QVHIGHLIGHTS: Detecting Moments and Highlights in Videos via Natural Language Queries (Moment-DETR) 리뷰 [NIPS 2021]
오늘 리뷰할 논문은 Moment Retrieval과 Highlight Detection을 위한 데이터셋인 QVHIGHRIGHTS와 Moment-DETR 방법론을 제안한 논문입니다. 데이터셋도 데이터셋이지만 Moment-DETR이 후속 연구에 많은 영향을 준 방법론이라, 한 논문에 큰 contribution이 두 가지나 존재하는 알찬 논문이라는 생각이 듭니다.
최근 사용자가 입력한 텍스트를 기반으로 연관된 동영상을 검색하는 text-to-video retrieval task에 대한 연구가 많은 진전을 이뤄내었지만, 쿼리 텍스트와 연관된 영상 전체를 검색하는 이러한 방식은 때때로 영상의 중요한 부분만 탐색하고자 하는 사용자에게는 부적합할 수 있습니다. 따라서 영상 내에서 highlight 혹은 쿼리와 관련된 짧은 순간(moment)을 특정하고자 하는 moment retrieval task가 필요하게 되었습니다.
기존에 moment retrieval을 위한 다양한 데이터셋들 (DiDeMo, Charades-STA, TVR, ActivityNet Captions, ASim)이 제안되었지만, 이러한 데이터셋들에는 대부분의 영상에서 찾고자 하는 moment가 영상 앞쪽에 등장하는 심각한 temporal bias 문제가 있었습니다. 또한, 영상 내부에 주어진 쿼리와 연관된 moment가 단 하나만 존재하였는데, 이는 실제 상황에서는 한 영상 내부에서 쿼리와 연관된 영역들이 여러 차례 분할되어 등장할 수 있는 것과도 차이가 있었습니다. 한편, highlight detection을 위한 데이터셋의 경우, 입력 쿼리 없이 query-agnostic 하게 highlight가 정의되어 있었고, 일부 query에 기반한 highlight가 존재하는 데이터셋들의 경우 적은 양의 프레임 혹은 클립만이 annotation 되어 있었습니다. 마지막으로, moment retrieval과 highlight detection 두 task가 상당히 유사함에도 불구하고, 두 task 모두에 대한 annotation을 제공하는 데이터셋이 부재하여 두 task가 독립적으로 연구되고 있었다고 합니다.

따라서 저자들은 query-based video moment retrieval과 highlight detection을 수행할 수 있는 벤치마크 데이터셋인 QVHIGHLIGHT 데이터셋을 제안합니다. 이 데이터셋은 다양한 주제(다양한 활동, 일상생활 vlog, 사회정치적 행동 뉴스 등)의 10,000개의 유튜브 영상과 두 task를 위한 고품질 annotation으로 구성되어 있습니다. Moment retrieval 시에는 쿼리에 대한 비디오 내부의 여러 disjoint moment들을 제공하여 현실적이고 less-biased 한 평가가 가능하며, 어노테이션과 함께 각 2초의 클립마다 5점 만점의 saliency/highlightness score를 부여하여 해당 영역의 중요도를 부여하였습니다.
또한, 저자들은 제안하는 데이터셋에서의 베이스라인으로 Object Detection 방법론인 DETR에서 영감을 받은 Moment-DETR 방법을 제안합니다. Moment-DETR은 end-to-end 트랜스포머 encoder-decoder 구조를 적용한 구조로 moment retrieval을 direct set prediction problem로 접근하여 proposal generation과 같은 전처리, non-max suppression과 같은 후처리 작업 없이 moment retrieval을 수행할 수 있다고 합니다. 추가로 saliency rankng objective를 인코더 출력부에 추가하는데, Moment-DETR에 어떠한 human-prior를 인코딩하지 않음에도 불구하고, highly-engineered한 기존 방법론들과 competitive 한 성능을 보여줄 수 있었습니다. 추가로 weakly-supervised pretraining과 ASR caption을 활용한 결과, Moment-DETR이 이러한 기존 방법론들의 성능을 크게 앞서는 결과를 보여주었습니다.
저자들의 contribution은 3가지 입니다.
- 만 개의 영상과 사람이 입력한 자연어 쿼리, relavant moemnt, saliency score로 구성된 QVHIGHLIGHTS 데이터셋 제작
- QVHIGHLIGHTS와 CharadesSTA에서 높은 성능을 보이는 Moment-DETR 모델 베이스라인 제안
- 디테일한 데이터셋 분석, 모델 비교 등의 실험 제공
Related Work
Datasets and Tasks. Moment Retrieval은 동영상 속에서 주어진 자연어 쿼리에 해당하는 영역(moment)의 위치를 찾는 task입니다. 기존의 데이터셋들은 대체로 찾아야 할 영역이 영상의 시작이나 끝 부분에 분포하는 temporal bias문제가 심각한 문제가 있었으나, 저자들이 제안하는 QVHIGHLIGHTS 데이터셋은 영상의 전 구간에 탐색 영역이 분포한다고 합니다. 또한 기존 데이터셋들에는 영상 하나에 탐색 영역이 단 하나 존재했던 반면, 제안하는 데이터셋에서는 하나의 영상 내부에 탐색 영역이 하나 이상 존재합니다.
