Near-Duplicate Video Retrieval with Deep Metric Learning 리뷰
이 논문은 Deep Metric Learning(DML)을 활용한 효과적인 유사-중복 영상 검색(Near-Duplicate Video Retrieval, NDVR) 방법을 제안한다.

개발과 평가 과정 모두에서 같은 데이터셋으로부터 추출된 정보를 사용하는 2017년 당시 기존 SOTA 모델들과 달리, 이 논문에서는 별도의 데이터셋에서 triplet으로 학습된 모델에, 흔히 사용되는 CC_WEB_VIDEO 데이터셋을 이용하여 평가를 진행한다.
저자들은 AlexNet과 GoogleNet 구조를 활용하여 실험을 진행하였고, 평가 데이터셋을 학습에 사용하지 않고도 SOTA를 달성하였다.
저자들은 기존의 NDVR 연구들이 특정 데이터셋에서 학습과 평가가 동시에 이루어져, 다른 데이터셋에서의 평가 성능이 좋지 않음을 지적하였다. 저작권 보호, 불법 복제 탐지 등에 사용되어야 할 NDVR 기술에 있어 이렇게 dataset-specific 한 성능은 바람직하지 않다.
저자들은 기존에 흔히 사용되던, 데이터셋의 영향을 많이 받는 Bag of Word 방식이 아닌 딥러닝 기반의 Video-level NDVR을 제안한다.
저자들은 CNN의 중간 계층에서 최근 흔히 사용되는 MAC(Maximum Activation of Convolution) 기법으로 representation을 추출하며, triplet 기반 방법을 사용한 Deep Metric Learning을 적용한다.
이 연구는 NDVR 연구에 Deep Metric Learning을 적용한 첫 연구로, NDV 영상들이 다른 영상들에 비해 가까운 거리를 갖도록 하는 Mapping 함수를 학습한다.
뿐만 아니라, 논문은 영상 representation을 생성하는 두 가지의 방법을 제안한다. 이렇게 생성된 영상 representation은 scalable한 NDVR 시스템을 위해 compact 한 크기를 갖는다.
저자들은 triplet generation 방법을 통해 DML모델을 학습시키며, 이때 VCDB 데이터셋을 사용한다.
그 다음, CC_WEB_VIDEO 데이터셋을 통해 평가를 진행하는데, 일부 실험해서는 다른 연구들과의 비교를 위해 학습과 평가를 같은 데이터로 진행하기도 하였다.
Approach
Feature Extraction
먼저, $L$개의 합성곱 계층$\mathcal{L}_{i}$을 가진 사전학습된 CNN 신경망에서 MAC을 추출한다. 각 계층의 출력 $\mathcal{M}^l \in \mathbb{R}^{n_d^l \times n_d^l \times c^l}(l=1, \cdots, L)$에서 하나의 descriptor만을 추출하기 위해, 각 채널 $M^l$에 대하여 global max pooling을 수행한다.
$$ v^l(i) = \max \mathcal{M}^l (\cdot, \cdot, i), i=(1, 2, \cdots, c^l)$$
추출을 통해 각 계층별로 $c^l$ 크기의 벡터 $v^l$를 얻고, zero-mean과 l2 normalization을 적용한다.
저자들은 AlexNet에서는 전체 합성곱 계층에 대하여 특성 추출을 수행했고, GoogleNet에서는 Inception 계층에서만 특성을 추출했다. 각 모델은 각각 1376개와 5488개 차원의 벡터를 생성했다. 두 모델은 모두 $224\times 224$크기 입력을 받았다.
Global video descriptor를 생성하기 위해 저자들은 각 영상에서 초당 $n$개(연구에서는 $n=1$)의 프레임을 추출하여 frame descriptor를 생성하고, 이들의 평균에 zero-mean과 l2 normalization을 적용하여 global video descriptor를 구했다.
Feature 추출 과정은 사전학습 모델로 진행되고 별도의 학습을 진행하지는 않았다. 즉, 이 논문의 모델은 end-to-end 학습이 아니다.
