LocVTP: Video-Text Pre-training for Temporal Localization 리뷰 (ECCV 2022)
여느 Vision 연구분야와 마찬가지로 비디오 영역에서도 자연어와 비전 feature의 align을 통해 전이 가능하고 좋은 표현력을 갖는 representation을 학습하고자 하는 Video-Text Pre-training (VTP)이 많이 연구되고 있습니다. 그러나 많은 VTP 모델들이 video-level의 정보만을 이용하는 retrieval task에 맞게 학습되어, temporal grounding과 같은 temporal localization 기반의 downstream task에서는 상대적으로 좋지 못한 성능을 보이는 문제가 있었습니다.
본 논문에서는 이러한 기존 VTP 방법들이 localization 기반의 downstream task들에 적합하지 않음을 실험적으로 보이고, 새로운 Localization-oriented Video-Text Pre-training 프레임워크인 LocVTP를 제안합니다. 이 프레임워크는 기존 비디오 전체와 텍스트 문장을 이용한 coarse-grained contrastive alignment 보다 세부적으로 클립과 단어 간의 연관성을 찾는 fine-grained contrastive alignment를 수행합니다. 또한, 학습된 feature로부터 시간적인 추론을 더 잘 수행할 수 있도록 하는 temporal aware contrastive loss를 도입합니다. 그 결과, 본 프레임워크는 retrieval 기반 task와 localization 기반 task 모두에서 SOTA를 달성할 수 있었다고 합니다.
Introduction
Video-Text Pre-training은 generic 하고 transferable 한 비디오와 언어 간의 joint representation을 학습하는 것을 목표로 하는데요. 독립된 한 가지 모달리티에서의 사전학습에 비해 이러한 방식에는 다음과 같은 장점들이 존재합니다.
- 대규모의 unlabeled video data에 자동생성된 자막을 활용하여 대규모 데이터에서 사전학습할 수 있습니다.
- 서로 다른 모달리티의 feature를 공통된 잠재 공간에 매핑하는 과정에서 cross-modal feature interaction이 가능해집니다.
이러한 장점을 통해, VTP 방법들은 많은 Video-Language downstream task에서 좋은 성과를 보였습니다.

그러나 그림 1. 의 좌측에 나타난 것처럼, video retrieval, video captioning, video question answering과 같은 Video Retrieval 기반 task의 경우 MIL-NCE 기법으로 VTP 사전학습된 모델이 video encoder와 text encoder를 별도로 사전학습한 Separately Pre-trained 방법보다 좋은 성능을 보였지만, Localization 기반의 task에서는 오히려 안 좋지 않은 성능을 보이기도 하였는데요. 이는 temporal grounding, action segmentation, action step localization과 같은 localization 기반 task들이 프레임이나 클립 단위의 더 fine-grained 한 예측을 수행해야 하는데, 이에 기존 VTP 방법이 적합하지 않았기 때문이라고 합니다.
저자들은 기존 VTP 방법들이 localization 기반 task에서 낮은 성능을 보인 원인으로 다음 두 가지 요소의 부재를 지적합니다.
- Fine-grained alignment: 기존 VTP 모델들이 영상-텍스트로 align 된 것은 너무 coarse 하기 때문에, 프레임-텍스트 혹은 클립-텍스트 수준의 더 fine-grained 한 alignment가 요구된다.
- Temporal relation reasoning: 한 클립이 해당 클립뿐 아니라 다른 클립의 액션을 감지하는데도 도움을 줄 수 있어야 한다. 예를 들어, "골프"라는 액션을 분류하는 데에는 골프공을 치는 클립뿐 아니라 골프공을 칠 준비를 하는 클립도 도움이 되어야 한다는 것이죠.
이러한 관측에 기반하여 저자들은 localization task들을 위한 새로운 video-text pre-training 프레임워크 LocVTP를 제안합니다. 앞서 언급한 두 가지 요소를 추가한 LocVTP 프레임워크는 retrieval과 localization task 모두에서 SOTA를 달성하였습니다. 특히 저자들은 클립-단어 수준의 fine-grained alignment를 수행하였는데, 기존 대규모 데이터 셋 중 이러한 annotation을 가진 데이터셋이 없었기에 coarse-grained contrastive learning을 통해 얻어진 latent space를 활용해 clip-word 유사도를 estimate 하고, clip-word 유사도가 높은 쌍들을 positive sample로 처리하는 방식으로 이를 해결했습니다.
저자들은 4개 task에서 6개 데이터셋을 가지고 실험을 진행했으며, contribution은 다음과 같이 정리됩니다.
- Retrieval 기반 task, Localization 기반 task 모두에 좋은 Localization-oriented video-text pre-training 프레임워크 LocVTP 제안
- LocVTP의 두 가지 핵심 디자인을 소개. fine-grained video-text alignment와 temporal relation reasoning
- 다양한 task에서 SOTA를 달성
Related Work
Video-Text Pre-training (VTP)
대규모 비디오-텍스트 데이터셋인 HowTo100M이 공개된 이후, VTP는 많은 관심을 얻었습니다. 이때, 주로 두 가지 방향의 접근이 있다고 합니다.