Highlight Detection은 일반적으로 주어진 영상에서 하이라이트 영역을 찾는 task인데요, 일반적으로 쿼리가 주어지지 않는 상황을 가정하며, 쿼리가 주어지는 데이터셋도 두 가지 존재하였으나, annotation의 양이 적어 모델이 학습하고 성능을 평가하는데 한계가 있었다고 합니다. 한편, 제안하는 데이터셋에는 5점 만점으로 평가된 saliency/highlightness score annotation이 제공됩니다.
Moment retrieval과 highlight detection은 유사한 부분이 많음에도 불구하고, 평가를 위한 공통된 벤치마크가 없어 각기 다른 데이터셋을 이용해 평가를 진행하고 있었으나 QVHIGHLIGHTS에서 통합된 벤치마크를 제공하여 이제 함께 평가할 수 있다고 합니다.
Methods. 기존 highlight detection 방법들은 일반적으로 hinge loss, CE loss 혹은 강화학습 방법을 통해 영상의 하이라이트로 추정되는 프레임 혹은 클립에 높은 점수를 부여하는 ranking-based 방법을 사용하였습니다. Moment Retrieval에서는 moment proposal을 생성하고 점수를 부여하고자 하는 방식과, moment의 시작과 끝 지점을 예측하고자 하는 방법, moment coordinates를 회귀로 예측하고자 하는 방법들이 제안되었습니다. 그러나 이러한 방법들은 모두 proposal generation과 같은 전처리나 NMS와 같은 후처리를 요구하였기 때문에, end-to-end training이 불가했다고 합니다. 저자들은 object detection과 video action detection에서 사용되는 DETR에서 영감을 얻어 Moment-DETR을 제안합니다. 이 방법은 비디오와 유저 쿼리를 입력으로 moment coordinates와 saliency scores를 end-to-end로 곧바로 출력합니다. 따라서 handcrafted 한 전처리나 후처리 과정이 불필요하다고 합니다.
Dataset Collection and Analysis
QVHIGHLIGHTS 데이터셋은 1만 개 이상의 비디오와 사람이 작성한 자유형식 쿼리 어노테이션으로 구성되어 있습니다. 각 쿼리는 대응되는 영상 속 하나 혹은 여러 개의 다양한 길이를 갖는 moment들과 연관되어 있습니다. 추가로 각 moment에는 2초의 clip 단위로 5점 만점의 Likert-scale saliency annotation이 부여되어 있습니다.
Data Collection
Collecting videos. 저자들은 편집이 적게 들어가 있으며 다양한 주제의 영상을 수집하고자 하였습니다. 먼저, 유튜브에서 lifestyle vlog 영상들을 수집하였는데, 이러한 영상들이 세계 각지의 사람들의 다양한 행동과 모습, 위치를 담고 있으며 스마트폰부터 고프로까지 다양한 기기에서 다양한 자세로 촬영되어 자연스럽게 컴퓨터비전에서 요구되는 다양성을 얻을 수 있다고 합니다. 이어서 영상의 다양성을 더욱 높이기 위해, "raw footage" 위주의 뉴스 영상을 추가하였다고 합니다. 이러한 데이터들을 확보하기 위해 "daily vlog", "travel vlog", "news hurricane" 등의 주제로 영상을 검색하여, 5-30분 길이의 영상들을 다운로드했습니다. 이때, 좋은 품질의 영상을 확보하기 위해 2016년 이후에 업로드된 영상 중, 조회수가 100회 이상인 영상을 취했으며, 싫어요 비율이 너무 높은 영상은 제외했습니다. 이렇게 얻어진 영상들을 150초의 짧은 영상으로 나누어 annotation을 수행하였습니다.
Collecting user queries and relevant moments. 자연어 쿼리와 영상 속 moment를 수집하기 위해, Amazon Mechanical Turk에 annotation task를 생성했다고 합니다. (AI 라벨링 등 크라우드 소싱을 아웃소싱하는 플랫폼이라고 합니다.) 저자들은 영상을 보고 영상 속 interesting activities에 대한 내용을 표준 영어로 작성해 달라고 요청하였습니다. 그다음, 영상을 2초 단위의 클립으로 분할하여 해당 쿼리와 연관된 영역을 분류하도록 하였습니다. Moment annotation 품질을 검증하기 위해, 저자들은 600개의 쿼리-영상 쌍에 대하여 3개의 moment annotation을 수집하고, 그들의 IOU를 확인하여 annotation이 잘 되었는지 확인했습니다. 그 결과, 90% 정도의 쿼리가 평균 0.9 이상의 IOU score를 보여 이러한 방법으로 수집된 label의 품질이 준수함을 알 수 있었습니다.
