Unsupervised Vision-and-Language Pre-training via Retrieval-based Multi-Granular Alignment 리뷰 [CVPR 2022]
오늘 읽어볼 논문은 이미지 데이터와 텍스트 데이터 간의 연관 정보가 주어지지 않은 상황에서 모달 간 정합을 수행하는 Weakly Supervised Vision and Language Pre-training (WVLP) 관련 논문입니다. 특이하게도 이 논문을 포함해 초창기 논문에서는 Unsupervised VLP라고 분야를 명명했는데, 방법론 내부에서 사전학습된 Object Detector를 사용한다는 점에서 완전한 비지도학습으로 보기 어렵다는 점이 지적되어 최근 논문에서는 약지도학습으로 부르고 있는 분야입니다.(다만 애초에 분야에 연구 자체가 활발하지는 않아서 앞으로 어떻게 될지는 모르겠습니다.)
따라서 본 리뷰에서는 원래 논문에 Unsupervised라 표현되어 있더라도 Weakly Supervised로 변환하여 부르도록 하겠습니다.
Weakly Supervised Vision and Language Pre-training
CLIP을 비롯한 Vision-Language Pre-training (VLP) 모델은 여러 분야에서 놀라운 성과를 보였습니다. 이러한 VLP 모델들은 일관된 정보를 가진 서로 다른 모달리티의 데이터 (이미지-텍스트 등)들이 유사한 feature를 갖도록 하여 cross-modal representation을 학습합니다.
그러나 이러한 모델을 학습시키기 위해서는 매우 방대한 양의 멀티모달 데이터 쌍이 필요하며, 대량의 라벨링 비용이 발생하게 됩니다. 따라서 모달리티 간의 쌍(pair)이 구성되어 있지 않은 단일 모달(uni-modal) 데이터셋들을 활용해 여러 모달리티의 cross-modal representation을 학습하고자 하는 연구가 바로 Weakly Supervised V-L Pre-training (WVLP) 되겠습니다.
Introduction
VLP 모델들은 대규모의 라벨링 된 멀티 모달 학습 데이터셋을 요구합니다. 그러나 MS COCO나 Visual Genome과 같은 crowd-sourced 데이터셋을 대규모로 구축하려면 수많은 사람의 노동력이 투입되어야 하며, Conceptual Captions (CC) 3M이나 CC 12M, SBU Captions와 같은 웹-크롤링 데이터셋은 규모는 크지만 데이터셋에 노이즈나 문제가 많아 복잡한 post-cleaning 과정이 필요합니다.
한편, 이미지나 텍스트 하나의 모달만을 다루는 단일 모달 데이터셋의 경우, 단순히 웹에서 수집하기만 하면 되기 때문에 이러한 한계에서 자유롭기에, 이러한 단일 모달 데이터셋은 컴퓨터 비전이나 자연어 처리 분야에서 self-supervised learning에 잘 활용되어 왔습니다. 따라서 저자들은 이러한 정렬되지 않은 단일 모달 데이터셋들을 활용해 VLP를 잘할 방법을 찾고자 하였습니다.
저자들은 UVLP를 각각 별도로 크롤링된 이미지 데이터 $\textbf I=\{ \textbf i_1, \textbf i_2, \cdots, \textbf i_{n^I}\}$와 텍스트 데이터 $ \textbf T = \{ \textbf t_1, \textbf t_2, \cdots, \textbf t_{n^T}\}$를 통해 멀티 모달 모델을 학습시키는 문제로 정의하였습니다.
U-VisualBERT가 이러한 WVLP 분야의 첫 연구인데요, 정렬되지 않은 텍스트와 이미지 데이터를 Object Detector를 통해 얻어진 object tag들을 두 모달리티 간의 갭을 줄이는 anchor로 활용하여 라운드-로빈 형식으로 학습시켰습니다. 이 모델은 한 번에 하나의 모달리티를 입력하는 것만으로 멀티 모달 임베딩을 학습할 수 있음을 보였지만, 사전학습 과정에서는 하나의 모달리티만 입력되는 반면, 파인튜닝 시에는 두 가지 모달리티의 입력이 주어지는 input discrepancy 문제가 있었습니다.