1) Generative Methods: BERT를 cross-modal 도메인으로 확장하는 방식으로, text와 visual token을 BERT 모델에 입력하여 masked token prediction을 수행하는 방식입니다.
2) Discriminative Methods: metric loss나 contrastive loss를 이용해 입력 샘플들을 구분하며 representation들을 배우는 방법들로, ClipBert, Frozen, T2 VLAD, FCA 등이 있습니다.
이러한 모델들은 k-means cluster나 graph auto-encoder를 사용하여 추가적인 오버헤드가 발생하는 반면, LocVTP는 명시적으로 clip-word matching을 모델링하여 더 가볍게 유사도 비교를 수행할 수 있다고 하네요.
Pre-training for localization tasks
비디오 수준 예측만을 필요로 하는 retrieval task들과 달리, localization task들은 dense 한 clip 혹은 프레임 수준의 예측을 요구합니다. 따라서 이러한 문제를 풀기 위해 비디오 도메인에서는 action localization을 위한 pre-training 방법들이 다양하게 제안되었습니다. BSP는 action recognition 데이터셋을 통해 temporal boundary를 합성하고 boudnary type classification을 수행하여 localization friendly feature를 생성토록 하였고 TSP는 video encoder를 temporally sensitive 하게 하기 위해 foreground clip label에 대한 예측과 clip이 액션의 안에 속하는지 바깥에 속하는지를 예측하도록 하는 방법을 통해, temporal 한 정보를 고려하는 pretraining을 수행했다고 합니다. (TSP는 김현우 연구원님이 이전에 리뷰하신 적이 있습니다!) 그러나 비디오와 언어를 사용하는 멀티 모달 환경에서는 localization task를 위한 사전학습이 제안된 적이 없었기 때문에, LocVTP는 비디오-언어 도메인에서 localization task를 위해 디자인된 첫 사전학습 프레임워크라고 합니다. TSP와 BSP가 사전학습을 위해 label을 필요로 한 반면, LocVTP는 narrated video에서 바로 학습을 수행할 수 있습니다.
Approach
먼저 영상과 자연어를 각각의 인코더 fv(⋅),fq(⋅)에 입력하여 embedded feature v,q를 얻습니다. ClipBERT에서 사용된 sparse sampling 방식을 통해 영상에서 T개의 클립을 추출하여 사용하였다고 합니다. (학습 시, 하나 또는 몇 개의 클립만을 추출하여 사용하는 방식) 따라서 영상의 feature는 v={vt}Tt=1와 같이 나타낼 수 있으며, vt∈RD 입니다. 텍스트 임베딩은 q={qs}Sqs=1와 같고, Sq는 word length of q를 나타냅니다.
LocVTP에서는 Cross-modal feature를 학습하기 위해 세 가지 contrastive method를 사용합니다.
1) 비디오-문장 alignment를 위한 coarse-grained contrastive loss
2) fine-grained contrastive loss를 적용할 클립-단어 relations를 구성하기 위한 Correspondence Discovery Strategy
3) video representation에 temporal information을 encode 하기 위한 context warping pretext task
하나씩 살펴보겠습니다.
Coarse-grained Contrastive Learning
먼저 비디오-문장 수준에서의 global contrastive alignment를 맞춰주겠습니다. v와 q를 각각 시간 축과 word index 축으로 average pooling 하여 video, sentence level feature ¯v,¯q∈RD을 얻습니다. Contrastive Loss를 통해 같은 쌍의 global feature들이 서로 유사해지도록 학습시켜 줍니다.
Lc=−logexp(¯v⋅¯q/τ)∑Ni=1exp(¯v⋅¯qi/τ)
¯qi,i∈[1,N]에서 N은 배치사이즈고 τ는 temperature입니다.
Coarse-grained contrastive loss Lc를 basic loss로 사용함으로써 기본적으로 latent space에서 cross-modal matching이 이뤄지게끔 해줍니다. coarse 하고 noisy 하기는 하지만, 이 latent space가 fine-grained clip-word correspondence discovery 이전에 기본적인 align을 맞춰줍니다.
Fine-grained Contrastive Learning
앞선 loss로 coarse-grained 비디오-문장 간 align을 맞추었으니 이제 클립-단어 간의 fine-grained contrastive learning을 수행합니다.
Clip-word correspondence discovery. 앞선 loss가 coarse 하게나마 비디오-텍스트 간의 align을 맞춰주기 때문에, 각 클립과 단어들의 코사인 유사도를 구하고, 각 클립과 가장 유사한 K개의 단어들을 선택하여 클립-단어 쌍을 얻을 수 있습니다. 클립과 가장 유사한 하나의 단어를 뽑는 대신 여러 개의 단어를 뽑아줌으로써 희미한(vague) 의미를 가진 단어가 아닌 정확한 의미를 가진 sense group을 추출하게 됩니다.
