Open-Vocabulary Object Detection via Vision and Language Knowledge Distillation 리뷰 [ICLR 2022]
이번에 리뷰할 논문은 Open-Vocabulary Object Detection이라는 task를 제안한 논문입니다. 본 논문에서는 Object Detector가 검출 가능한 객체의 종류를 늘리기 위해 학습 데이터에 포함된 객체의 종류를 늘리는 것은 비용 문제가 크다는 한계를 극복하기 위해, 학습 데이터를 늘리는 대신 CLIP과 같은 사전학습된 Open-Vocabulary Object Classifier의 지식을 distillation 하는 방식을 제안합니다.
Object Detection (OD)에서 검출 가능한 객체의 종류를 늘리는 일반적인 방법은 학습 데이터셋에 포함된 객체의 종류를 늘리는 것 입니다. 실제로 최근에는 1,203 종류의 객체를 담고 있는 데이터셋인 LVIS가 등장하기도 하였습니다. 그러나 데이터셋에 포함된 객체의 종류가 늘어날 수록 어떤 객체는 데이터셋 전체에 많이 등장하고 어떤 객체는 조금 등장하는 클래스 불균형 문제가 발생하게 됩니다. (예를 들어, 자율주행 데이터셋을 만든다고 생각하면 보행자와 차량의 수는 많을 수 있지만, 고라니와 같은 야생동물은 상대적으로 적게 등장할 것입니다.) 따라서 객체의 종류가 증가함에 따라 필요한 데이터의 양 또한 선형적이 아닌 기하급수적으로 증가하게 되고, 데이터셋 구축에 막대한 비용이 요구되게 되는 것이죠.
따라서 저자들은 Object Detector가 제한된 소수의 클래스(closed-vocabulary)가 아니라 매우 다양한 클래스(open-vocabulary)에 대한 예측을 수행하도록 하기 위해서는 데이터를 증가시키는 방식이 아니라, CLIP과 같은 open-vocabulary object classifier가 가진 지식을 활용해야 한다고 주장합니다.
Introduction
저자들은 일반적인 Object Detection 데이터로 학습하면서도 해당 데이터셋에 포함되지 않은 novel category에 대한 예측까지 수행할 수 있는 Open-Vocabulary Object Detection (OVOD) 모델을 만들고자 합니다.
이를 위해, Bounding Box와 Class Label을 포함해 취득이 어려운 Object Detection 데이터셋이 아닌, 인터넷상에서 쉽게 취득할 수 있는 paired image-text 데이터로 학습된 Vision-Language Pretraining (VLP) 모델에 주목합니다.
아시다시피, CLIP은 4억 개의 이미지-텍스트 페어에서의 학습을 토대로 분류하고자 하는 객체의 텍스트를 이용해 zero-shot classification (open-vocabulary classification)을 수행할 수 있습니다. (CLIP 리뷰)
저자들은 이러한 Image-level representation 지식을 object-level로 가져와, object detection에서도 분류하고자 하는 객체의 텍스트(arbitrary text)만 있다면 detection을 수행할 수 있도록 하고자 합니다.

저자들은 먼저 단순한 실험을 통해 본 방법의 현실성을 점검합니다. R-CNN과 같은 two-stage detector의 접근 방식을 토대로 OVOD를 아래와 같은 두 가지 sub-problem으로 분할하는데요.
- Generalized Object Proposal
- Open-Vocabulary Image Classification
먼저, Region Proposal Network는 학습 데이터에 포함된 base category 이외에도 새로이 등장한 novel category들의 위치까지 잘 검출하여 ROI (region of interest)를 생성해 줄 수 있어야 합니다. 이렇게 생성된 ROI를 이미지에서 crop 하여 잘 동작하는 OVOC 모델에 입력하면, 결과적으로 OVOD를 수행할 수 있는 것이죠.