Annotating saliency scores. 앞선 annotation이 영상 내의 어떤 moment가 어떤 쿼리와 대응되는지를 알려주지만, 해당 영역 안에서도 특히 쿼리와 관련이 있는 중요한 영역이 있을 수 있습니다. 따라서 각 clip이 얼마나 중요한 영역인지, 영상의 highlight를 잘 나타내는지 나타내는 saliency score를 annotation에 추가했습니다. 이번에도 같은 annotation을 3 명의 작업자가 수행하도록 한 후, 평균을 내어 점수를 얻었습니다.
Quailty Control. 데이터의 품질을 보증하기 위해, 저자들은 500회 이상 조회되었으며 승인율이 95% 이상인 작업자들만을 고용하여 annotation을 수행했다고 합니다. 이어서 작업자들의 업무 검증을 위한 test를 진행하였고 543명 중 48%만이 통과하여 task에 참여했습니다. 그 결과 작업자들의 annotation 일치율이 높아 작업 품질이 좋았음을 알 수 있었고, 저자들은 쿼리 annotation과 saliency annotation당 0.25, 0.18 달러를 지급했다고 합니다. 작업자들의 평균 시급은 11달러였으며, 3개월에 거친 작업 끝에 대략 16000달러의 비용이 발생했다고 합니다. 데이터셋 하나 라벨링 비용에 2,200만 원 정도 쓴 거네요. 데이터셋 논문은 처음 읽어보는 것 같은데, 이렇게 작업자들의 인건비까지 공유하는 것이 참 신기합니다.
Data Analysis
최종적으로 10,310개의 쿼리와 18,367개의 moment, daily vlog, travel vlog, news events 세 가지 부류의 영상 10,148개가 수집되었습니다. 표 1을 보면 각 부류의 영상에서 자주 등장한 동사와 명사를 확인할 수 있습니다.
이어서 표 2를 보면, 기존 데이터셋들과 QVHIGHLIGHTS의 비교를 볼 수 있는데, 기존 데이터셋들이 영상 하나당 한 개의 moment를 가진 반면, QVHIGHLIGHTS는 영상 하나 당 평균 1.8개의 disjoint moment를 가지고 있습니다. 이는 영상 내부에 서로 관련이 없는 장면 등이 등장할 수 있는 실제 상황에 더 적합하다고 할 수 있습니다. 한편, 위 표에서 대부분의 highlight detection 데이터셋들이 쿼리 없이 예측을 수행하도록 되어있으며, 쿼리가 존재하는 ClickThrough, ActivityThumbnails 데이터셋의 경우 전자는 20 keyframe만 annotation이 되어 있으며, 후자는 highlights를 5개 clip 미만으로 제한하여 한계가 있다고 합니다. 반면 QVHIGHLIGHTS 데이터셋은 2단계 annotation으로 구성되어 모델 학습과 평가에 더욱 적절하게 구성되어 있다고 합니다.
위 그림에서는 데이터셋에 존재하는 moment가 다양한 길이, 다양한 위치에 분포되어 있음을 확인할 수 있습니다. 이로써 저자들이 주장한 대로 temporal bias도 적다는 것이 드러났네요.
Methods: Moment-DETR
Moment-DETR의 목표는 자연어 쿼리를 이용하여 대응되는 moment의 위치를 찾고 비디오의 highlight를 탐지하는 것입니다. 다시 말해, 자연어 처리 q가 Lq개의 토큰 형식으로 주어지고 동영상 v가 Lv개의 클립 embedding의 시퀀스로 주어질 때, 한 개 이상의 moment {mi}를 찾고(moment는 v 내부의 연속된 클립들로 정의됩니다), 각 쿼리에 대해 clip-wise saliency score S∈RLv를 예측하는 것이 목표입니다. 이때 가장 높은 saliency score를 가진 클립이 highlight가 됩니다.
저자들은 최근 Object Detection에서 좋은 성과를 보인 트랜스포머 기반 방법론인 DETR을 적용한 end-to-end moment retrieval, highlight detection 방법인 Moment-DETR을 제안합니다. Moment-DETR에는 기존 모델들에서 사용되던 hand-crafted components, 이를테면 proposal generation module이나 non-maximum suppression이 필요하지 않습니다.
본 논문만 읽어서는 잘 이해가 되지 않아서, 별도로 DETR은 공부하고 나니 방법론이 이해가 되었는데 object detection에 사용되는 DETR을 비디오에서의 temporal grounding에 거의 그대로 가져왔다고 보시면 될 것 같습니다. DETR의 핵심적인 콘셉트를 소개해드리자면, detection 문제를 direct set prediction problem으로 바라보게 되는데, detection task의 입력과 출력을 각각 집합으로 바라보게 됩니다. 집합은 중복이 허용되지 않으며, 순서가 존재하지 않는 성질을 갖는데 이는 곧 출력 집합인 detection 결과에 중복이 없으므로 NMS를 적용할 필요가 없다는 의미입니다. 따라서 DETR은 어떠한 human prior 없이 트랜스포머를 통해 곧바로 쿼리에 알맞은 detection 결과를 얻을 수 있습니다.