비디오와 문장 쌍 {v,q}에서 인코딩 된 t번째 비디오 클립 vt와 s번째 단어 임베딩 qs의 코사인 유사도를 구한 뒤, 각 클립과 가장 유사한 K개의 단어들을 뽑아 average pooling 하여 최종적인 positive sample로 사용합니다.
qt+=avgpool(argtopks∈[1,Sq](vt⋅qs))
즉, qt+가 vt에 대한 final positive sample이 됩니다.
유사도 계산은 각 feature를 l2 normailzation 한 후, 행렬 연산을 통해 간단히 구할 수 있습니다.
Fine-grained contrastive loss. positive pair로 선택된 클립-단어에 대하여 cross-modal InfoNCE loss로 학습을 수행합니다. 이때, negative sample로는 같은 배치 안의 다른 단어들을 사용하며, qsi는 i번째 문장 qi의 s번째 word를 의미하게 됩니다.
Lf=1TT∑t=1−logexp(vt⋅qt+/τ)∑Ni=1∑Sqis=1exp(vt⋅qsi/τ)
Temporal aware Contrastive Learning
temporal invariant feature가 중요한 video-level retrieval task와 달리, clip-level localization task에서는 temporal aware video embedding이 요구됩니다. 같은 영상 내부에서 액션과 액션, background는 모두 구분되어야 하지만, 앞선 방식의 contrastive learning에서는 이러한 특징이 반영되지 않습니다.
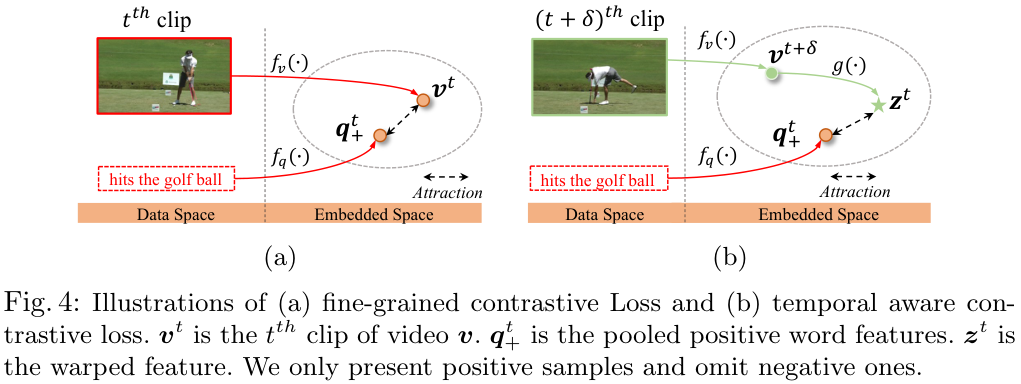
Context warping head. 이러한 문제를 극복하기 위해, 저자들은 비디오 클립의 context를 더 잘 감지할 수 있도록 context warping을 도입합니다. 앞서 구한 클립과 유사한 단어 쌍 {vt,qt+}에 포함된 클립 vt과 temporal distance δ만큼 떨어진 클립 vt+δ을 이용해 vt를 복원하는 context warping head g(⋅)를 모델에 추가하여, 모델이 temporal cue에 대한 이해를 얻을 수 있도록 합니다. 모델은 vt+δ와 δ로부터 원래 클립에 해당하는 vt와 유사한 zt를 복원하며 시간적인 이해를 얻게 됩니다.
zt=g(vtδ,δ)=ReLU(W[vt+δ,sgn(δ),|δ|])
W∈R(D+2)×D는 학습가능한 가중치이고, δ는 [−δmax 사이에서 랜덤학 샘플링된 값이며 \text{sgn}(\cdot)은 양수에 1, 음수에 -1을 출력하는 sign 함수입니다. 쉽게 말해, v^{t+\delta}를 입력받고 이게 v^t로부터 얼마나 어느 방향으로 시간이 이동된 것인지 입력받아, 원래 v^t를 복원하는 선형 계층인 것이죠.
Temporal aware contrastive loss. Context warping head를 통해 생성된 z^t는 reference featur v^t를 모사해야 하고, v^t는 q^t_+와 align 되기 때문에, 결국 z^t도 q^t_+와 align 되게 됩니다.
\mathcal L_t = \frac{1}{T}\sum^T_{t=1} -\log \frac{\exp(z^t \cdot q^t_+ / \tau)}{\sum^N_{i=1} \sum^{S_{q_i}}_{s=1}\exp (z^t \cdot q^s_i / \tau)}
이 과정을 통해 video feature를 이용한 temporal reasoning을 수행해야 할 것이 요구되어 한층 더 localization-friendly 한 feature를 얻게 됩니다. 앞선 손실함수들을 선형결합하여 최종 손실함수는 아래와 같이 정의된다. (\lambda는 가중치)
\mathcal L = \lambda_c\mathcal L_c + \lambda_f \mathcal L_f + \lambda_t \mathcal L_t
Experiments
Pre-training Settings
저자들은 세 가지 데이터셋에서 사전학습을 진행했습니다. 120만 개 이상의 영상과 ASR로 자동 생성된 자막으로 구성되어 있는 HowTo100M, 약 250만 개의 잘 align 된 web video-text 쌍으로 구성되어 있는 WebVid-2M, 330만 개의 이미지와 설명으로 구성된 Google Conceptual Captions 데이터셋입니다.