본 논문에서는 (1) 학습 과정에서 정렬되지 않은 이미지-텍스트 데이터라도 두 가지 모달리티를 입력하는 것이 joint embedding space 학습에 도움이 되는지, (2) 이미지-텍스트 데이터가 모델에 입력되면 이들의 latent alignment가 cross-modal representation learning에 어떤 영향을 미치는지 연구하였습니다.

연관된 이미지와 텍스트 쌍으로 구성된 Conceptual Captions (CC) 데이터셋에서 이미지와 텍스트 데이터들을 분리하여 독립된 단일 모달 데이터셋처럼 사용하였고, 이미지와 텍스트를 각각 입력하는 라운드 로빈 방식과, 랜덤하게 추출한 이미지와 텍스트(즉, 정렬되지 않음)를 같이 입력하는 두 가지 입력 방법으로 입력하여 비교하였습니다.
또한, 모든 이미지와 텍스트가 정렬되지 않은 경우(0%)와, 모든 이미지와 텍스트가 정렬된 경우(100%)까지 이미지-텍스트가 정렬된 비율에 따른 성능의 변화율도 확인하였습니다.
모든 실험에는 single-stream 트랜스포머를 사용하였고, 흔히 사용되는 사전학습 task인 Masked Language Modeling (MLM), Masked Region Modeling (MRM)으로 학습하였습니다. 사전학습된 모델은 Visual Question Answering (VQA), Natural Language for Visual Reasoning 2 (NLVR2), Visual Entailment (VE), RefCOCO+ 네 가지 vision-language task에서 파인튜닝하여 평가를 진행하였습니다.

네 가지 task에서의 성능 평균을 비교한 결과가 그림 1. 에 나타나있는데, Joint MLM+MRM이 Round-robin MLM/MRM 보다 확연히 높은 성능을 보여 입력되는 이미지와 텍스트가 정렬되어 있지 않더라도 함께 입력하는 것이 WVLP에서 좋음을 볼 수 있었습니다. 또한, 학습 데이터 중 정렬된 데이터의 비율에 따라 성능이 확연하게 올라, 정렬된 데이터 쌍이 많을 수록 성능이 오르는 것이 자명함을 보였습니다.
이러한 분석을 기반으로, 저자들은 Retrieval 기반의 Multi-Granular Alignment를 통한 Vision-Language Pre-training 모델인 $\mu-\textbf{VLA}$를 제안합니다. 이 방법론은 주어진 이미지에 object detection을 수행하여 object tags를 얻고, 이를 기반으로 retrieval을 수행하여 유사한 sentence들을 찾아 weakly-aligned image-text 데이터셋을 구축합니다. 이렇게 구성된 쌍은 noisy 하지만, latent alignment의 핵심적인 역할을 수행할 수 있다고 합니다.
저자들은 이를 기반으로 모델이 점진적으로 다양한 수준(multi-granular, 예를 들어 영역-객체, 영역-명사구, 이미지-문장) alignment를 학습하게 하여 두 모달리티 간의 간격을 줄이도록 합니다. 저자들이 제안한 모델은 4개의 downstream task에서 확연한 차이로 SOTA를 달성하였으며, 저자들은 현실적인 문제를 상정하여 텍스트 데이터를 아예 CC가 아닌 BookCorpus 데이터셋에서 가져와 실험을 추가로 진행하였습니다. 그 결과 여전히 좋은 성능을 얻어 본 방법이 robust 함을 보였습니다.
저자들의 기여는 다음과 같습니다.
- Vision-Language pre-training에 두 가지 요소가 중요함을 알아냈습니다.
- 이미지와 텍스트를 함께 입력하는 것 (두 모달리티가 정렬되어 있지 않더라도)
- 이미지-텍스트 쌍의 전체적인 정렬 정도
- retrieval 기반의 사전학습 방법을 제안하여 weakly aligned 이미지-텍스트 쌍으로 멀티 모달 학습을 가능케 함
- 실험을 통해 제안한 방법으로 WVLP에서 SOTA를 달성하였고, 현실적인 상황에서의 강건함도 보였습니다.