저자들은 LVIS 데이터셋에서 드물게 등장하는 rare category들을 novel category 삼고, 나머지를 base category 삼아 위 방식의 실험을 진행하였습니다. 놀랍게도 그 결과 지도학습 방법론 보다도 높은 성능을 보일 수 있었으나, object proposal을 생성하여 crop 하고, 하나하나 분류 모델에 입력하기 때문에 추론 속도가 매우 느린 단점이 있었습니다.
저자들은 위 방식의 단점을 보완하여 ViLD (Vision and Language Knowledge Distillation) 모델을 제안합니다. ViLD는 아래와 같은 두 가지 요소로 구성됩니다.
- learning with text embeddings (ViLD-text)
- learning with image embeddings (ViLD-image)
ViLD-text는 Object Detector의 classifier를 VLP 모델의 이미지-텍스트 유사도 기반 분류 방식으로 바꾸어 학습을 진행하며, 이 과정에서 ViLD 모델이 base category와 novel category 모두에 대한 general object proposal이 가능하도록 학습시킵니다.
ViLD-image에서는 Object Detector가 생성하는 region embedding이 VLP 모델의 image embedding과 align되도록 distillation을 진행합니다. 이를 통해 region proposal은 RPN으로, classification은 별도의 VLP 모델로 수행한 앞선 실험의 한계를 극복할 수 있었다고 합니다.
저자들은 ViT 기반의 CLIP과 EfficientNet 기반의 ALIGN을 Teacher 모델로 사용하여 성능을 비교하였습니다. 그 결과 ViLD는 LVIS novel category에서 16.1 AP를 달성하여 지도학습 기반의 3.8을 앞섰고, 더 좋은 teacher model인 ALIGN을 적용한 결과 26.3까지 성능을 향상할 수 있었다고 합니다.
Related Work
모델이 다룰 수 있는 객체의 종류를 늘리는 것은 컴퓨터 비전 분야에서 오랜 연구 주제 중 하나였습니다. 학습 단계에서 주어지지 않았던 객체를 인식하고자 하는 zero-shot recognition은 오랜 기간 연구되었고, 최근 CLIP과 ALIGN 등의 모델이 이미지-텍스트 간의 align을 수행하면서 마침내 좋은 결과를 얻을 수 있었습니다. 그러나 아직 image-level이 아닌 object-level에서는 별다른 성과가 없는 상황이었다고 합니다.
Increasing vocabulary in object detection. 초기 연구들은 여러 데이터셋을 병합하여 객체의 종류를 늘리려고 하였으며, 최근 Joseph et al. (2021)은 unknown object에 대한 incremental learning을 수행하는 Open-World Object Detection을 제안하기도 했습니다. 학습 데이터셋에 속한 base category의 region feature와 사전학습된 text embedding을 정렬시키는 방식의 Zero-Shot Detection (ZSD)도 연구되었으나, 이들은 지도학습 기반 방법론들과 큰 성능 차이가 존재했다고 합니다.
이러한 문제를 극복하고자 Zareian et al. (2021)은 백본 모델을 이미지 캡션을 통해 사전학습하고 detection 데이터셋을 통해 파인튜닝을 수행하는 방식을 시도하였는데, 본 논문에서는 기존 방법들과 달리 사전학습된 이미지-텍스트 모델을 teacher model 삼아 distillation을 수행하는 방식으로 연구를 진행하였는데, 앞선 방법론들은 10여 종류의 클래스에서 평가되었으나, 이 방법은 1000개 이상의 클래스에서 평가하였다고 합니다.
Method
학습 단계에서 라벨이 주어지는 클래스인 base category를 CB, 주어지지 않는 클래스인 novel category를 CN라 하고, T(⋅),V(⋅)는 각각 사전학습된 open-vocabulary 분류기의 text와 vision encoder를 나타냅니다.
저자들은 먼저, Naive하게 Localization과 Classification을 따로 하는 방법을 소개하고 ViLD 방법을 소개합니다.