저자들은 앞선 연구들처럼 ViT-B/16에 space-time attention(timesformer)을 적용하여 비디오 인코더로 사용하였습니다. 이때, spatial attention weights는 ImageNet-21k에서 사전학습된 가중치를 사용하였고, temporal attention 가중치는 0으로 초기화했습니다. 언어 인코더로는 lightweight DistilBERT를 사용하였습니다. 이 모델은 English Wikipedia와 Toronto Book Corpus 사전학습 가중치로 초기화했습니다.
Implementation details. 각 비디오-문장 쌍에서 등간격으로(equidstantly) 추출된 16 프레임으로 구성된 8개의 클립을 샘플링하여 비디오 인코더에 입력하여 clip-level feature를 얻었습니다. 모든 프레임은 224\times 224 크기로 변환하여 사용했고, downstream transfer 시에는 학습된 모델에 16개의 이어지는(consecutive) 프레임들을 뽑아 한 클립으로 사용했습니다.
실험은 64장의 V100 GPU에서 배치사이즈 256으로 200 epoch 진행하였고, Adam optimizer에 learning rate 10^{-4}로 최적화하였습니다. learning rate decay는 0.1로 100, 160 에포크에서 적용하였고, random flip, random crop, color jitter로 augmentation을 수행하였습니다. Loss balance factor는 \lambda_c = 0.5, \lambda_f =1, \lambda_t = 1로 하였고 temperature \tau는 0.07, K는 3을 사용하였습니다. 모든 feature들은 loss에서 유사도를 계산하기 전에 l_2 normalization을 거쳤습니다.
Transfer Results on Video Retrieval
먼저 MSR-VTT 데이터셋에서의 실험을 진행했습니다. 이 데이터셋은 1만 개의 유튜브 영상으로 구성되며, 9천 개의 학습 영상과 천 개의 테스트 영상이 있습니다.
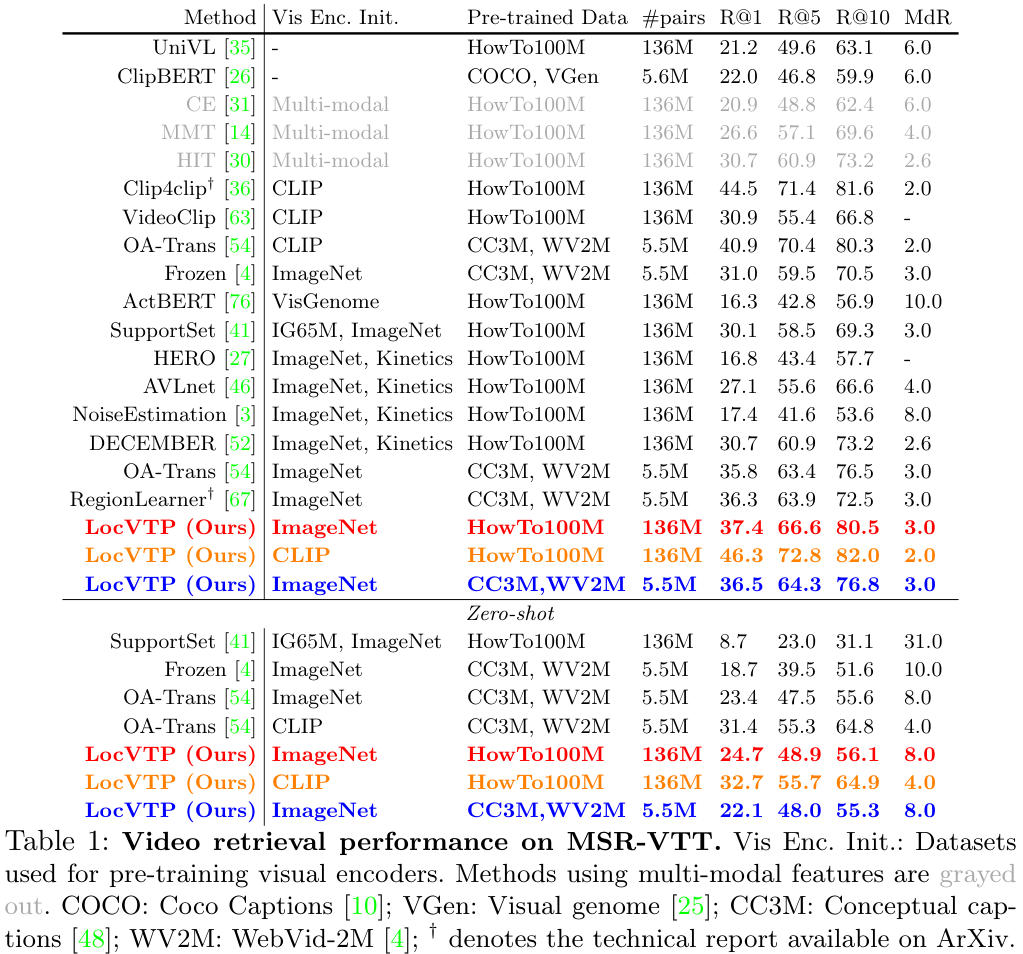
- 먼저, HowTo100M, CC3M+WV2M 두 사전학습 데이터 모두에서 SOTA를 달성하였습니다. 특히 CC3M+WV2M 데이터를 사용한 경우, Frozen을 R@5에서 4.8로 크게 앞섰습니다.