Related Work
제가 이전 리뷰들에서도 여러 차례 다룬 것처럼, Vision과 Language를 함께 사전학습시켜 다양한 Vision-Language Downstream Task에 활용하고자 하는 연구가 많이 진행되어 왔습니다. 이러한 연구들은 공통적으로 대규모의 멀티 모달 데이터셋을 필요로 했기에, 모달리티 간의 연관 정보가 없는 단일 모달 데이터셋들을 활용해서 이런 모델을 학습시키고자 하는 Weakly-Supervised VLP 연구(논문에서는 Unsupervised라 칭하는)가 U-VisualBERT에 의해 시작되었습니다. U-VisualBERT는 텍스트-only 데이터와 이미지-only 데이터에 대하여 masked prediction을 수행하며 object tag들을 anchor로 활용하여 두 모달리티의 간격을 줄입니다. 저자들은 MLM을 수행할 때, tag들을 문장으로 취급하여 이미지 안의 영역과 tag 사이의 tag-region level align을 수행합니다. 그러나 여전히 이러한 tag들은 문장의 완결성과 자연스러움 면에서 실제 텍스트 입력과 거리가 있어 한계가 있었는데요. 저자들은 모달리티 사이의 alignment가 중요하다고 보고, retrieval을 통해 weakly aligned V+L 데이터셋을 학습과정에서 구축하여 학습을 진행합니다. 이를 통해 U-VisualBERT와 같은 데이터셋을 활용하여 큰 성능 향상을 이룰 수 있었다고 합니다.
Method
저자들이 제안한 $\mu-\text{VLA}$ 프레임워크는 non-parallel 한 이미지, 텍스트 데이터셋으로부터 weakly aligned 이미지-텍스트 corpus를 구성하는 부분과 모델이 영역(region)-태그 (RT), 영역-명사구 (RN), 이미지-문장 (IS)의 세 가지 수준에서 cross-modal alignment를 학습하도록 하는 사전학습 커리큘럼 두 가지로 구성됩니다.

저자들은 기존 Vision-Language Model 연구들에 따라 single-stream model architecture를 구성했습니다. 메인 백본은 트랜스포머이며 이미지와 캡션의 토큰들을 concatenate 하여 함께 입력합니다. 이미지 $\mathbf i$가 주어질 때, 먼저 사전학습된 Faster R-CNN (VinVL에서 제공)을 이용해 객체 $\mathbf v = \{v_1, \cdots, v_{k^v}\}$들을 탐지합니다. 각 영역의 feature, 위치 임베딩, 모달리티 임베딩을 더하여 영역에 대한 시각적 임베딩을 생성합니다.
위치 임베딩은 5차원 벡터 $[\frac{x_1}{W}, \frac{y_1}{H}, \frac{x_2}{W}, \frac{y_2}{H}, \frac{(y_2-y_2)}{x_2-x_1}{W. H}]$이며 $(x_1, y_1), (x_2, y_2)$는 각각 감지된 영역의 좌상단과 우하단 좌표, $W, H$는 이미지의 너비와 높이입니다.
한편 캡션 $\mathbf t$는 토큰화하여 $\mathbf t = \{ t_1, \cdots, t_{k^t} \}$로 나타냅니다.
트랜스포머의 여러 셀프 어텐션 계층을 거쳐, 두 모달리티는 서로 융합되어 출력되는 hidden vector는 다양한 pre-training task에 사용할 수 있다고 합니다.
Weakly-aligned Image-Text Corpus
앞선 그림 1.에서 다룬 것처럼, 전체 이미지-텍스트 데이터 중 정렬된 데이터가 많을수록 성능이 향상됨을 알 수 있었습니다. (어찌 보면 당연한 것인데, 실험을 통해 보인 것이 꼼꼼하네요.) 따라서 저자들은 두 모달리티의 입력 간에 약하게나마 정렬을 수행하는 것이 좋을 것이라고 여기고 retrieval 기법을 통해 두 모달리티를 weakly align 하였습니다.
