Distilling Vision-Language Pre-training to Collaborate with Weakly-Supervised Temporal Action Localization 리뷰 [CVPR 2023]
기존의 Weakly-Supervised Temporal Action Localization (W-TAL) 방법론들은 대부분 classification-based pre-training (CBP) 방법을 사용하였습니다. (BaS-Net 리뷰) 그러나 classification과 localization은 근본적으로 목표가 다르기 때문에, CBP 방법은 temporal localizationd의 결과가 좋지 않은 단점이 있었습니다.
본 논문에서는 이를 해결하기 위해 CLIP과 같은 Vision-Language Pre-training (VLP) 모델이 가지고 있는 action knowledge를 distillation 하는 방법을 제안합니다.
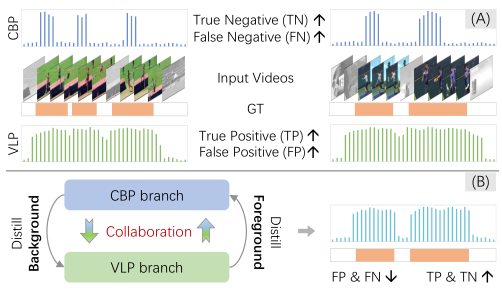
기존 CBP 방법들은 classification의 정확도를 높이기 위해, 영상 속 애매한 프레임(도움닫기 등)보다는 구별력이 강한 프레임들에 집중하는 경향이 있었는데, 이로 인하여 temporal localization이 실제 액션에 비하여 지나치게 작아지는 incomplete 문제가 있었습니다. (Background를 잘 잡아내는 CBP 방법)
한편, VLP의 경우 이미지와 어떤 자연어 개념과의 유사도를 이용하기 때문에, 맥락적인 정보를 잘 잡으나 오히려 실제 액션보다 큰 범위를 localization proposal로 생성하는 over-complete 문제가 있었는데요. (Foreground를 잘 잡아내는 VLP 방법)
저자들은 이렇게 상호보완적인 두 방법을 각각의 브랜치로 구성하고 서로 distillation-collaboration 하도록 학습하게 하여, temporal locatlization을 잘 수행할 수 있는 모델을 만들고자 하였습니다.
두 브랜치는 번갈아가며 학습을 진행하는데요. (Alternate Learning) 먼저 B step에서는 CBP 브랜치가 생성한 confident background pseudo-label을 VLP 브랜치에 distillation 하여 VLP가 background에 대하여 배우게 하고, F step에서는 VLP 브랜치가 생성한 confident foreground pseudo-label을 CBP 브랜치에 distillation하여 CBP가 foreground에 대하여 배우게 합니다. 이를 번갈아가며 반복하여 두 브랜치가 점차 incomplete, overcomplete 없이 좋은 localization을 수행할 수 있도록 학습됩니다.
이러한 방식을 통해 저자들은 ActivityNet1.2와 THUMOS14에서 SOTA를 달성할 수 있었다고 합니다.
논문의 contribution은 아래와 같습니다.
- VLP로부터 free action knowledge를 distill 하는 첫 시도
- 새로운 distillation-collaboration 프레임워크를 통해 CBP, VLP가 상호 보완적으로 최적화됨
- THUMOS14와 ActivityNet1.2에서 SOTA를 달성함
Method
$N$개의 untrimmed video $\{ v_i \}^N_{i=1}$과 video-level category label $\{ y_i \in \mathbb R^C \}^N_{i=1}$가 주어질 때, WTAL 모델은 주어진 영상 속의 액션 인스턴스들을 $\{(s, e, c, p)\}$ 형태로 예측합니다. 이때, $s,e,c,p$는 각각 액션의 시작과 끝 시간, 액션 종류, confidence score입니다.