- LocVTP는 RGB 데이터만을 사용함에도, MMT와 같이 모션, 얼굴, 스피치 등 여러 모달리티를 사용하는 모델을 앞섰습니다.
- CLIP 사전학습 모델을 사용할 경우 LocVTP의 성능이 한층 더 크게 상승하는 모습을 보였습니다.
- LocVTP는 기존 방법들을 zero-shot 상황에서도 잘 이겨내어 높은 일반화 성능을 보였습니다.
Transfer Results on Temporal Grounding
untrimmed video에서 주어진 문장과 일치하는 액션을 localize 하는 temporal grounding task에서의 성능을 측정했습니다. 저자들은 주류 temporal grounding 방법론인 2D-TAN의 입력 feature를 LocVTP의 사전학습 feature로 바꾸어 학습시키고, 다른 잘 알려진 VTP 방법론 중 코드가 공개된 것들을 이용해 비교를 수행하였습니다.
데이터셋은 2만 개의 영상과 10만 개의 설명을 가진 ActivityNet Captions (ANet)과 약 15000개의 영상을 가진 Charades-STA, 약 2만 개의 영상을 가진 TACoS를 사용했습니다.
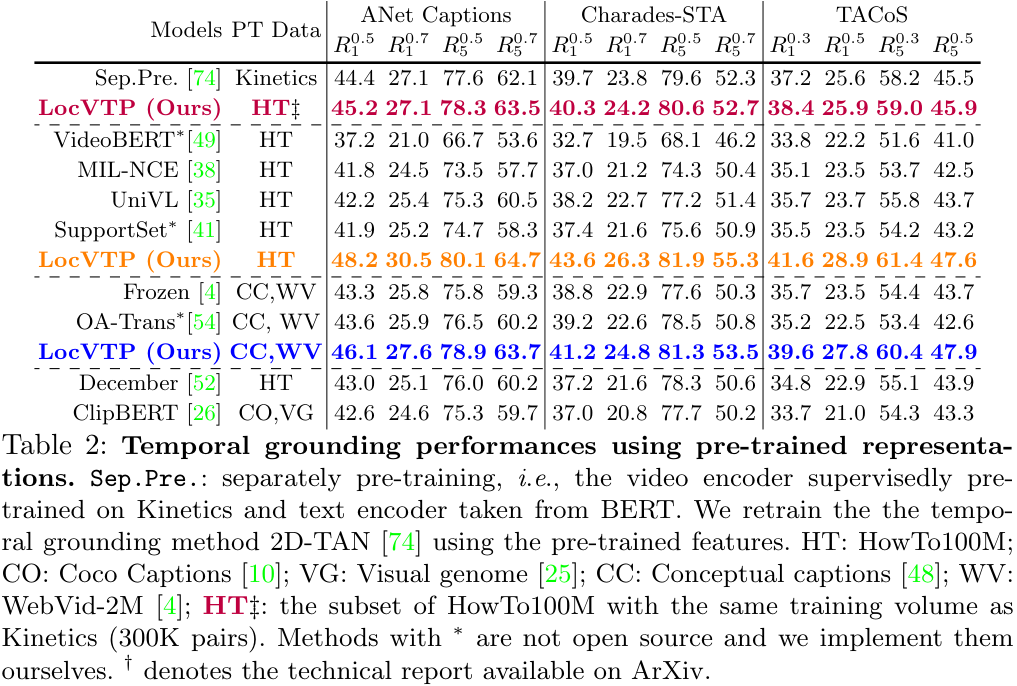
이전 연구들에 따라 R@n, IoU@m을 평가지표로 사용하였습니다. R^m_n은 top-n개의 검색된 moments 중, GT와의 IoU가 m이상인 것을 의미합니다.
- 먼저, 기존의 방법들은 각 모달리티를 별도로 학습한 Separately pre-trained 모델에 비해 훨씬 큰 데이터셋에서 학습되었음에도 좋지 못한 성능을 보였습니다.
- HowTo100M이나 CC+WV에서 학습된 경우에도, LocVTP가 기존 VTP 방법들을 큰 차이로 앞서는 성능을 보이고 있습니다.