Localization for Novel Categories
OVOD의 첫 단계는 학습 데이터에 라벨이 존재하지 않는 novel object의 위치를 탐지하는 것입니다. 저자들은 Mask R-CNN과 같은 일반적인 two-stage object detector를 개조하였는데, 먼저 bounding box regression이나 mask prediction layer와 같은 class-specific localization 모듈들을 class-agnostic 하게 general object proposal을 수행할 수 있는 모듈로 대체한다. 이 모듈은 기존과 달리 각 Region of Interest (ROI)에 대하여 단 하나의 bounding box만을 생성하고, 각 클래스마다 마스크를 생성하던 기존 방법과 달리 전체 클래스에 대하여 하나의 마스크만 생성합니다. 이러한 class-agnostic module은 novel object에도 잘 일반화된다고 합니다. (제가 Mask R-CNN을 몰라 이 부분은 사실 정확히 모르겠네요.)
Open-Vocabulary Detection with Cropped Regions
객체 후보의 위치를 찾은 후, open-vocabulary 이미지 분류기를 통해 각 영역에 대한 분류를 수행합니다.
이미지 임베딩: proposal network를 base category CB로 학습시켜 region proposal ˜r∈˜P를 오프라인으로 생성하고 제안된 영역을 crop 및 resize 한 다음 사전학습된 이미지 인코더 V에 입력하여 image embedding V(crop(I,˜r))을 얻습니다. (I는 이미지)
이미지를 1×과 1.5×크기로 crop하여 임베딩하고 앙상블을 수행하여, 1.5×는 context cue, 1×는 세부적인 정보를 담도록 했다고 합니다. 앙상블 된 임베딩은 unit norm을 이용해 정규화해 줍니다.
V(crop(I,˜r{1×,1.5×}))=v||v||,where v=V(crop(I,˜r1×))+V(crop(I,˜r1.5×))
텍스트 임베딩: 각 카테고리 텍스트를 "a photo of {class} in the scene"이라는 프롬프트로 텍스트 인코더 T에 입력하여 오프라인으로 텍스트 임베딩을 얻습니다. 추가적인 프롬프트나 동의어가 존재할 경우 이 또한 앙상블 하여 사용하였다.
그다음, 이미지와 텍스트 임베딩의 코사인 유사도를 구하고, softmax를 적용하고, class별 NMS를 통해 최종 detection 결과를 얻게 됩니다. crop 된 region들을 V에 모두 입력해야 하기에 예측 속도가 매우 느려진다고 합니다.
ViLD: Vision and Language Knowledge Distillation
따라서 앞선 방법의 느린 예측 속도를 극복하기 위한 방법인 ViLD가 마침내 제안됩니다. 먼저 two-strage detector에서 proposal r을 생성해 줍니다. 각 region embedding은 R(ϕ(I),r)으로 나타내며, ϕ(⋅)은 백본 모델, R(⋅)은 region embedding을 생성하는 lightweight head를 의미합니다. classification head 직전에 output을 취하여 region embedding으로 사용하게 됩니다. 그림 3의 (a), (b)를 비교해 보시면 이해하기가 쉽습니다.
Replacing classifier with text embeddings. 먼저 ViLD-text에 대한 설명입니다. region embedding을 classification layer에 입력하여 분류를 수행한 기존 모델 구조를 text embedding과의 유사도 계산을 통한 분류 방식으로 변경해 줍니다. 이때, 학습 단계에서는 base category의 임베딩 T(CB)만을 사용하여 base category에 대한 분류를 수행해 주고, GT값이 CB에 속하지 않은 region proposal들은 background 카테고리로 분류되도록 학습을 진행합니다. 이때, "background"라는 텍스트와 background region들이 유사한 것은 아니므로 background를 처리하기 위한 학습 가능한 임베딩 ebg를 사용해 줍니다.