Distillation of Foreground and Background
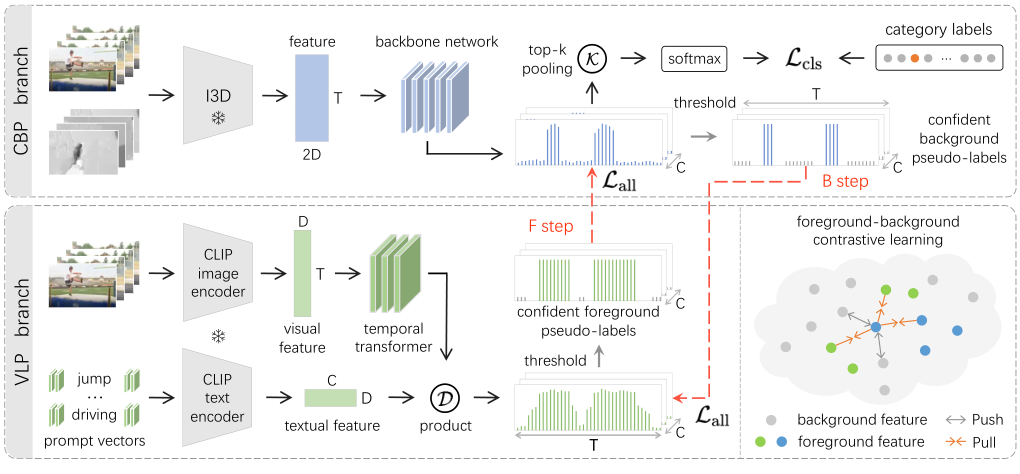
CBP 브랜치는 Classification-Based Pre-training을 통해 대량의 background 프레임들과 일부 discriminative action 프레임들을 분류합니다.
먼저, kinetics에서 사전학습 된 I3D 네트워크를 통해 RGB와 Flow feature 각각에서 특성을 추출하여 $F_{i3d} \in \mathbb R^{T\times 2D}$를 생성합니다. 이때, $T$는 프레임의 수, $D$는 feature dim.입니다. feature 추출에 사용되는 I3D는 freeze 상태로 두고, 추출된 feature를 이용해 CBP 브랜치의 백본 신경망을 파인튜닝합니다. 백본 신경망은 frame-level action probabilities $P^{cb} \in \mathbb R^{T\times C}$를 생성합니다.
얻어진 $P^{cb}$로부터 top-k 프레임의 score를 풀링하여 video-level category scores $\hat y \in \mathbb R^C$를 만들고 BCE로 warmup 학습을 수행하여 브랜치가 background 프레임들을 잘 구분하도록 합니다.
$$\mathcal L_{cls} = \sum^C_{c=1} -y_c \log \hat{y_c}, \hat{y_c} = \sigma(\frac{1}{k}\sum \mathcal K(P^{cb}))$$
이때, $\mathcal K$는 top-k score set in the temporal domain이고 $\sigma$는 소프트맥스 함수입니다.
VLP 브랜치는 CLIP과 같은 VLP 모델에서 free action knowledge를 추출하고자 합니다. VLP 모델은 action의 classification이 아닌 임베딩을 위해 학습되었기 때문에 CBP에 비하여 액션과 잠재적으로 유사한 프레임들까지 잘 잡아내는 경향이 있지만, 영상이 아닌 이미지에서 학습되었기 때문에 temporal information이 상대적으로 부족하여 너무 많은 영역을 액션으로 분류하는 over-complete 문제도 가지고 있습니다.
정리해보면, Warmup 학습을 마친 CBP는 background frame을 잘 잡아내지만(true negative), 뚜렷하게 액션으로 보이지는 않지만 연관이 있는 프레임(도움닫기 등)들까지 background로 치부하는 문제(false negative)가 있습니다.
VLP는 액션과 의미론적으로 유관한 (semantically related) 프레임들을 잘 잡아내지만 (true positive), 액션과 무관한 장면들까지 액션으로 분류하는 문제 (false positive)가 있습니다.
VLP의 구조를 살펴본 후, 이 두 모델을 서로 보완적이게 학습시키는 방법을 살펴보겠습니다.
먼저 freeze된 CLIP image encoder에 영상을 클립 단위로 쪼개어 입력하여 frame-level feature $F_{vis} \in \mathbb R^{T\times D}$를 얻습니다. 이때, CLIP은 이미지만을 학습하여 temporal 한 정보를 다룰 수 없기 때문에 temporal modeling을 수행할 transformer layer $\Phi_{temp}$를 통해 $F_{vis}$를 $F_{vid} \in \mathbb R^{T\times D}$로 변환합니다.