Metric Learning
저자들은 두 영상 $q, p$의 영상 임베딩 공간(video embedding space) 상에서의 squared Euclidean 거리를 다음과 같이 정의한다. ($\theta$는 시스템 파라미터, $f$는 임베딩 함수를 의미한다.)
$$D(f_\theta(q), f_\theta(p)) = ||f_\theta(q) - f_\theta(p)||_2^2$$
우리의 목표는 임베딩 함수 $f_\theta$가 NDV들 사이에는 가까운 거리를 주고, NDV가 아닌 영상들 사이에는 먼 거리를 주도록 학습시키는 것이다. 비디오의 feature vector $v$와, 해당 비디오의 NDV feature vector에 해당하는 $v^+$, NDV가 아닌 비디오의 feature vector $v^-$에 대하여, $f_\theta(\cdot)$는 이들을 하나의 공간 $\mathbb{R}^d$에 잘 매핑해야 한다.
$$ D(f_\theta(v), f_\theta(v^+)) < D(f_\theta(v), f_\theta(v^-)), \\
\forall v, v^+, v^- \text{ such that } I(v, v^+) = 1, I(v, v^-)=0$$
$I(\cdot, \cdot)$는 두 영상이 NDV인지 여부를 판별하는 함수이다.
Triplet Loss
Triplet Loss를 이용한 학습을 위해, 데이터를 $N$개의 Triplet $\mathcal{T} = [(v_i, v_i^+, v_i^-), i=1, \cdots, N]$로 나눈다.
이때 $(v, v^+, v^-)$는 각각 쿼리, positive(NDV), negative이다. $v$와 $v^+$는 가까운 거리를 갖고, $v$와 $v^-$는 먼 거리를 가질 수 있도록 모델은 다음 triplet loss로 학습된다.
$$L_\theta(v_i, v_i^+, v_i^-) = \max(0, D(f_\theta(v_i), f_\theta(v_i^+)) - D(f_\theta(v_i), f_\theta(v_i^-))+\gamma)$$
$\gamma$는 margin parameter로, positive와 쿼리의 거리보다 negative와 쿼리의 거리가 충분히 멀어지도록 한다.
만약 positive sample간의 거리가 $\gamma$ 이하로 잘 임베딩되면, 모델은 loss함수의 페널티를 받지 않는다.
그러나 positive sample간의 거리가 $\gamma$보다 크다면, negative sample 간의 거리보다 (positive sample + $\gamma$)의 거리가 큰 만큼 페널티를 받는다.
최종적으로, 모델은 아래 전체 손실함수에 의해 경사하강법으로 학습된다.
$$ \min_\theta\sum^m_{i=1}L_\theta(v_i, v_i^+, v_i^-) + \lambda||\theta||^2_2$$
위 식에서 $\lambda$는 L2 Regularization을 조절하는 파라미터이다. $m$은 미니 배치들의 전체 사이즈를 의미한다.
Model Architecture
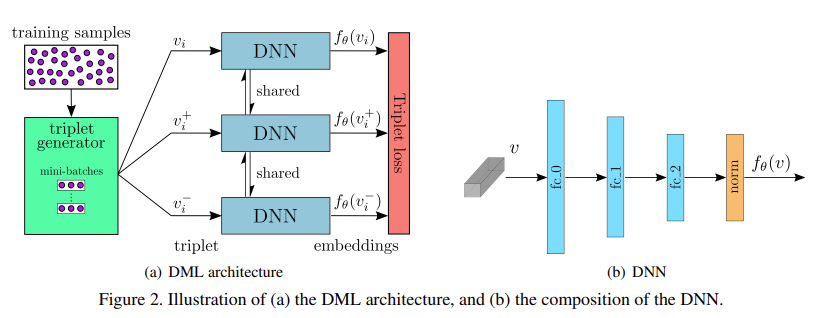
모델은 위 그림의 (a)와 같이 구성된다.
먼저 학습 비디오들은 사전학습된 CNN을 이용하여 feature vector $v$ 형태로 변환된다. 아래에서 설명할 triplet generator는 triplet $\mathcal{T}$를 생성하여, 같은 파라미터를 공유하는 3개의 DNN에 각각 입력된다. 이 DNN들은 $f_\theta(v)$를 생성하여 Triplet Loss로 들어가게 된다.
각 DNN은 3개의 완전연결 계층과 normliazation 계층으로 구성되어, 결과적으로 $d$ 차원의 유닛 벡터를 생성한다. 은닉층의 크기와 $d$는 입력 사이즈에 따라 결정된다.
Video-level similarity computation

학습되어진 $f_\theta(\cdot)$을 사용하여 비디오 간의 유사도를 구하는 두 가지 방법이 있다.
얼리 퓨전(Early Fusion)은 Frame Descriptor들이 모델에 순전파되기 전에, 평균을 구하고, normalization을 수행하여 global video descriptor로 만든다.
레이트 퓨전(Late Fusion)은 모든 Frame Descriptor들을 신경망에 순전파시킨다. 그다음 신경망을 통과한 frame descriptor들의 평균을 구하고 normalization을 수행한다.