각 region embedding R(ϕ(I),r)과 카테고리 임베딩 T(CB),ebg의 코사인 유사도를 구하고, temperature τ의 softmax를 적용하여 CE Loss를 계산해 줍니다. 이러한 과정을 통해 region proposal network가 novel category를 포함해 다양한 object들의 위치를 proposal 할 수 있게 됩니다. 손실함수를 정리하면 아래와 같습니다.
er=R(ϕ(I),r)sim(a,b)=a⊤b/(||a||||b||)z(r)=[sim(er,ebg),sim(er,t1),⋯(er,t|CB|)]LViLD-text=1N∑r∈PLCE(softmax(z(r)/τ),yr)
N은 이미지에 포함된 proposal의 수이고, LCE는 cross entropy loss입니다.
예측 과정에서는 novel category CN을 포함하여 T(CB∪CN)을 사용하여 예측까지 수행하며, 실험 세팅에 따라 novel category 만의 성능을 보기 위해 T(CN)을 사용하기도 했다고 합니다.
Distilling image embeddings. 이어서 ViLD-image를 소개하는데, 이는 teacher 모델의 image encoder V를 student detector에 distillation 시키는 과정입니다. 복잡할 것 없이 detector가 생성하는 region embedding R(ϕ(I),˜r)이 image embedding V(crop(I,˜r))과 align 되도록 학습합니다.
학습 과정을 효율적으로 진행하기 위해, 각 학습 이미지의 ˜r∈˜P에서 M개의 proposal을 미리 오프라인으로 뽑아두고, M개의 이미지 임베딩을 미리 만들어 두고 사용합니다. 이때, 각 region이 어떤 클래스인지는 학습에 필요하지 않기 때문에, proposal들은 CB와 CN을 모두 포함하게 되며, 덕분에 distillation이 더 다양한 객체애서 수행되게 됩니다.
L1 loss를 통해 두 임베딩의 거리가 최소화되도록 아래와 같이 학습을 진행합니다.
LViLD-image=1M∑˜r∈˜P||V(crop(I,˜r{1×,1.5×}))−R(ϕ(I),˜r)||1
결과적으로 ViLD의 전체 손실함수는 아래와 같습니다. w는 가중치 하이퍼파라미터이며 전체적인 모델 구조는 그림 3 (d)와 같습니다. 예측 과정에서는 ViLD-image의 distillation이 필요 없으므로 해당 부분은 연산되지 않습니다.
LViLD=LViLD-text+w⋅LViLD-image
Model Ensembling
저자들은 base와 novel category에서 최고의 성능을 달성하기 위한 모델 앙상블도 시도하였습니다. ViLD-text detector를 open-vocabulary image classification 모델들과 합쳐보았는데, ViLD-image가 이러한 모델들로부터 distillation을 통해 학습하기에 아예 teacher 모델을 바로 사용하면 더 좋지 않을까 하는 아이디어였다고 합니다. ViLD-text로부터 k개의 후보 region과 confidence score를 생성합니다. pi,ViLD-text는 category i에 대한 proposal ˜r에 대한 confidence score를 나타냅니다. 제안된 영역을 crop 하여 분류 모델에 입력하고, confidence score pi,cls를 얻습니다. 두 모델이 base category와 novel category에 각각 다른 정확도를 보이므로, 두 모델 예측의 결과에 가중치 λ를 부여하여 geometric average를 사용해 앙상블을 수행했습니다.
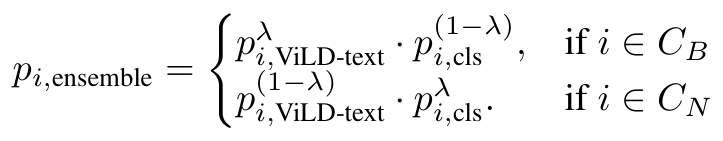
λ는 2/3을 사용하여 base category에서는 ViLD-text의 예측이, novel category에서는 open-vocabulary classification model의 예측이 크게 작용하도록 했습니다. 이러한 방법은 결과적으로 Open-Vocabulary Detection with Cropped Regions 방법과 유사한 느린 예측 속도를 보였으나, ViLD-text의 CE loss와 ViLD-image의 L1 loss가 contention을 일으킬 수 있는 ViLD 방법과 달리 학습 과정에서 이러한 위험이 없다고 합니다. 저자들은 이 모델을 ViLD-ensemble로 명명하였습니다.