한편, 각 액션의 라벨들을 freeze된 CLIP text encoder에 입력하여 각 클래스에 맞는 textual feature를 만들고, 이 feature와 앞서 얻은 clip들의 feature 간의 유사도를 계산하여 액션 localization을 수행할 것인데요. 이때, 입력할 액션 라벨의 전후로 학습 가능한 프롬프트 벡터 $\Phi_{prmp}$들을 추가하여 prompt learning을 수행합니다. 이렇게 textual feature $F_{txt} \in \mathbb R^{C\times D}$를 얻게 됩니다.
$$ F_{vid} = \Phi_{temp} (F_{vis}), F_{txt} = \Phi_{txt}(\Phi_{prmp}(C_{name}))$$
$C_{name}$은 클래스 이름, $\Phi_{txt}$는 CLIP 텍스트 인코더를 의미합니다. 이제 frame-level localization result $P^{vl}$은 다음과 같이 계산할 수 있습니다.
$$ P^{vl} = \sigma(F_{vid} \cdot F_{txt}^\top) \in \mathbb R^{T\times C}$$
VLP 브랜치는 CLIP의 인코더들을 freeze하고 학습하기 때문에, temporal transformer와 learnable prompt 만을 학습하게 되는데요. 이를 통해 CLIP 백본이 가지고 있는 action prior knowledge를 보존하여, true-positive result를 보존할 수 있고 weakly supervised 설정에 적절하며, 메모리 사용량이 줄어드는 효과가 있습니다.
이렇게 CBP는 background pseudo-label $P_{cb}$, VLP는 foreground pseudo-label $P_{vl}$을 생성하게 되는데요. 이때 두 라벨 모두 각각에 해당하는 noise를 갖고 있기 때문에, confident 한 영역들만 distillation 하여 VLP는 확실히 background인 영역들을 학습하여 false positive를 줄이고, CBP는 확실히 foreground인 영역들을 학습하여 false negative를 줄여야 합니다. 이를 위해 임계값 $\delta_h, \delta_l (\delta_h > \delta_l)$들을 이용하여 $P$를 confident한 pseudo-label $H\in \mathbb R^{T\times C}$로 변환해 줍니다.
$$ h_{t, c} = \begin{cases} 1 & \mbox{if} & p_t > \delta_h & \mbox{and} & p_c = y_c \\
0 & \mbox{if} & p_t < \delta_l & \mbox{or} & p_c \neq y_c \\
-1 & & & \mbox{otherwise}
\end{cases} $$
Collaboration of Dual-Branch Optimization
앞서 정의한 두 브랜치에서 얻어지는 pseudo-label들을 이용하여 두 브랜치를 번갈아가며 학습을 진행합니다.
먼저, B step에서는 잘 warmup 된 CBP 브랜치를 freeze 하고, confident background pseudo-label $H^{cb}$를 만들어 VLP 브랜치를 학습하여 CLIP이 기존에 생성하던 대량의 false-positive를 줄여줍니다.
이어서 F step에서는 high-quality foreground pseudo-label $H^{vl}$을 frozen VLP 브랜치에서 생성하여 CBP의 false-negative를 줄이기 위해 학습시킵니다.
각 step에는 knowledge distillation loss $\mathcal L_{kd}$와 foreground-background contrastive loss $\mathcal L_{fb}$가 사용됩니다. 두 손실함수는 하이퍼 파라미터 $\lambda$로 비율을 맞추어 합쳐지게 됩니다.
$$\mathcal L_{all} = \mathcal L_{kd}(H', P) + \lambda \mathcal L_{fb}(\Psi^+ \Psi^-)$$
이때, $\mathcal L_{kd}$는 다른 브랜치의 pseudo-label과 현재 브랜치가 각각 수행한 confidence한 예측이 비슷한 분포를 갖도록하여 pseudo label의 노이즈의 영향을 줄이는 역할을 합니다. pseudo-label의 노이즈에 해당하는 uncertatin frame들을 제외한, confidence frame들 간의 유사도를 높여 확실히 background/foreground 인 영역들의 정보를 distill 하는 것이죠.