Architecture
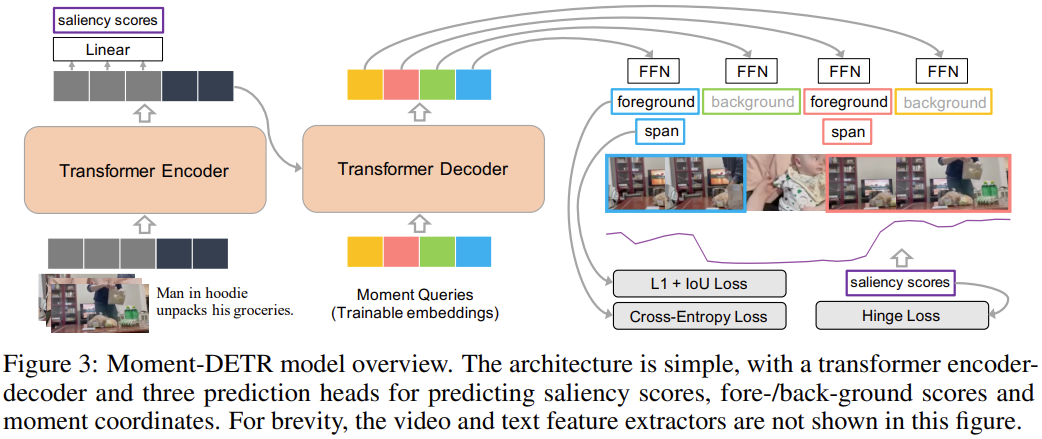
Input representations. 먼저, 영상에서 SlowFast와 CLIP의 visual encoder (ViT-B/32)로 2초 단위로 feature를 추출합니다. 그다음, 두 feature를 normalize 하고 concatenate 하여 Moment-DETR의 input feature Ev∈RLv×2816로 사용하게 됩니다. 쿼리 텍스트의 경우 CLIP text encoder로 token level feature Eq∈RLq×512를 생성해 사용합니다. 이어서 2-layer perceptron과 layer normalization, dropout으로 구성된 신경망으로 영상과 쿼리 feature를 d차원의 공통 임베딩 공간으로 투영하고, 두 feature를 concatenate하여 마침내 Moment-DETR의 입력 feature Einput∈RL×d 로 사용하게 됩니다. L=Lv+Lq
Transformer encoder-decoder. 입력 시퀀스는 T개의 트랜스포머 인코더를 통해 인코딩 됩니다. 인코더는 multi-head self-attention과 feed forward network, fixed positional embedding으로 구성된 기본 트랜스포머 구조를 따랐습니다. 인코더의 출력은 Eenc∈RL×d의 형태가 됩니다. 디코더 역시 기본 트랜스포머 구조를 따라가며, T개 사용됩니다. 각 디코더는 multi-head self-attention, cross-attention, FFN으로 구성되며 각 디코더 계층의 입력에는 N개의 d차원 학습 가능한 positional embedding인 moment queries가 더해집니다. 디코더의 출력은 Edec∈RN×d입니다.
Prediction heads. 인코더 출력 Eenc를 linear layer에 입력하여 saliency score S∈RLv를 얻고, 디코더의 출력 Edec를 3-layer FFN with ReLU에 입력하여 입력 영상에 대한 normalized moment center coordinate를 얻습니다. 또한 DETR과 같은 방식으로 linear layer with softmax를 이용해 class label을 예측하는데, object retrieval task가 아닌 temporal grounding task이므로 라벨은 foreground와 background가 됩니다.
saliency score는 인코더의 출력, moment의 위치는 디코더의 출력으로 얻은 것이 흥미로운데, 왜 이러한 방법을 사용하였는지에 대한 설명은 따로 없어 아쉽습니다.
Matching and Loss Functions
Set prediction via bipartite matching. Moment queries에 대한 N개의 예측을 ˆy={ˆyi}Ni=1로 나타내고, foreground와 background를 나타내는 라벨을 y={yi}Ni=1과 같이 나타냅니다. 이때 moment queries의 수 N이 ground truth moments, 즉 foreground의 수보다 많기 때문에, prediction과 ground truth가 일대일 매칭되지 않습니다. 따라서 loss 값을 계산하기 위해, 먼저 각 예측에 대응되는 GT moment를 배정해 줄 필요가 있습니다. Matching cost Cmatch를 아래와 같이 정의합니다. 이때 ˆp는 클래스 예측, 즉 클립이 foreground인지 background인지를 나타냅니다.