주어진 $\mathbf I_i$와 유사한 $k$개의 문장을 retrieval하여 align을 수행하였는데, retrieval 된 캡션이 이미지 내부의 시각적 요소(명사)와 관련이 있다는 이전 연구 결과를 참고하여 retrieval을 수행했습니다.
주어진 이미지에서 검출된 객체 $\mathbf v$들의 태그 $\mathbf o = \{ o_1, \cdots, o_{k^o} \}$를 사전학습된 Sentence-BERT 임베딩 모델에 태워 쿼리 임베딩 $\mathbf e_{\mathbf o}$를 얻고, 같은 모델에 후보 캡션 문장들을 넣어 후보 임베딩 $\mathbf e_{\mathbf t}$를 얻어 retrieval을 수행하였고, 그 결과 가장 높은 코사인 유사도를 보인 $K$개의 후보 문장을 이미지 $\mathbf i$와 짝지어 weakly aligned image-text pair를 구성했다고 합니다. 이렇게 검색된 캡션을 $\{ \mathbf t^r(\mathbf i) \}^K_{r=1}$로 나타내고, weakly aligned corpus를 $\mathbf R$로 나타냅니다.
Pre-training tasks
본 모델은 세 가지 수준의 align을 수행하여 cross-modal alignment를 학습합니다. 위의 그림 2.를 참고하여 이해하면 좋습니다.
Region-Tag Alignment Learning
먼저 이미지에서 검출된 객체들의 시각적 영역과 태그 (객체 이름)간의 정렬을 학습합니다. 검출된 객체의 태그와 영역을 $[\mathbf o, \mathbf v]$와 같이 concatenate 하여 모델에 입력합니다. 이때, 입력을 랜덤 하게 마스킹하여 masked language modeling (MLM)과 masked region modeling (MRM)을 통해 사전학습을 진행하게 됩니다. mask indices를 $\mathbf m \in \mathbb N^M$과 같이 나타내겠습니다. ($\mathbb N$은 자연수, $M$은 vocabulary size, \mathbf m은 masked indices의 집합) MLM의 목적함수는 다음과 같습니다.
$$ \mathcal L^{\text{R-T}}_{\text{MLM}} = -\mathbb E_{(\mathbf o, \mathbf v)\sim\mathbf I}\log P(\mathbf o_{\mathbf m} | \mathbf o_{\backslash \mathbf m}, v) $$
위 목적함수에 따라, 모델은 마스킹된 태그를 마스킹 되지 않은 태그 $\mathbf o_{\backslash \mathbf m}$과 이미지 영역 $\mathbf v$들로 복원해야 합니다. 한편, MRM은 마스킹된 영역을 복원해야 하는 task인데요. masked region classification loss (MRC)와 masked region feature regression loss (MRFR)로 구성됩니다.
$$ \mathcal L^{\text{R-T}}_{\text{MRM}}=\mathbb E_{(\mathbf o, \mathbf v)\sim \mathbf I} [f_{\text{MRC}}(\mathbf v_{\mathbf m} | \mathbf v_{\backslash\mathbf m}, \mathbf o) + f_{\text{MRFR}}(\mathbf v_{\mathbf m} | \mathbf v_{\backslash \mathbf m}, \mathbf o)] $$
MRC는 각 마스킹 영역의 클래스 $c(\mathbf v_{\mathbf m})$를 예측하도록 학습시키며 마스킹된 영역의 hidden output을 FC layer와 소프트맥스 함수에 입력하여 예측 $g_\theta(\mathbf v_{\mathbf m})$를 얻어 크로스 엔트로피 함수로 손실값을 계산합니다. MRFR은 마스킹된 영역의 트랜스포머 출력 $\mathbf v_{\mathbf m}$이 해당 영역의 원래 visual feature와 유사해지도록 합니다. 출력된 $\mathbf v_{\mathbf m}$을 FC layer에 입력하여 입력 feature와 동일한 차원의 $h_\theta (\mathbf v_{\mathbf m})$을 얻고, 이 특성이 원래 region feature $r(\mathbf v_{\mathbf m})$과 유사해지도록 L2 regression을 적용합니다.