$$\mathcal L_{kd}(H', P) = \frac{1}{O}\sum^C_{c=1} \sum^O_{t-1} D_{KL}(h'_{t,c} || p_{t,c})$$
$D_{KL}(p(x)||q(x))$는 쿨백 라이블러 발산이며, $O$는 confident frame의 수이고 $H'$는 다른 브랜치에서의 pseudo-label을 의미합니다. 이때, pseudo label은 foreground와 background 두 가지 종류의 confidence frame을 가집니다.
contrastive loss $\mathcal L_{fb}$는 긴 untrimmed video에서 foreground 프레임과 시각적으로 유사한 일부 background 프레임들을 다루기 위해 도입됩니다. 같은 액션에 속하는 confident foreground frame들을 $\Psi^+$, 모든 background frame들을 $\Psi^-$라 할 때, loss는 아래와 같습니다.
$$ \mathcal L_{fb}(\Psi^+_i, \Psi^-_i) = \sum_i -\log \frac{\sum_{m\in\Psi_i^+} \exp(f_i\cdot f_m/\tau)}{\sum_{j\in*} \exp(f_i \cdot f_j / \tau)}$$
$f\in \mathbb R^D$는 frame feature, $\tau$는 temperature 하이퍼 파라미터, $*$은 $\Psi^+_i, \Psi^-_i$의 합집합입니다.
Inference
VLP가 flow를 다룰 수 없기 때문에, 추론은 더 다양한 데이터를 사용할 수 있는 CBP 브랜치의 결과를 후처리 해서 사용합니다. localization 임계값보다 confidence가 큰 frame들을 이용해 proposal을 만들고, classification 임계값보다 큰 proposal들만 남긴 다음 최종적으로 soft NMS를 수행하여 중복 예측을 지워 추론을 수행합니다.
Experiments
THUMOS14는 20개의 클래스에 대한 413개의 untrimmed video를 가지고 있으며 각 영상은 평균 15개의 액션을 갖고 있습니다. 저자들은 이 중 200개를 학습 영상, 213개를 테스트 영상으로 사용하였습니다. 이 데이터셋은 영상의 길이가 다양하고 액션이 자주 일어나 어려운 편에 속한다고 합니다. ActivityNet1.2는 100개의 클래스에 대한 9682개의 영상을 갖고 있습니다. 대부분의 영상이 하나의 클래스에 속하며, 액션이 영상의 반 이상을 차지한다고 합니다. 4619개의 학습 영상과 2383개의 테스트 영상으로 나누어 사용하였다고 합니다.
평가는 각 IoU 임계값 설정에 따른 mAP를 사용하였고 이때, 예측 클래스와 IoU 모두가 양성이어야만 양성으로 분류되기 때문에, pseudo-label의 성능을 잘 측정하기 위해 별도로 foreground class와 background class에 대한 mIoU를 보고하였습니다.