Experiments
저자들은 ResNet과 FPN 백본을 사용하는 Mask R-CNN을 백본으로 사용하였습니다. 입력 이미지는 1024×1024 크기를 사용했고, [0.1,2.0] 범위의 large-scale jittering augmentation, synchronized batch normalization을 적용했으며, batch size 256, weight decay 4e-5, initial learning rate 0.32를 적용하여 모델을 처음부터 180,000 iteration 학습하였으며, 전체 iteration의 0.9×,0.95×,0.975×에 해당하는 때 learning rate를 10으로 나누어 주었습니다. CLIP 모델은 공개된 ViT-B/32를 사용하였고, τ는 0.01, 이미지 당 최대 검출 수는 300을 주었습니다. 더 자세한 정보는 논문의 Appendix D에 있다고 합니다.
Benchmark Settings
대체로 LVIS에서 실험을 진행하였으나, 이전 연구와의 비교를 위해 다른 데이터셋들도 사용하긴 했습니다. LVIS는 LVIS v1. 을 사용하였는데, 1,203개의 다양한 category 중에서 866개의 자주 등장하는 category를 base category CB로 삼고 나머지 337개의 category를 novel category CN로 하였습니다. CN에서의 AP를 나타내는 APr이 주된 평가지표로 사용되게 됩니다.
한편, COCO-2017 데이터셋에서도 48개의 base category와 17개의 novel category를 취하여 사용했는데, 15개의 category는 WordNet hierarchy 관련 문제로 인해 제외했다고 합니다. 이 부분도 detection이 낯설어서 잘 이해가 되지 않네요. 필요하다면 더 찾아봐야겠습니다.
Learning Generalizable Object Proposals

먼저, base category에서 학습된 detector가 novel category도 잘 localize 할 수 있는가에 대한 실험입니다. ResNet-50 백본을 사용한 Mask R-CNN의 Region Proposal Network로 실험을 진행하였는데, base만을 이용해 학습을 진행해도 base와 novel 모두를 이용해 학습한 것에 비해 Average Recall이 2 정도밖에 감소하지 않는 모습입니다.
저자들은 unseen category generalization에 특화된 proposal network를 사용하면 성능이 더욱 향상되겠지만, 이는 추가 연구로 남겨두었다고 합니다.
Open-Vocabulary Classifier on Cropped Regions
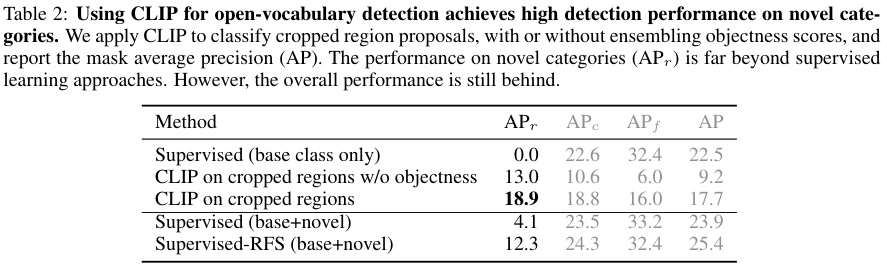
앞서 저자들이 ViLD를 제안하기 전에 실험한, Region Proposal 후 CLIP을 이용해 분류를 수행한 결과입니다. 저자들은 추가로 Region Proposal Network가 생성한 objectness score와 CLIP의 confidence score를 geometric mean으로 앙상블해 보았는데요. 그 결과 13.0에서 18.9로 성능이 한층 더 향상되었습니다.
한편, Supervised 모델과의 비교를 보면 balanced sampling을 통해 rare category를 잘 다루고자 한 Supervised-RFS보다도 CLIP을 사용한 모델이 APr이 더 높은 모습인데요. 이는 Open-vocabulary Classifier를 사용하는 것이 확실히 novel category 예측 성능을 향상함을 보여줍니다. 그러나 APc,APf를 포함한 전체적인 성능은 아직 supervised 모델이 앞선 모습입니다.