Cmatch(yi,ˆysigma(i))=−1{ci≠∅}ˆpσ(i)(ci)+1{ci≠∅}Lmoment(mi,ˆmσ(i))
Ground truth y는 foreground와 background ∅를 나타내는 클래스 라벨 ci와 정규화된 moment의 center 좌표와 moment의 너비를 나타내는 벡터 mi∈[0,1]2로 yi=(ci,mi)와 같이 나타납니다. ˆyσ(i)은 permutation σ∈GN에서의 예측 중 i번째 요소를 의미합니다. 이때, GT에서 background에 해당하는 영역은 matching cost 계산에 사용되지 않습니다.
위의 matching cost를 활용하여 헝가리안 알고리즘을 수행하여, GT와 prediction 사이의 optimal bipartite matching ˆσ=argminσ∈GN∑NiCmatch(yi,ˆyσ(i))를 찾고자 합니다. 헝가리안 알고리즘은 어떤 두 집합과 매칭의 비용이 주어질 때, 비용의 합을 최소화하는 일대일 매칭을 찾는 알고리즘입니다. 이렇게 구해진 최적의 assignment ˆσ를 활용해 손실값을 계산합니다.
Moment localization loss Lmoment는 L1 loss와 generalized IoU loss를 통해 예측과 실제 moment의 차이를 측정합니다.
Lmoment(mi,ˆmˆσ(i))=λL1||mi−ˆmˆσ(i)||+λiouLiou(mi,ˆmˆσ(i))
λL1,λiou∈R는 두 손실함수의 비율을 조절하는 하이퍼파라미터이고, Liou는 1D temporal IoU$를 계산합니다.
Saliency loss Lsaliency는 positive clip과 negative clip의 쌍 두 개 사이의 hinge loss로 계산됩니다. GT moments 내부의 높은 score의 clip thigh와 낮은 score의 clip tlow로 구성된 첫 번째 쌍과 GT 내부의 clip tin, GT 외부의 clip tout로 구성된 두 번째 쌍을 이용해 loss를 계산하며 Δ는 마진을 의미합니다.
Lsaliency(S)=max(0,Δ+S(tlow)−S(thigh))+max(0,Δ+S(tout)−S(tin))
Overall loss. 최종 loss는 앞선 손실함수들의 선형 결합으로 정의됩니다.
L=λsaliencyLsaliency(S)+N∑i=1[−λclslogˆpˆσ(i)(ci)+1ci≠∅Lmoment(mi,ˆmˆσ(i))]
저자들은 DETR에서의 방식에 따라, background class ∅의 log-probability를 10배 down-weight 하여 class imbalance를 조정하였으며, classification and moment loss를 모든 디코더 계층에 적용했다고 합니다.
Weakly-Supervised Pretraining via ASR
Moment-DETR은 end-to-end 트랜스포머 인코더-디코더 구조로 hand-crafted component와 같은 human prior를 필요로 하지 않습니다. 이런 모델들은 대체로 그만큼 대규모의 데이터셋에서 학습해야만 제대로 된 성능을 볼 수 있는데, 이를 위한 라벨 취득은 비용이 드는 일입니다. 따라서 저자들은 자동 음성 인식 (ASR) 기반으로 영상에서 캡션을 생성하여, weakly-supervised pretraining에 활용하였습니다. 저자들은 유튜브 영상에서 ASR 자막을 다운로드하여 쿼리로 사용하여 모델이 캡션에 해당하는 시간을 찾게 하였습니다. 따라서 사전학습은 앞선 손실함수와 동일한 함수로 진행할 수 있었으나, saliency label이 없기 때문에 saliency loss는 제외하고 사용하였습니다.
Experiments and Results
Data and evaluation metrics. 저자들은 제안한 QVHIGHLIGHTS 데이터셋의 70%를 학습, 15%를 검증, 15%를 테스트 데이터로 분할하였습니다. Moment retrieval with multiple moments는 IoU 임계값 0.5와 0.75, 그리고 [0.5: 0.05: 0.95]에서의 평균 mean Average Precision (mAP)를 사용하여 평가하였습니다. 또한, 여러 개의 GT moments 중에 하나 이상에서 0.7 이상의 높은 IoU로 예측을 수행하였는가를 평가하는 Recall@1 (R@1)도 평가하였습니다. Hightlight Detection은 mAP를 평가 지표로 사용하였고, ClickThrough 데이터셋과 같이 HIT@1 지표도 가장 점수가 높은 clip에 대하여 사용하였습니다. ClickThrough와 같이, 저자들은 "Very Good" 점수를 받은 clip을 positive highlight로 정의하였습니다. 이때, saliency label은 3명의 작업자들이 평가한 점수가 존재하기 때문에, 각 작업자 별로 평가하고 평균을 계산하여 최종 지표를 얻었습니다.