다양한 길이의 영상을 다루기 위해 $T$개의 연이은 스니펫들을 랜덤 하게 추출하였는데, $T$는 THUMOS14에서 1000, ActivityNet1.2에서 400을 사용했고, TV-L1 알고리즘으로 optical flow를 얻었다고 합니다. CBP 브랜치에서 transformer 구조(멀티 헤드 셀프 어텐션, layer norm, MLP)를 백본으로 사용하였고 VLP 브랜치에서는 2-layer temporal transformer를 사용하고 textual input에 16개의 prompt vector를 prepend, append 하였습니다. (초기화는 $\mathcal N(0, .01)$) CLIP 이미지 인코더와 text 인코더는 모두 ViT-B/16 버전에서 가져왔고 Adam optimizer에 le $10^{-4}$로 학습했습니다. 하이퍼 파라미터는 grid search 하였으며 다음과 같다고 합니다. pseudo-label thres $\delta_h=0.3 \delta_l=0.1$ inference thres $\theta_{cls}=0.85, \theta_{loc}=0.45$ balancing ratio $\lambda=0.05$, temperature $\tau=0.07$
Comparison with SOTAs
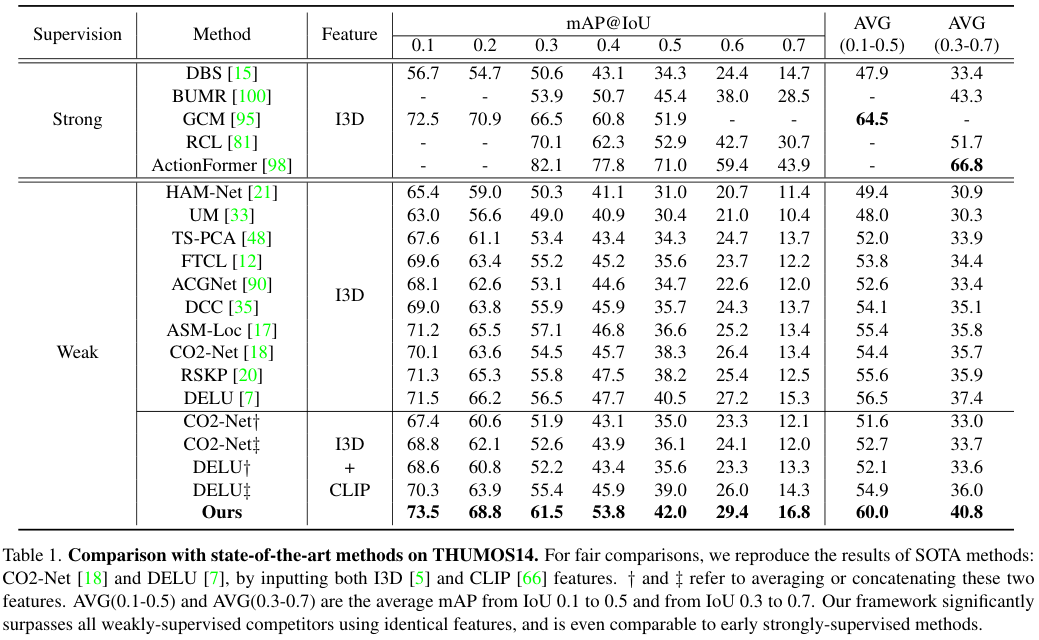
먼저 THUMOS14 데이터셋에서의 비교입니다. 본 논문에서 제안하는 방법이 weakly supervised 방법 중 SOTA를 달성한 것을 볼 수 있습니다. 특히, 저자들이 방법이 일부 strong supervised 초기 모델을 앞서는 성능을 보여주고 있습니다.
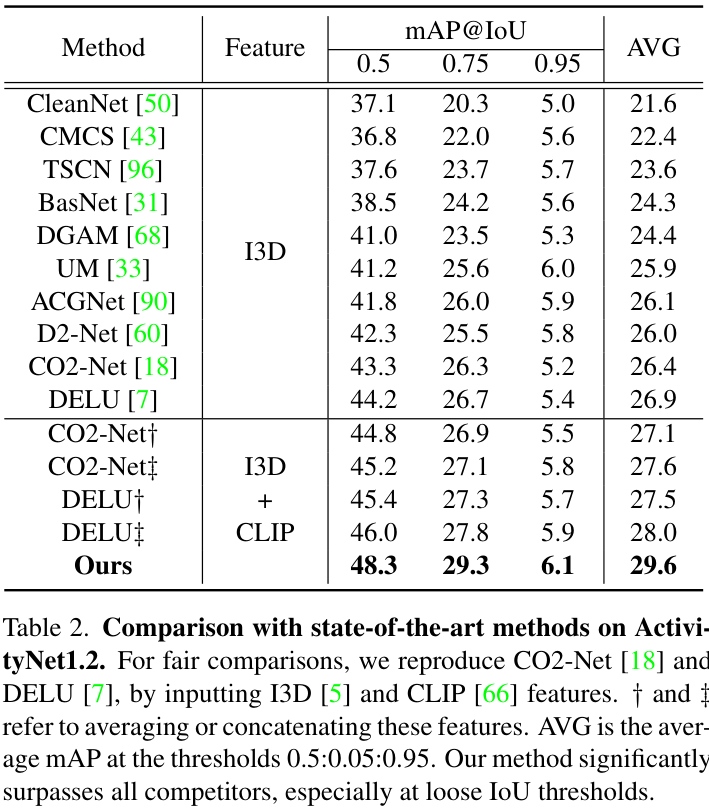
다음은 ActivityNet1.2에서의 비교 결과입니다. 역시 저자들이 제안한 방법이 기존 방법들을 크게 앞선 SOTA를 달성하고 있습니다.