Vision and Language Knowledge Distillation
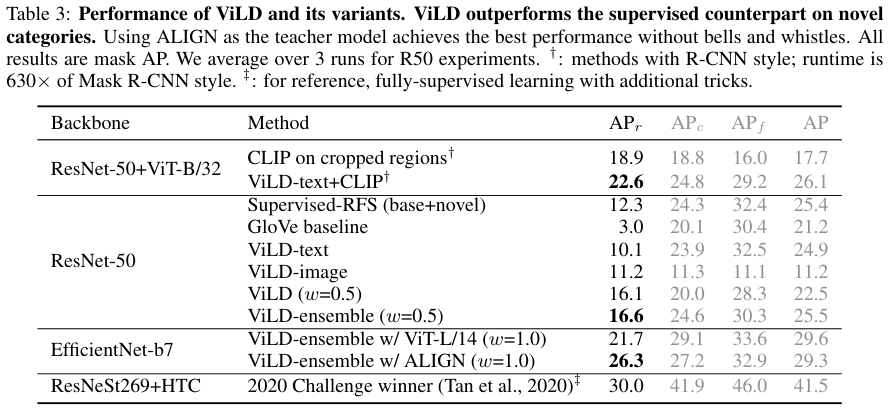
마침내 ViLD 성능입니다.
Text embeddings as classifier (ViLD-text). 먼저 CLIP의 text-embedding과 유사도로 분류를 수행하는 ViLD-text 성능입니다. GloVe의 텍스트 임베딩을 사용한 모델이 3.0의 APr을 보여주는 반면, 10.1로 훨씬 좋은 성능을 보여줍니다. 같은 텍스트 임베딩이라도 이미지와 함께 학습된 것이 낫다는 것을 보여주네요. 한편, base category에서 학습된 ViLD-text가 CLIP on cropped regions 보다 좋은 APc,APf를 보여주는 반면, novel category에 대한 APr은 더 뒤처지는 모습을 보여주어 일반화 성능이 좋지 않음을 알 수 있습니다.
Distilling image embeddings (ViLD-image). cropped region proposal이 CLIP image embedding과 유사해지도록 학습된 모델입니다. object category label 없이 학습을 진행했음에도 ViLD-image는 11.2의 APr을 보여줍니다. 그러나 APc,APf는 가장 낮은 수준으로, CLIP을 distillation 하는 것이 CLIP on cropped regions 보다는 좋지 못함을 보여줍니다.
Text+visual embeddings (ViLD). 마침내 온전한 ViLD 방법론입니다. 저자들은 후술 할 하이퍼파라미터 실험에서 APr과 APc,APf가 트레이드오프 관계에 있음을 발견하였다고 합니다. 이는 ViLD-text와 ViLD-image 사이의 충돌이 있음을 보여준다고 하네요. 아무튼 ViLD의 결과를 보면, 16.1의 APr로 ViLD-text, ViLD-image보다 좋은 결과를 보이며, Supervised-RFS보다도 높은 성능입니다. 저자들이 목표로 한 novel category에 대한 object detection 성능을 어느 정도 잡은 모습입니다.
Model ensembling. 저자들은 몇 가지 앙상블을 시도해 보았습니다. 특히 ViLD-text와 ViLD-image를 별도로 앙상블 한 ViLD-ensemble은 ViLD보다도 좋은 성능을 보였으며, ViLD-text에 CLIP을 앙상블 하자 성능이 크게 증가했습니다. 다만, 이 방법은 예측 속도가 감소하기 때문에 실용성 측면에서의 의미는 없다고 합니다.