Implementation details. 모델은 파이토치로 구현했고, hidden size d=256, 인코더와 디코더의 계층 수 T=2, moment query의 수 N=10을 사용했습니다. dropout은 트랜스포머 계층에 대해서는 0.1, input projection layer에 대해서는 0.5를 적용하였고, loss hyperparameters는 λL1=10,λiou=1,λcls=4,λs=1,Δ=0.2를 적용했습니다. 가중치는 Xavier init.으로 초기화했고 AdamW optimizer에 초기 learning rate 1e−4, weight decay 1e−4를 사용했습니다. 모델은 batch size 32로 200 에포크 학습했으며, 사전학습 시에도 같은 설정을 사용하되, batch size 256에서 100 에포크 학습했습니다. 사전학습, 학습/파인튜닝 모두 하나의 RTX 2080ti에서 수행되었으며 학습/파인튜닝은 12시간, 사전학습은 2일 소요되었습니다.
Results and Analysis

Comparison with baselines. Moment-DETR과 다른 moment retrieval, highlight detection 방법론들을 QVHIGHLIGHTS test split에서 검증한 결과입니다. 위 표에서 MCN과 CAL은 proposal-based 방식, XML은 span prediction 방식의 moment retrieval 방법입니다. 한편 BeautyThumb는 frame quality를 활용하는 방식, DVSE는 clip-query similarity를 활용하는 방식의 Highlight Detection 방법이라고 합니다. XML은 moment retrieval 방법론이기는 하지만, 쿼리에 대한 clip-wise similarity를 출력할 수 있어, 저자들은 이 모델로 highlight detection을 수행한 뒤 그 결과도 보고하였습니다. 또한, original XML은 Moment-DETR보다 작은 크기를 가지므로 공정한 비교를 위해 모델의 크기를 증가시킨 XML도 비교에 사용하였습니다. 이때, QVHIGHLIGHTS의 saliency annotation을 활용하기 위한 auxiliary saliency loss도 추가하여 XML+를 만들어 비교하였습니다. clip-wise similarity scores는 clip의 중앙 프레임을 뽑아 image-query score를 계산하여 사용하였고, highlight detection에서는 이 점수를 바로 예측에 활용하였습니다. Moment retrieval에는 TAG와 같은 방식으로 top-scored clip들을 watershed 알고리즘을 통해 progressively grouping 하여 결과를 생성하였습니다.
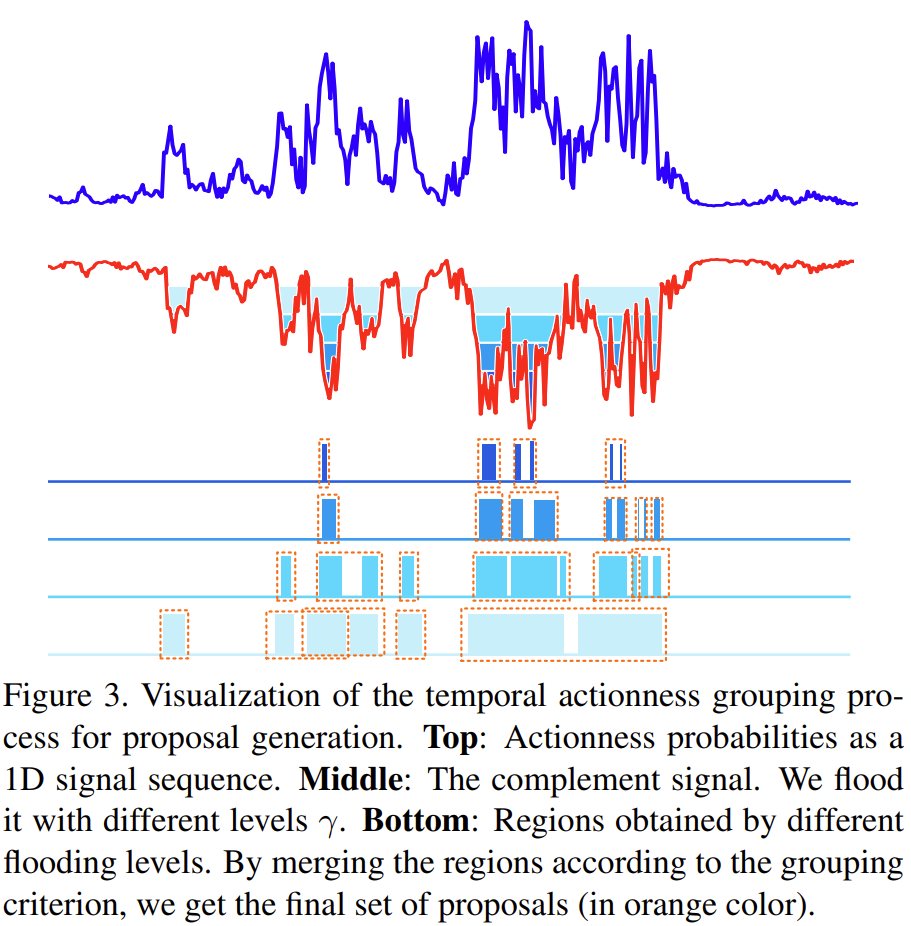
watershed 알고리즘은 이미지 분할에 사용되는 알고리즘으로, 어떤 픽셀의 강도를 높이로 생각하였을 때, 이미지에 물을 붓는다고 생각하면 강도가 높은(높이가 높은) 영역으로 나누어진 공간들은 물이 섞이지 않기 때문에, 그 부분들을 외곽선으로 하여 영역들을 구분하는 알고리즘입니다. 아래 그림을 보면 직관적으로 이해가 되실 것입니다.