이러한 성능 향상의 비결은 Vision-Language Pre-training 모델의 free knowledge라고 합니다. 저자들은 이를 검증하기 위하여 I3D 만을 사용한 기존 방법들에 CLIP을 더하고 성능을 확인하였는데요. 이때, 단순히 CLIP feature를 추가하기만 해서는 over-complete 문제로 인해 성능이 미미하게 향상되거나 오히려 하락하였다고 합니다. 특히 액션이 여러 차례 복잡하게 등장하는 THUMOS14에서는 성능이 오히려 감소하였으며, 액션이 대부분 한번 정도, 장시간 등장하는 ActivityNet에서는 약간의 성능 향상이 있었다고 합니다. 한편 제안한 모델은 성능이 크게 올라 제안한 방법의 유효성을 볼 수 있었다고 하네요.
Ablation Study and Comparison
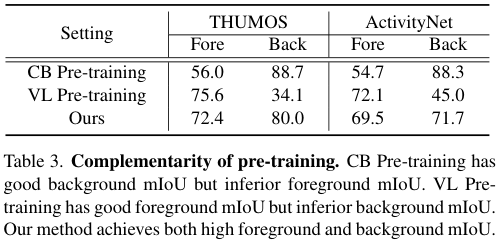
본 모델의 성능이 학습에 사용되는 pseudo-label과 큰 연관이 있기 때문에, 저자들은 각 pseudo-label의 정확도를 보고하였습니다. CBP의 경우 incomplete 문제로 인해 foreground에 대한 예측이 좋지 않고, VLP의 경우 반대로 background에 대한 성능이 좋지 않은 것을 볼 수 있습니다.
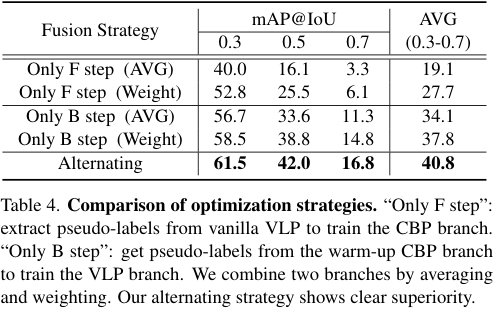
다음은 학습 방식에 따른 성능 비교입니다. Only F step은 vanilla VLP에서 foreground pseudo-label을 추출하여 CBP 브랜치를 학습하는 F step만 진행한 결과이고, Only B step은 반대로 CBP에서 얻은 background pseudo-label로 VLP 브랜치만을 학습한 결과입니다. 각 방법에 대하여, 두 브랜치의 결과를 평균하거나 가중합하여 결과를 얻었다고 합니다.
Only F step이 가장 안 좋은 결과를 보였는데, VLP가 만든 foreground pseudo-label에 noise가 너무 많아 성능이 좋지 않았다고 합니다. 한편, Only B step의 경우 VLP를 background pseudo-label로 학습시켜 꽤나 성능이 좋은 모습을 볼 수 있었는데요. 그럼에도 역시 두 방법을 모두 사용해 상호보완적으로 학습을 수행하는 것이 가장 좋은 결과를 보였다고 합니다.
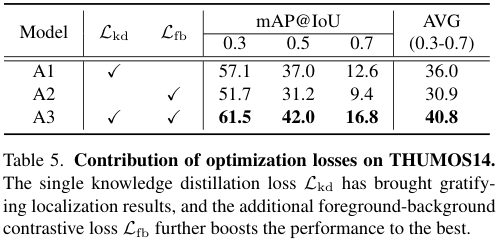
저자들은 학습을 위해 다양한 손실 함수를 사용하였는데, 이러한 손실 함수들의 기여를 확인하기 위한 실험을 진행하였습니다. 각 손실함수를 제거함에 따라 성능이 크게 감소하여, 저자들이 설정한 손실 함수가 적절함을 보였습니다.