Stronger teacher model. 앞선 실험에서 사용한 CLIP ViT-B/32보다 강력한 CLIP ViT-L/14와 ALIGN을 teacher model로 사용한 결과입니다. 백본 성능이 좋아짐에 따라 성능도 크게 향상되었고, 특히 ALIGN을 사용한 모델의 경우 fully supervised인 2020 Challenge winner에 근접한 성능을 보였습니다. 주목할 점은 teacher model을 바꾼 것이기 때문에, student model을 이용하는 추론 속도에는 별 차이가 없다는 점입니다.
그나저나 표를 백본 모델이 아니라 supervision level로 묶거나 병기해 줬으면 좋았겠다는 생각이 드네요.
Performance Comparison on COCO Dataset
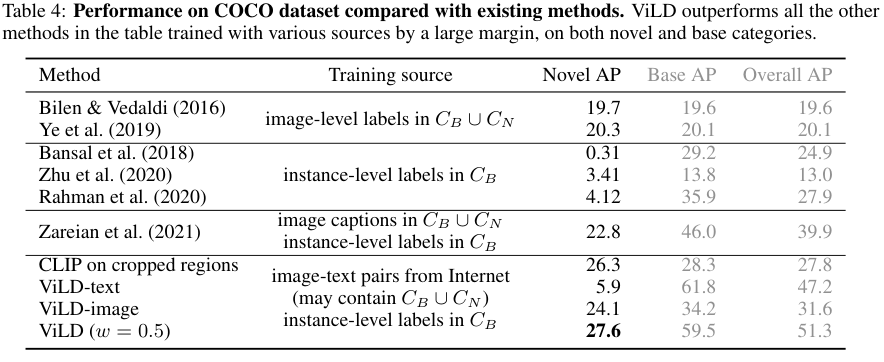
기존에 zero-shot detection이나 open-vocabulary detection의 관련 연구들이 대부분 COCO 데이터셋을 사용하여 성능 비교를 COCO에서 진행하였다고 합니다. 얼핏 봐도 기존 모델들에 비해 압도적인 성능을 보여주고 있음을 알 수 있습니다. ViLD-text의 novel category 성능이 유난히 낮은 이유는, base category가 48종으로 매우 적어 일반화에 어려움이 있었음을 지적하고 있습니다.
저자들은 기존 방법론들 대비 성능이 좋다고 하면서도, 상당히 많은 방법론적 변화가 있었기에 아주 정확한 비교는 아니라고 결과의 의미를 제한하고 있습니다.
Transfer to Other Datasets
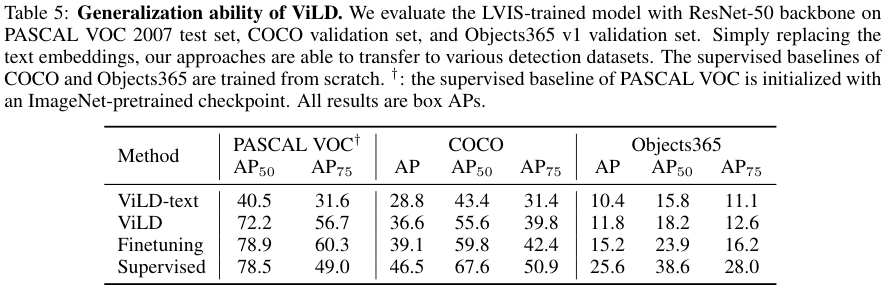
ViLD 모델은 VLP 모델들과 같이 예측하고자 하는 클래스의 텍스트가 있으면 예측이 가능하기 때문에, 다른 detection 데이터셋에 zero-shot transfer가 가능합니다. 저자들은 LVIS에서 학습된 ViLD 모델을 Pascal VOC, COCO, Object365 데이터셋으로 transfer 하는 실험을 진행했습니다. 그 결과 finetuning이나 supervised에 비해서는 약간 아쉬운 성능이기는 하나 꽤 좋은 zero-shot 성능을 볼 수 있었습니다.
Qualitative Results

정성적 결과입니다. 두 번째 행의 LVIS base+novel을 제외하고는 모두 학습 데이터에 포함되지 않은 클래스들인데 꽤나 잘 잡아내는 모습입니다.