- 더 공정한 비교를 위해, HowTo100M에서 Kinetics와 같은 수의 학습 샘플을 뽑은 결과도 실험해 보았는데, noisy 한 ASR 캡션을 사용한 데이터셋임에도 Kinetics에서 학습된 Sep.Pre. 보다 LocVTP가 더 좋은 성능을 보였습니다. 이러한 결과로 보아, 성능의 향상이 단순히 데이터 양의 증가가 아닌 모델 구조에서 왔음을 알 수 있습니다.
Transfer Results on Action Step Localization
Action Step Localization는 어떤 task의 각 단계에 해당하는 영상들이 짧은 자연어 설명과 함께 annotation 되어 제공될 때, 각 프레임을 해당하는 단계의 텍스트와 매칭해 주는 task입니다. 저자들은 Zhukov et al. 의 방법에 LocVTP를 붙여서 실험을 진행했습니다. 실험은 CrossTask 데이터셋에서 진행하였으며, average recall (CTR)을 성능 지표로 사용하였습니다.
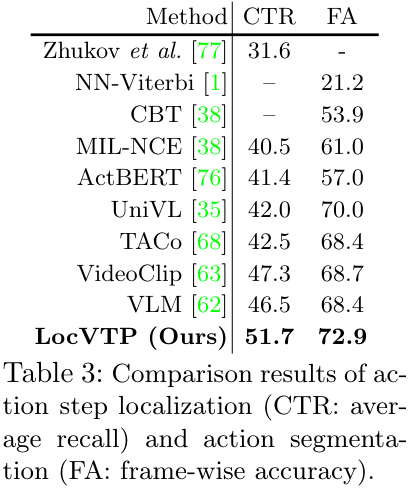
LocVTP에서도 SOTA를 달성한 모습을 볼 수 있습니다.
Transfer Results on Action Segmentation
Action Segmentation은 프레임 단위로 action label을 예측하는 task인데요. 일반적으로 pure vision task에서는 text encoder 없이 해결합니다. 저자들은 LocVTP 방식으로 학습한 video encoder 뒤에 linear classifier를 붙여서 성능을 측정하였다고 합니다. 그 결과, 위 표 3. 의 FA로 나타난 성능을 보이며 SOTA를 달성하였습니다.
Ablation Study on Training Objective
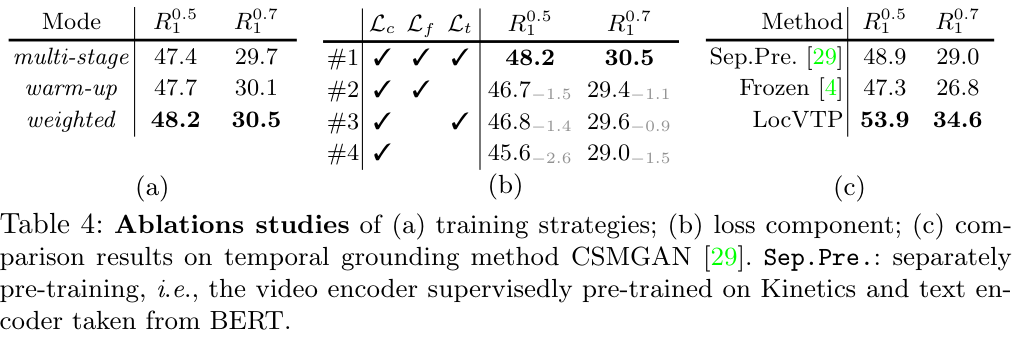
저자들은 Coarse-grained contrastive alignment los \mathcal L_c를 기본 loss로 사용하였는데, 이를 3가지 다른 방법으로 적용하였습니다. multi-stage는 먼저 coarse-grained training을 진행한 후, 이 모델을 이용해 fine-grained와 같은 다른 학습 단계들을 진행하는 방식입니다. warm-up 방식은 \lambda_c를 1부터 0까지 exponential 하게 줄여나가며 학습시키는 방식입니다. weighted는 \lambda_c를 고정된 값으로 두고 학습하는 방식입니다. 저는 논문을 읽으며 왜 multi-stage와 같은 방식을 사용하지 않았나 했는데, weighted가 가장 좋은 성능을 보였네요.
이어서 각 Loss가 미치는 영향을 보기 위한 실험을 진행하였는데, base loss \mathcal L_c에 추가한 fine-grained loss \mathcal L_f, temporal aware loss \mathcal L_t모두 중요한 역할을 함을 보였습니다.
저자들은 추가로 temporal grounding 방법론 중 CSMGAN을 downstream baseline으로 한 실험도 진행했는데요, LocVTP가 이 경우에도 성능 향상을 보이는 것을 표 c에서 확인할 수 있습니다. 이건 ablation이라기보다는 temporal grounding 실험에 넣기에 애매해서 여기 넣은 모양입니다.