$$ f_{\text{MRFR}} (\mathbf v_{ \mathbf m } | \mathbf v_{ \backslash \mathbf m}, \mathbf o)=|| h_\theta( \mathbf v_{ \mathbf m})-r( \mathbf v_{ \mathbf m}) ||^2_2$$
최종적으로 region-tag alignent learning을 위한 손실함수는 아래와 같습니다.
$$ \mathcal L^{\text{R-T}} = \mathcal L^{\text{R-T}}_{\text{MLM}} + \mathcal L^{\text{R-T}}_{\text{MRM}} $$
Region-Noun Phrase Alignment Learning
앞서 사용한 객체 태그만으로는 단어의 수가 너무 부족하기 때문에 다양한 개념을 학습하기가 어렵습니다. 따라서 저자들은 캡션에서 명사구를 추출하여 align을 수행합니다. 먼저 주어진 이미지 $ \mathbf i$에 대해 retrieval 된 문장들에서 spacy라이브러리를 이용해 명사구를 추출해줍니다. 이때 추출된 명사구에는 attribute words가 붙기도 하는데, 이로써 pre-training이 더 잘 된다고 합니다.
먼저 객체 태그와 명사구들의 word2vec 유사도를 구해 각 명사구와 연관된 영역을 매칭해 주고, MLM과 MRM을 통해 사전학습을 진행합니다. 이때, 오직 명사구나 명사구와 매칭된 영역에만 마스킹을 수행합니다. 마스킹 확률은 매칭의 유사도 점수와 비례하도록 하여, 명사구와 특정 영역이 연관이 높을수록 마스킹이 될 확률도 높아지게 됩니다. 또한, 마스킹은 한 번에 한 모달리티에만 수행하여 마스킹 영역의 복원이 연관된 다른 모달리티를 참조하도록 합니다. 영역과 명사구 간의 MLM은 아래와 같습니다.
$$ \mathcal L^{\text{R-P}}_{\text{MLM}} = -\mathbb E_{(\mathbf v, \mathbf t^r)\sim \mathbf R}\log P( \mathbf t^r_{ \mathbf m}| \mathbf t^{r}_{\backslash \mathbf m}, \mathbf v)$$
MRM에서는 pharase-guided masked region-to-token classification (p-MRTC)를 수행하도록 합니다.
$$ \mathcal L^{\text{R-P}}_{\text{MRM}} = -\mathbb E_{(\mathbf v, \mathbf t^r)\sim \mathbf R}f_{\text{p-MRTC}}( \mathbf v_{ \mathbf m}| \mathbf v_{\backslash \mathbf m}, \mathbf t^r) $$
여기서는 마스킹된 영역을 통해 연관된 명사 구를 BERT vocalbulary에서 찾도록 한다는데, vocabulary가 매우 커서 과연 잘 될까 싶지만 이러한 vocab의 확장이 MRM에 좋다고 합니다. 결과적으로, region-noun phrase alignment learning의 목적함수는 아래와 같습니다.
$$ \mathcal L^{\text{R-P}} = \mathcal L^{\text{R-P}}_{\text{MLM}} + \mathcal L^{\text{R-P}}_{\text{MRM}} $$
Image-Sentence Alignment Learning
마지막으로 기존 VLP에서도 흔히 사용된 이미지와 텍스트 간의 매칭 (ITM)을 수행해줍니다. 입력 $[\mathbf v, \mathbf t^r]$에 대하여, 최종 hidden vector의 [CLS] 토큰을 FC layer에 입력하여 두 입력 데이터가 의미론적으로 유사한지 아닌지를 $ \mathbf s_\theta ( \mathbf v, \mathbf t^r)$로 나타내도록 합니다. 라벨 $y\in\{0, 1\}$를 통해 두 데이터가 연관된 쌍인지 아닌지를 나타내었다고 합니다. 학습은 이진 크로스 엔트로피 손실함수 $\mathcal L_{\text{ITM}} = CE(y, \mathbf s_\theta( \mathbf v, \mathbf t^r))$로 진행하였습니다. 학습을 돕기 위해, 일반적인 MLM을 추가하여 모델이 visual context와 language token, 명사구, 객체 태그의 align을 학습하도록 하였습니다. $\mathcal L^{\text{I-S}_{\text{MLM}}=-\mathbb E_{(\mathbf v, \mathbf t^r)\sim \mathbf R}\log P( \mathbf t^r_{ \mathbf m}| \mathbf t^r_{ \backslash \mathbf m}, \mathbf v)}$
최종적인 image-sentence level alingnment learning 의 목적함수는 아래와 같습니다.