On-the-fly interactive object detection. 저자들은 추출된 일부 region embedding과 몇 가지 텍스트와의 유사도 계산을 해보았는데, 놀랍게도 ViLD가 생성한 region embedding을 이용하니 객체에 대한 인식(강아지) 뿐만 아니라 구체적인 정보 (시바견과 허스키)에 따라 유사도가 달라짐을 확인할 수 있었다고 합니다. 즉, ViLD가 CLIP으로부터 분류를 위한 지식뿐 아니라, 풍부한 시각적 정보를 일부 학습한 것이죠. 저자들이 이는 아주 일부 경우에 불과하다고 제한하고는 있지만, 꽤나 놀라운 결과인 것 같습니다.
Systematic expansion of dataset vocabulary. 마지막으로, 저자들은 데이터셋 vocabulary v={v1,⋯,vp}에 대해 attributes a={a1,⋯,aq}를 사용한 systematic expansion을 제안합니다.
Pr(vi,aj|er)=Pr(vi|er)⋅Pr(aj|vi,er)=Pr(vi|er)⋅Pr(aj|er)
er은 region embedding을 의미합니다. 논문 다 읽고 갑자기 확률이 등장해서 이게 뭔가 싶고 막 어지럽고 그랬는데 천천히 해석해 보겠습니다.
저자들은 데이터셋의 vocabulary (즉 클래스)vi와 attribute aj가 region embedding er에 대하여 조건부 독립이라 가정합니다. 다시 말해, er이 주어졌을 때, 이 객체가 vi에 속할 확률이 해당 임베딩이 속성 aj를 가질 확률과 조건부 독립이라는 것입니다.
softmax 함수에 사용한 τ와 텍스트 인코더 T를 가져오겠습니다.
Pr(vi|er)=softmaxi(sim(er,T(v))/τ),Pr(aj|er)=softmaxj(sim(er,T(a))/τ)
위의 두 식은 각각 er이 vi에 속할 확률, aj를 가질 확률을 나타낸다고 볼 수 있는데요, 이러한 성질을 만족하는 q개의 attribute를 통해, 기존 p개의 vocabulary를 p×q개로 확장할 수 있다는 것입니다.
이 방법은 YOLO9000에서 제안한 probability 접근과 유사하다고 하는데요. 그럼 도대체 attribute라는 것이 뭔가... 싶었는데 아래 사진을 보니 바로 이해가 되었습니다.

"오렌지", "키위"와 같은 기존 클래스에 "주황색", "노란색", "녹색"과 같은 attribute를 추가해 주어 카테고리의 종류를 다양화해 주는 것입니다.

vocabulary expansion이라는 것에 대한 설명이 더 자세하게 되어있지는 않아 깊은 이해는 어렵지만, 막연하게 생각해 보면 더 다양한 텍스트 클래스를 부여할 수 있게 됨으로써 모델이 더 폭넓은 visual representation 능력을 가지게 되지 않을까 싶네요. 흥미롭습니다.
Conclusion
저자들은 open-vocabulary object detection을 위한 distillation 기반 방법론인 ViLD를 제안했습니다. 본 모델은 난도 높은 LVIS 데이터셋에서 OVOD를 수행한 첫 모델이며, novel category에서 16.1 AP를 달성하여 지도학습 기반의 방법론보다 높은 성능을 보여줬습니다. 동시에 distillation을 통해 추론 속도 역시 빠르게 가져갈 수 있었고, 아예 새로운 detection 데이터셋에 zero-shot transfer도 가능했습니다.
저자들이 논문 앞쪽에서 다룬 CLIP을 이용한 two-stage detection 까지는 어떻게 생각할 법한데, distillation을 적용하여 속도를 올리고 detector와 classifier를 ViLD-text와 ViLD-image라는 별도의 파이프라인으로 학습시킨 것이 인상 깊은 논문이었습니다.
감사합니다.
댓글을 사용할 수 없습니다.