베이스라인 모델 중 가장 좋은 모델인 XML+와 비교했을 때, Moment-DETR은 moment retrieval에서 비슷한 성능을 보였고, 특히 IoU 임계값이 낮을 때 좋은 결과, 높을 때 나쁜 결과를 보였습니다. 이는 모델이 실제 moment와 가까운 영역을 찾기는 하지만, 구간을 아주 정확하게 만들지는 못하고 있음을 나타냅니다. (detection으로 따지면 물체를 잘 찾기는 하는데, bounding box의 크기가 형편없다고 보시면 될 것 같습니다.) 저자들은 이것이 L1과 generalized IoU loss에 의해 mismatch에 큰 penalty가 부여되기 때문인 것 같다고 합니다. 이는 DETR에서도 유사하게 발생하는 문제라고 하네요. 한편 highlight detection에서 역시 Moment-DETR과 XML+이 비슷한 성능을 보여주는데, 이는 어쩌면 Moment-DETR이 human prior 없이 학습되고 예측하기 때문에, 제대로 된 성능을 발휘하려면 더 많은 학습 데이터가 요구되는 것일 수도 있다고 합니다. 따라서 저자들은 ASR caption 기반의 사전학습을 진행하였고, 그 결과 두 task 모두에서 Moment-DETR이 baseline을 크게 앞서는 성능을 보여주었습니다. 한편 저자들은 CLIP이 highlight detection의 HIT@1에서 가장 높은 성능을 보임을 발견하였는데, 여기에 대해 놀랍다는 것 외에는 별다른 분석을 보이지 않고 있습니다.
HIT가 어떤 지표인지 알았다면 제 나름의 고찰을 해볼 텐데, 기회가 되면 한번 찾아봐야겠습니다. CLIP은 보면 볼수록 특이한 점이 많네요.
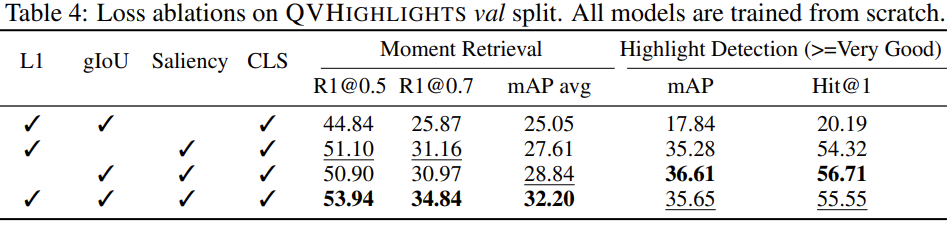
Loss ablations. 이어서 저자들은 제안한 loss들에 대한 ablation study를 진행했습니다. 먼저 saliency loss를 제거할 때 두 task 모두에서 큰 성능 하락이 발생하였는데, highlight detection이야 saliency score에 의존적인 task이니 그렇다 치지만 moment retrieval에서도 성능이 크게 떨어지는 것으로 보아, saliency score를 학습하는 것이 moment retrieval에도 도움이 되었음을 알 수 있었습니다. 저자들은 moment span prediction loss (L1)와 classification loss가 텍스트 쿼리와 clip 간의 유사도를 학습하는데 직접적인 signal을 주지 않는 반면, saliency loss가 이런 역할을 중요하게 수행한 것 같다고 합니다.
L1과 CLS loss를 제거할 경우 moment retrieval 성능은 하락하였지만, highlight detection 성능은 크게 변화하지 않아 이러한 loss들이 moment retrieval에 중요함을 알 수 있습니다.

Moment query analysis. 위 그림은 QVHIGHLIGHTS에 속한 1550개의 validation 영상에 대하여 Moment-DETR의 10개 moment query slot의 moment span prediction을 시각화한 것입니다. 각 상자는 10개의 slot을 나타내고, 각 상자의 x 축은 moment center의 위치, y 축은 moment의 너비를 의미합니다. 시각화를 보면 각 slot이 주로 생성하는 예측의 위치와 너비가 다름을 알 수 있습니다. 첫 번째와 두 번째 slot은 주로 짧은 moment를 찾은 반면, 세 번째 slot은 긴 moment들을 많이 찾았습니다. 대부분의 slot이 짧은 moment를 찾도록 학습된 셈인데, 이는 데이터셋에 long moment가 많지 않기 때문으로 보인다고 합니다.