$$ \mathcal L^{\text{I-S}} = \mathcal L^{\text{I-S}}_{\text{MLM}}+\mathcal L_{\text{ITM}} $$
Multi-Granular Pre-training Curriculum
앞서서 굉장히 다양한 수준에서의 학습을 소개했는데, 이제 이것들을 어떻게 학습시켰는지 봅시다. 저자들은 더 잘 정렬된 이미지-텍스트 쌍으로 학습하는 것이 VLP에 좋다는 앞선 관측을 토대로, 이미지-텍스트의 정렬 정도를 추정하여 학습을 진행하는데 활용했습니다. Image-Sentece Alignment Learning 과정에서 정의한 ITM header를 통해 이미지와 텍스트의 정렬 정도를 계산하여 retrieval based pretraining task의 입력 데이터에 대한 가중치로 활용하였는데, 이를 통해 학습이 진행됨에 따라 더 잘 정렬된 입력 쌍을 사용하게 되어 학습에 도움이 되었다고 합니다.
ITM classifier를 학습시키기 위하여, 처음에는 retrieval을 통해 weakly align된 corpus $\mathbf R$을 양성 샘플, 랜덤 하게 추출된 쌍들을 음성 샘플로 하여 $m$ epoch warmup 학습을 진행했습니다. 그다음, ITM이 생성하는 alignment prediction score $w_{\text{ITM}}$를 학습 목적 함수에 아래와 같이 반영하였습니다.
$$ \mathcal L = \begin{cases} \mathcal L^{\text{R-T}} + \mathcal L^{\text{R-P}} + \mathcal L^{\text{I-S}} &\text{if epoch } < m \\
\mathcal L^{\text{R-T}} + w_{\text{ITM}}(\mathcal L^{\text{R-P}} + \mathcal L^{\text{I-S}}) &\text{if epoch }\geq m\end{cases}$$
저자들은 최종 실험에서 $m=1$을 적용했다고 합니다.
Experiments
저자들은 두 가지 세팅에서 실험을 진행했습니다. (1) Conceptual Captions (CC) 데이터셋에서 이미지와 텍스트 사이의 매칭 정보를 제거하고 사용한 경우와 (2) CC 데이터셋에서 이미지를 가져오고 BookCorpus (BC) 데이터셋에서 텍스트를 가져온 경우입니다. 첫 번째 환경은 이전 모델들과 공정한 비교를 위해 동일한 설정을 사용한 것으로, 아래에서 $\mu-\text{VLA}_{CC}$로 표시하였고, 두 번째 환경은 이미지와 텍스트가 정렬되어 있지 않은 현실적인 상황을 모사한 것으로 $\mu-\text{VLA}_{BC}$로 표시하였습니다.
앞서 설명한 것처럼 각 이미지 별로 5개의 텍스트 데이터를 retrieval 하여 weakly aligned 이미지-텍스트 쌍을 구성하는 것으로 실험을 시작하였습니다.
Baselines
Base Model은 BERT로 초기화된 VisualBERT입니다. 별다른 사전학습 없이 바로 downstream task에 파인튜닝하였다고 합니다.
Supervised Pre-trained Models는 지도학습 방식의 VLP 모델로, CC 데이터셋에서 사전학습한 VIL-BERT, VL-BERT, UNITER 모델과 U-VisualBERT 논문에서 공유한 CC, CC+BC 등 다양한 환경에서 학습된 Supervised VisualBERT 모델들을 포함하였고, CC 데이터셋에서 이미지-캡션으로 학습된 모델과 이미지-태그로 학습된 모델인 Aligned VLP의 성능까지 공유하였습니다.
