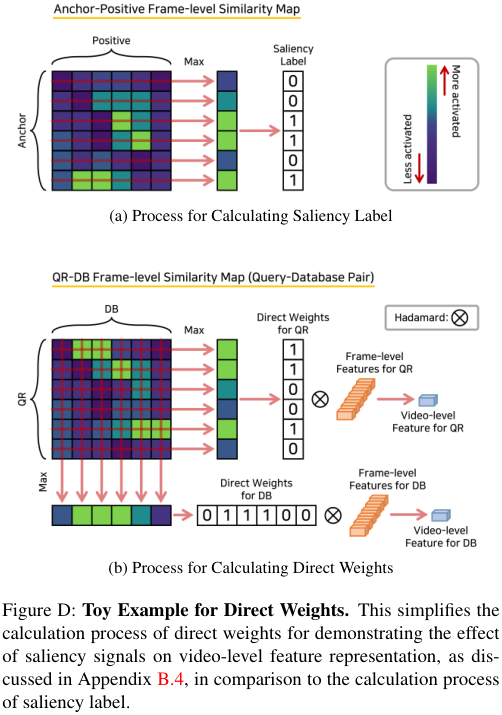
video-level feature를 생성하기 앞서, 그림 D의 (b)에 나타난 것처럼, 쿼리 영상과 DB 속 각 영상들에 대한 frame-level 유사도 맵이 계산되었다. 이 유사도 맵에 maximum operation을 적용하고, 값을 1 또는 0으로 변환하였다. (그림 D의 (a)에 묘사된 saliency label 취득 과정과 같다.) 이 과정을 각 축에 대하여 수행하여, 쿼리 영상과 DB 영상에 대한 direct weights를 생성한다. 이 weights들은 frame-level feature에서 유도되었기 때문에, video-level 방법이라고는 할 수 없지만, frame-level feature들을 누적하여 video-level feature를 생성하는데 직접적으로 관여한다.

표 C에 나타난 것처럼, direct weights가 적용되었을때 성능이 베이스라인 대비 확실한 폭으로 증가한다. 이는 saliency signal이 video-level feature의 표현력을 증가시키는데 큰 영향을 미침을 시사한다. 또한 이 결과는 TSM의 saliency label이 모델이 시각적 연관성을 탐색하도록 하여 특히 DSVR task에서 성능을 향상시킴을 알 수 있다.
결론
약 2개월의 노력 끝에 마침내 연구실 기초 교육 과정의 마지막 논문인 VVS를 완독했다.
이 논문은 연구실 선배들이 작성한 논문이라, 읽기 앞서 많은 기대와 걱정이 있었는데 정말 같은 연구실, 선배들이라 하는 얘기가 아니라 객관적으로 잘 잃히고, 내용이 정말 많은 논문이었다.
이렇게 알찬 논문을 쓰기 위해 얼마나 많은 시간이 들었을까. 동기부여가 많이 되는 논문이었다.
'Deep Learning > 논문 리뷰' 카테고리의 다른 글
| ImageBind: One Embedding Space To Bind Them All 리뷰 (0) | 2023.05.16 |
|---|---|
| VVS: Video-to-Video Retrieval with Irrelevant Frame Suppression 요약 (0) | 2023.05.12 |
| ViSiL: Fine-grained Spatio-Temporal Video Similarity Learning 리뷰 (0) | 2023.04.04 |
| Near-Duplicate Video Retrieval with Deep Metric Learning 리뷰 (0) | 2023.03.30 |
| Near-Duplicate Video Retrieval by Aggregating Intermediate CNN Layers 리뷰 (0) | 2023.03.29 |