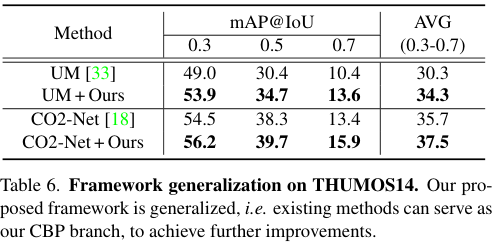
저자들은 제안한 구조가 일반적으로 좋은지 확인하고자 다른 W-TAL 방법들로 CBP를 대체하여 실험을 수행하였습니다. 그 결과, 저자들이 제안한 구조를 기존 모델들에 적용하자 성능이 오르는 것을 확인할 수 있었습니다.
Qualitative Results

정성적 결과를 보면 저자들이 주장한 것처럼 CBP는 실제 액션의 영역보다 적은 영역을 예측하는 incomplete 문제가 있고, VLP는 overcomplete 문제가 있음을 확인할 수 있습니다. 한편, 두 방법을 상호보완적으로 학습시킨 모델에서는 적절한 예측을 수행하고 있네요.
Conclusion
본 논문에서는 W-TAL에서 incomplete 문제가 있는 Classification Based Pre-training (CBP) 브랜치와 over-complete 문제가 있는 Vision-Language Pre-training (VLP) 브랜치를 상호 보완적으로 번갈아 distillation 시켜 좋은 성능을 달성했습니다.
제가 최근 읽은 Boosting Weakly-Supervised Temporal Action Localization with Text Information 논문과 같은 학회에 제출되었으며, incomplete와 over-complete 문제가 있는 브랜치들을 상호보완적으로 사용한다는 접근이 상당히 유사한데요. 비교를 해보겠습니다.
- 본 논문은 각각 incomplete, over-complete 문제가 있는 CBP, VLP 브랜치를 사용한 반면, 위 논문에서는 Text-Segment Mining (TSM)과 Video-text Language Completion (VLC)라는 상호보완적인 목표를 활용했습니다.
- 본 논문의 CBP는 기존 W-TAL 방식과 유사하게 원-핫 벡터를 라벨로 softmax로 warmup 학습됩니다.
- 한편, 위 논문의 TSM은 learnable prompt가 추가된 GloVe 기반 text embedding을 라벨로 삼아 metric loss로 학습됩니다.
- 본 논문의 VLP는 사전학습된 CLIP image/text encoder를 통해 임베딩의 유사도를 기반으로 TAL을 수행합니다.
- 한편, 위 논문의 VLC는 Vision-Language pretrained 모델을 사용하지 않으며, text completion을 목표로 학습됩니다.
- 본 논문은 두 브랜치가 서로 번갈아가며 distillation 하는 과정을 통해 학습한 반면, 위 논문은 각 브랜치의 attention 모듈이 비슷하게 작동하도록 하여 end-to-end로 학습하였습니다.
- 본 논문에서는 CBP의 warmup 이후로는 각 브랜치가 생성하는 pseudo-label만을 이용해 학습합니다.
- 한편, 위 논문에서는 학습 전체 과정에서 계속 gt-label을 이용합니다.
- 성능의 경우 본 논문이 조금 더 높습니다.
- THUMOS14 mAP@IoU [0.3:0.7]에서 본 논문은 40.8, 위 논문은 37.2 이며, ActivityNet1.2에서는 각각 29.6, 26으로 본 논문이 3% 정도 더 높습니다.
두 모델이 상당히 유사한 구조를 가져가고 있음에도, 본 논문에서 CLIP의 강력한 free knowledge를 가져다 쓴 것과, distillation 과정에서 pseudo label을 만들어 사용한 것이 유효하게 작용한 것 같습니다.
다만 distillation 특성 상 학습 과정이 복잡한 것이 약간 아쉽네요.
감사합니다.