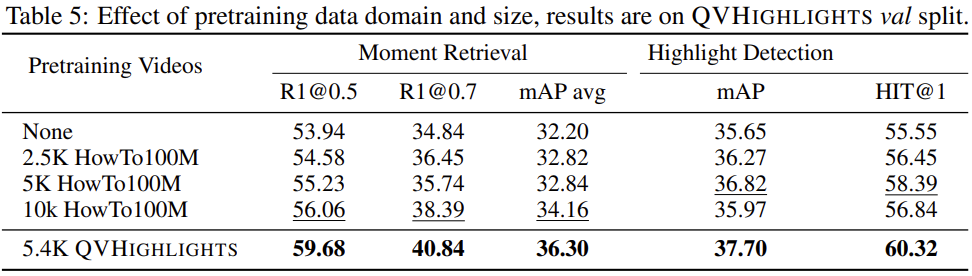
Pretraining data domain and size. 사전학습의 역할을 정확히 파악하기 위해, 저자들은 사전학습에 사용되는 데이터셋과 그 크기를 바꿔보았습니다. HowTo100M 데이터셋을 이용해 사전학습을 진행한 결과 여전히 성능이 향상되었는데, 사전학습에 사용되는 영상의 크기가 증가할수록 moment retrieval 성능도 향상되었습니다. 한편, highlight detection의 경우 데이터의 증가가 성능의 향상으로 직결되지는 않았는데, 이는 사전학습 task가 highlight detection과 직결되지 않기 때문인 것 같습니다. (앞서 언급했듯이, 사전학습에는 saliency loss가 사용되지 않으며 이는 특히 highlight detection과 연관된 loss입니다.) 또한, HowTo100M과 QVHIGHLIGHTS의 도메인 차이로, HowTo100M에서 만개의 데이터를 사용해도 5천4백 개의 QVHIGHLIGHTS 데이터를 사용한 것보다 결과가 좋지 않았습니다.

Generalization to other datasets. Moment-DETR 모델을 기존 moment retrieval 데이터셋인 CharadesSTA에서 평가한 결과입니다. 앞선 QVHIGHLIGHTS에서의 실험과 유사하게, 제안한 모델이 특히 R1@0.5에서 좋은 성능을 보여주었습니다. 한편, CharadesSTA에서 평가한 경우 HowTo100M의 1만 개 영상에서 사전학습한 모델이 결과가 좋았다고 합니다.
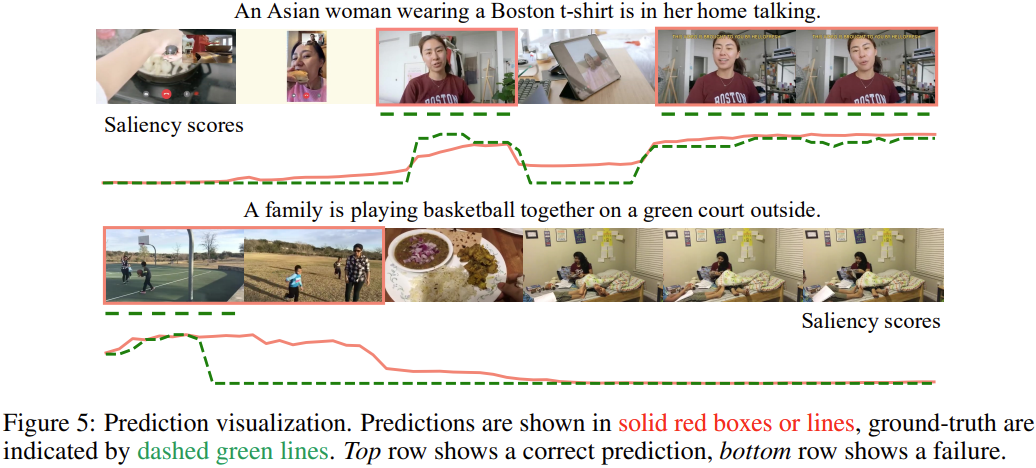
Prediction visualization. 정성적 결과입니다. 초록색 선이 GT이고, 붉은 선이 예측인데, 위쪽 결과는 예측을 잘한 모습이지만 아래의 경우, 가족들이 바깥에서 놀고는 있으나 농구를 하고 있지는 않은데, score를 높게 준 오답 예시입니다. 정성적 결과에 오답을 제시한 논문은 오랜만에 보는 것 같네요. 근데 또 이해가 가는 오답이라서, 오히려 논문에 대한 평가가 안 좋아지지는 않는 것 같습니다.
Conclusion
저자들은 자연어 쿼리를 이용한 moment retrieval과 highlight detection에 모두 적용 가능한 QVHIGHLIGHTS 데이터셋과 Moment-DETR 방법을 제안했습니다. 제안한 데이터셋과 설명도 탄탄하고, 모델도 DETR을 거의 그대로 가져오기는 했지만, 사전학습을 진행하고 다양한 비교 실험을 수행하여 굉장히 완성도 있는 논문이었던 것 같습니다.
좋은 논문이었네요.
감사합니다.
댓글을 사용할 수 없습니다.