Ablations on Fine-grained & Temporal aware Contrastive Loss
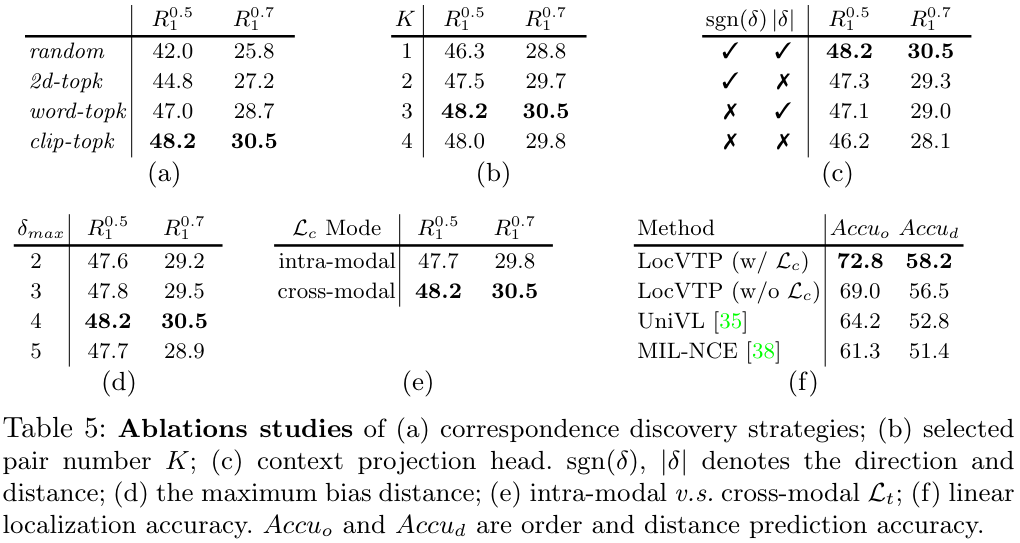
먼저 Correspondence Discovery 방식에 대한 비교입니다. random은 각 클립에서 무작위로 K개의 단어를 선택한 경우, 2d-topk는 K\times T개의 clip-word 쌍을 추출하는 방식, word-topk는 논문에서 사용한 것과 반대로 각 단어별로 가장 유사한 K개의 클립을 선정한 방식입니다. clip-topk는 각 클립별로 가장 유사한 K개의 단어를 선정한, 최종적으로 채택된 설정입니다. 기본적으로 아래 두 가지 방식이 더 좋았는데, word-topk의 경우 가끔 뚜렷한 의미가 없는 단어들에 대해서도 억지로 K개의 클립을 선정해서 결과가 안 좋은 것 같다고 합니다. 이어지는 K에 대한 ablation에서는 3이 가장 좋은 것을 볼 수 있네요.
이어서 (c)는 Context Projection Head Component에 대한 비교입니다. 앞서 \delta에 대한 sign 함수와 절댓값을 이용해 warped feature z^t를 구했는데요, 이 두 값을 각각 활용하는 경우와 그렇지 않은 경우의 성능 비교입니다. 개인적으로, \delta에 부호와 절댓값을 따로 사용하지 않고 그냥 \delta를 그대로 사용하는 경우는 왜 없는지 의문이네요.
(d)는 \delta의 최대 범위에 대한 실험입니다. 너무 적은 값을 사용하면 모델이 애초에 feature의 변화가 크지 않아 temporal 정보를 충분히 학습하기 어려울 것이고, 너무 크면 아예 feature의 의미가 너무 크게 달라져 어려울 것이라는 생각이 드는데, 4에서 가장 좋은 성능을 보이네요.
(e)에서는 Intra-modal v.s. Cross-modal Constraint에 대한 비교를 수행한다고 하는데요, \mathcal L_t에서(위 표에는 오타인지 \mathcal L_c로 되어있네요.), warped feature z^t를 같은 visual feature인 v^t가 아닌 textual feature q^t_+와 정렬해 주었는데, intra-modal의 경우는 v^t와 정렬한 경우라고 합니다. Cross-modal의 성능이 더 좋은 것을 알 수 있는데, 제 개인적인 생각에는 v^t와 정렬하게 될 경우 v^{t+\delta}로부터 temporal context를 이용해 의미 있는 과거를 추론하기보다는, v^t와 시각적으로 유사한 feature를 만드는데 집중하게 되어 그런 것이 아닌가 싶습니다.
(f)는 기존 VTP 방법론인 UniVL과 MIL-NCE와의 비교를 수행하였는데, 아래 그림 5. 의 (a)와 같이 n개의 클립을 샘플링하여 frozen video backbone에 넣고, order prediction과 distance estimation을 수행하도록 하였습니다. 두 task 모두 temporal 한 target에 대한 예측을 수행하는 task인데요. 이때 \mathcal L_t를 사용한 경우와 그렇지 않은 경우를 비교하였습니다. (표에는 \mathcal L_c라고 오기되어 있습니다.) \mathcal L_t 없이도 기존 방법론들을 앞서는 성능을 보이며, \mathcal L_t를 더하면 성능이 더욱 오르는 모습입니다.