Weakly-supervised Pre-trained Models는 U-VisualBERT로 이미지 혹은 텍스트 단일 모달에서 라운드 로빈 형식으로 학습하였으며, 이미지에서 감지된 객체 태그를 anchor로 사용해 cross-modal alignment를 학습하였습니다. 저자들은 공정한 비교를 위해 Vanilla Faster R-CNN을 사용한 U-VisualBERT를 VinVL과 BC 데이터셋 등 본 논문에서 사용한 요소들을 반영해 재구현 했습니다.
Training Setup
모델은 12개의 트랜스포머 블록으로 구성되며, 각 블록은 768개의 hidden unit과 12개의 self-attention head를 가집니다. 초기화는 $\text{BERT}_{base}$로 진행하였고, 480 배치 사이즈에서 20 에포크 사전학습된 모델을 사용했습니다. Region feature는 사전학습된 VinVL Object Detector로 얻었다고 하는데, 해당 모델이 R-CNN의 변형 같기는 한데 정확하지 않아서 한번 찾아봐야겠습니다. 학습은 Adam Optimizer를 이용해 학습의 첫 10%는 linear warm-up을 진행하였고, peak learning rate를 6e-5로 설정하였습니다. warmup 이후에는 linear decay를 적용해 learning rate를 감소시켰다고 합니다.
모든 모델은 A100 4장에서 MMF를 이용해 GPU 당 40GB 메모리씩 나뉘어 학습했으며, 사전학습에 3일이 소요되었습니다. 사전학습한 모델은 Visual Question Answering (VQA 2.0), Natural Language for Visual Reasoning ($\text{NLVR}^2$), Visual Entailment (VE), Referring Expression (RefCOCO+) 네 종류의 downstream task에서 테스트하였습니다.
Experimental Results
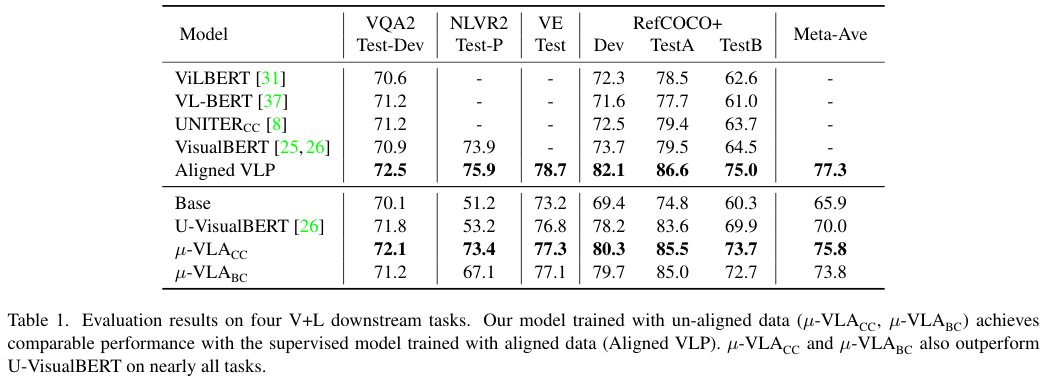
제안된 방법을 4가지 downstream task와 각 task에서의 성능을 모두 반영한 Meta-Ave 점수로 비교한 결과, 제안된 방법이 모든 task에서 Base를 앞서는 성능을 보였습니다. Supervised VLP와 비교해 보면, VilBERT를 크게 앞선 결과를 보였으나 이는 VinVL이라는 더 좋은 visual regional feature를 사용하였기 때문으로 볼 수도 있다고 합니다. 다만 $\mu-\text{VLA}$와 비슷한 구조의 Aligned VLP와 비교했을 때 그렇게 낮지 않은 성능을 보여 제안한 방법이 parallel 이미지-텍스트 데이터 없이도 supervisied 방법에 근접할 정도로 좋은 성능을 보였다고 합니다. 한편 기존 Weakly supervised 방법과 비교할 경우에도 좋은 성능을 보였는데, 특히 이미지와 문장 간의 align에 민감한 NLVR2 task에서 20% 이상의 성능 향상을 보여주어 제안된 모델이 parallel 데이터 없이도 이러한 instance-level cross-modal alignment를 잘 학습할 수 있음을 보였습니다.