두 방법에는 각각의 장단점이 있는데, 얼리 퓨전은 연산량이 더 적고 직관적인 구조를 가지고 있지만, 비교적 덜 효과적이다. 한편, 레이트 퓨전의 경우, 더 좋은 성능을 내고, frame-level approach를 적용할 수도 있다는 장점이 있지만, 연산량이 더 많은 단점이 있다.
Simlilarity Calculation
$$ S(q, p)=1-\frac{D(f_\theta(q), f_\theta(p)}{\max_{p_i\in P}(D(f_\theta(q), f_\theta(p_i)))}$$
두 영상 $p, q$의 유사도 $S(p, q)$는 위와 같이 계산된다. $p, q$의 거리를 전체 DB의 영상 중 쿼리 영상과 가장 먼 거리를 가진 샘플의 거리로 나눈 후, 이를 1에서 빼어 전체 영상에 대한 상대적인 유사도를 구하는 것이다.
Triplet Generation
적절한 양의 Triplet 쌍 $(v, v^+, v^-)$을 잘 만들어 제공하는 것 역시 중요하다. 그러나, $N$개의 영상이 있는 코퍼스를 통해 만들 수 있는 조합의 수는 $\frac{N(N-1)(N-2)}{6}$으로 한계가 있다. 뿐만 아니라, 비디오 코퍼스에 있는 일부 영상 쌍만이 유사-중복(positive)으로 구분될 수 있기 때문에, 충분한 수의 triplet을 만드는 것은 어려운 일이다. 그렇기에, 저자들은 triplet 생성을 단순 조합이 아닌, 학습에 도움이 되는 어려운 조합들 위주로 적절히 샘플링하는 것에 집중하였다.
데이터셋은 유사 중복(positive) 비디오 쌍들을 포함한 집합 $\mathcal{P}$와, 그렇지 않은 영상들(negative)의 집합 $\mathcal{N}$으로 나누어진다. 우리는 음성 쌍들의 거리가 양성 쌍들의 거리보다 가까운 어려운 triplet들을 고르는 것을 목표로 한다. 이 조건은 다음과 같은 수식으로 표현된다.
$$ \mathcal{T} = [(q, p, n)|(q, p)\in \mathcal{P}, n \in {N}, D(q,p) > D(q, n)]$$
먼저, $\mathcal{P}$안의 모든 쿼리에 대한 집합 $\mathcal{N}$ 속의 영상들과의 거리가 구해진다. 그다음, query-positive의 거리보다 작은 거리를 갖는 negative 샘플들을 골라내어 triplet들을 생성하는 것이다.
Evaluation
저자들은 VCDB 데이터셋을 이용하여 triplet들을 구성하고, 학습을 진행했다. 이때, 기존에는 데이터셋에서 유사 중복 영상으로 분류된 데이터쌍들을 점검하여, 영상 간에 중복된 길이가 임의의 값 $t$ 미만일 경우, 유사 중복이 아닌 것으로 보았다. 이때, $t$의 값을 적절히 설정하는 것이 성능에 영향을 주었다고 한다.
저자들은 AlexNet과 GoogleNet 구조를 사용해 여러 실험을 진행하였는데, frame-level feature fusion시에 ealry fusion과 late fusion의 차이는 근소하게 late fusion이 더 좋은 성능(mAP)을 보였다.
feature를 논문에서 제안한 것처럼 전체 합성곱 계층에서 뽑는것과 마지막 합성곱 계층에서 뽑는 것, 첫 완전 연결 계층에서 뽑는 것을 비교한 실험도 진행하였는데, 제안된 방법이 가장 좋은 성능을 보였다.
저자들은 기존 SOTA 모델과의 비교에서 CNN-L모델과의 비교를 진행하였는데, 학습과 테스트를 같은 데이터셋에서 진행할 때에 비해 학습과 테스트를 다른 데이터에서 진행할 때, DML모델이 더욱 적은 정확도 감소를 보이는 것을 확인했다.
결론
논문에서, 학습과 테스트를 같은 데이터셋에서 진행하여 일반화 성능이 떨어짐을 지적한 것이 흥미로웠다.
더불어 첫 Metric Learning 논문이었는데, 설명이 정말 깔끔하고 친절하게 되어있어 쉽고 재미있게 읽을 수 있었던 것 같다.
논문에 구현 디테일도 상세하게 적어놓아서 정말 공들인 논문이라는 것이 느껴졌다.
References
- 원본 논문
- [DeepLearning]Triplet Network - 다꾸니스님