Visualization
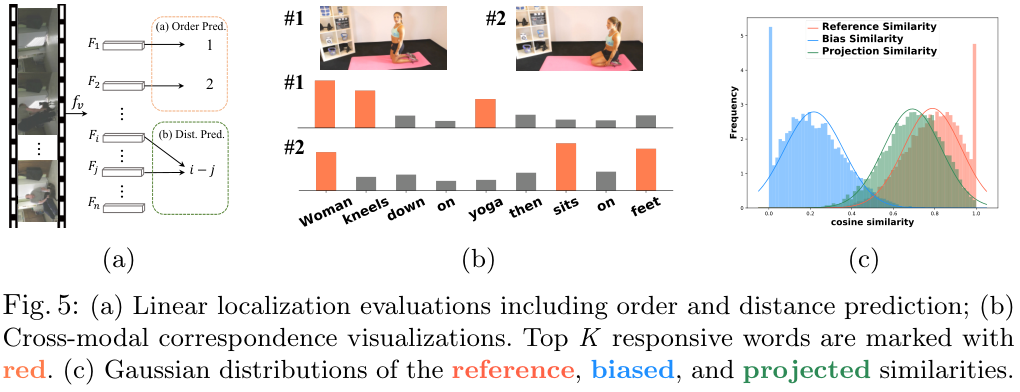
(b)는 두 개의 프레임과 각 프레임과 단어들의 유사도를 나타냅니다. Top-K (K=3) 단어들은 주황색으로 강조된 모습인데요. 정성적 결과이기는 하지만 프레임과 유사한 단어들을 잘 잡아내고 있는 모습입니다.
(c)는 유사도 분포의 시각화라고 하는데요. 1만 개의 학습 샘플에서 reference similarity (v^t, q^t_+), bias similarity (v^{t+\delta}, q^t_+), projection similarity (z^t, q^t_+)를 시각화한 모습입니다. temporal warping 결과 bias similarity가 낮아졌지만, projection을 통해 잘 회복되는 모습을 보여주네요. 근데 bias similarity에 0에 치우친 값이 많은 건 그렇다 치고, reference similarity에 1로 수렴하는 것들은 뭔가 싶습니다. training sample에서 뽑아서 overfitting이 있는 것 같은데, test sample에서 뽑았다면 분포가 이렇게 예쁘게 나오지는 않았겠다 싶네요.
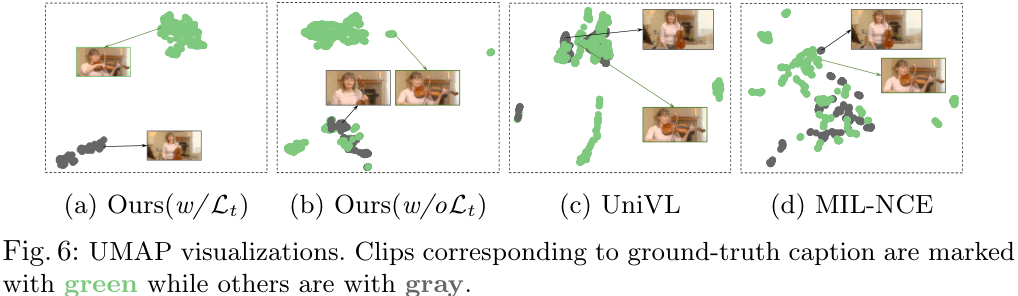
위 그림은 UMAP visualization 기법을 적용하여 LocVTP와 다른 VTP 방법들의 분포를 시각화한 결과입니다. 저자들이 제안한 방법이 상당히 구별력이 좋아 보이는데, 제가 UMAP 시각화 기법을 전혀 몰라서 확실하지는 않지만, 결과가 너무 깔끔해서 약간 cherry pick이라는 느낌도 드네요...
Conclusion
본 논문에서는 temporal localization task를 위한 첫 video-text pre-training 프레임워크인 LocVTP를 제안합니다. 이 프레임워크는 fine-grained contrastive learning과 temporal aware contrastive learning을 통해 기존 VTP 방법들보다 더 높은 성능, 특히 Localization task에서 좋은 성능을 보였습니다.
제게 인상 깊었던 부분을 정리해 보겠습니다.
- Fine-grained contrastive learning의 설계: 클립별로 top-k word를 뽑고 avg. pooling 하여 contrastive learning을 수행하는 것이 깔끔하면서도 타당한 방법인 것 같습니다.
- Context Warping Head: Temporal modeling을 위해 모델의 temporal receptive field를 늘리기 위한 방법을 사용하는 것이 아니라 temporal warping 된 feature를 reconstruct 하게 한 것이 신선합니다. 처음에는 이게 되나 싶었는데, 생각해 보니까 타당한 방법인 것 같습니다.
- Ablation Study: 비교 실험이 많아서 좋았는데, 특히 \mathcal L_t에서 cross-modal로 contrastive learning 하는 것이 흥미로웠습니다.
오늘 리뷰는 여기까지입니다!
읽어주셔서 감사합니다.
댓글을 사용할 수 없습니다.