한편, CC와 BC라는 별도의 데이터셋에서 얻은 이미지, 텍스트로 학습한 $\mu-\text{VLA}_{BC}$도 U-VisualBERT와 견줄만하거나 더 좋은 성능을 보이면서 제안한 모델이 실용적이기도 함을 볼 수 있었습니다.
Ablation Study

앞서 제안한 3가지 단계의 alignment의 실효성을 보이기 위한 비교 실험 결과입니다. 이미지 속 영역과 객체 태그 (R-T) 혹은 명사구 (R-N)와의 관계를 학습하는 것이 특히 객체에 대한 이해를 요구하는 RefCOCO+ 데이터셋에서는 도움이 되는 모습입니다. 한편, 이미지와 문장을 instance-level로 매칭하는 (I-S)는 NLVR2와 VE의 성능을 향상합니다. 이러한 결과는 전체적으로 아무리 약한 align이라도 주어진느 것이 각 downstream task 성능에 큰 영향을 준다는 것을 시사합니다.

한편, 한 이미지당 retrieve 되는 후보 텍스트의 수에 따른 비교도 진행하였는데요. 이는 전체 데이터셋의 크기에 따라 다를 것 같은데, CC 데이터셋에서는 5가 최고의 성능을 보였다고 합니다. 특히, 2개 이상의 후보 텍스트를 사용하는 것이 좋은데, 그 이유는 검색에 활용되는 객체 태그와 후보 텍스트 간의 유사도가 높다는 것이 언제나 두 모달이 의미론적으로 유사함을 보장하지는 않기 때문에, 몇 개의 다른 후보 텍스트가 있는 것이 도움이 되는 것 같다고 합니다.
정성적 결과

위 사진은 주어진 이미지와 매칭할 후보 텍스트를 CC, BC 데이터셋에서 retrieve 한 결과입니다. 표에서 맨 첫번째 줄은 실제 CC 데이터셋에서 이미지와 매칭되어 있는 텍스트 (즉 GT), 두번째는 VinVL로 검출한 객체, 마지막은 각 데이터셋에서 retrieve한 결과입니다. 위의 예시에서 CC 데이터셋의 텍스트로부터 "young woman"과 "sofa" 등이 들어간 문장들을 잘 가져온 것뿐만 아니라, 아래 예시에서 CC 데이터셋이 아닌 BC 데이터셋에서도 적절한 텍스트를 잘 가져오는 모습을 볼 수 있습니다.

저자들은 마지막으로, 별다른 파인튜닝 없이 U-VisualBERT와 제안한 모델에 이미지와 텍스트를 입력한 후, self-attention을 시각화해보았는데요. 제안한 모델이 앞선 모델에 비해 더 뚜렷하게 중요한 부분에 어텐션을 하고 있는 모습을 볼 수 있었습니다.
Conclusion
저자들은 retrieval-based multi-granular alignment를 통해 weakly supervised vision-language pre-training을 진행할 수 있는 모델을 제안하였습니다. 이 모델의 핵심은 (1) retrieval을 통해 weakly-aligned image-text corpus를 생성하고, (2) multi-granular pre-training objective를 통해 모델이 여러 수준에서 cross-modal alignment를 학습할 수 있도록 한 것이었습니다.
이 정도로 연구가 안 된 분야의 논문을 보는 것은 처음이라 신선한 경험이었는데, 정렬이 전혀 되어있지 않은 모달리티를 retrieval 기반 방법으로 정렬하고 학습시켜 supervised에 준하는 성능을 보이는 것이 정말 놀라운 방법론이었습니다.
특히 라벨이 없는 상황에서, VinVL이나 BERT, word2vec 등 가용한 모든 방법을 동원해 supervised에 준하는 training signal을 만드는 것이 대단하네요.