SSD: Single Shot MultiBox Detector 논문 정리
Abstract
SSD는 2016년에 발표된 Single Stage Object Detection 모델이다.
SSD는 Bounding Box의 출력 공간을 feature map 상의 각기 다른 비율과 크기를 갖는 default box들로 나누는데(discretize), 예측을 수행할 때, 각 default box들의 내부에 각 클래스에 해당하는 객체가 존재하는지를 나타내는 점수를 생성하고, 객체의 모양을 더 잘 표현하도록 조정된 default box(즉, 예측 Bounding Box)를 생성한다. 더불어, SSD는 각기 다른 해상도의 feature map들의 예측값들을 조합하여 더 자연스럽게 다양한 크기의 객체를 검출한다.
SSD는 proposal generation, subsequent pixel or feature resampling stage와 같은 과정들을 하나의 네트워크에서 수행하기에, 학습시키기 쉽고 문제에 적용하기 간단하다. PASCAL VOC, COCO 등의 데이터셋에서의 실험 결과는 SSD가 region proposal을 별도로 수행하는 2-stage 모델들과 견줄만한 정확도를 내면서도, 학습과 예측 면에서 훨씬 빠름을 보여준다.
SSD는 $300 \times 300$ 크기의 VOC2007 입력에서 74.3% mAP를 달성하였고, Nvidia Titan X GPU에서 59FPS의 속도를 내었다. $512 \times 512$ 크기의 입력에서는 76.9% mAP를 달성하여 이전 SOTA였던 Faster R-CNN 모델을 앞선 성능을 달성하였다.
이전 Single Stage Model들에 비해 SSD는 더 작은 입력에서도 훨씬 좋은 정확도를 보였다.
Introduction
Selective Search 방법 기반의 많은 Object Detection 시도들이 있었지만, 대부분 컴퓨팅 자원이 너무 많이 요구되었고 속도가 매우 느려 일반적으로 SPF(second per frame)으로 측정해야 할 정도였다. 그나마 최근에 나온 고성능 모델 Faster R-CNN조차 7 FPS(frame per second)의 속도이니 실시간 객체 인식이나 저사양 기기에의 적용은 매우 어려운 일이었으며, 대부분 모델의 속도 개선 방법은 그만큼 정확도를 희생하는 방식이었다.
이 논문에서 소개하는 방식은 픽셀이나 feature를 resampling하여 Bounding Box hypotheses를 만들지 않으면서도, 그러한 모델들과 동등한 성능을 내는 최초의 심층신경망 기반 객체 인식 모델이다. 이 모델은 기존 고성능 모델들 이상의 정확도를 내면서도 속도 면에서 매우 큰 개선을 보였다. (59 FPS with mAP 74.3% on VOC2007 test, vs Faster R-CNN 7 FPS with mAP 73.2% or YOLO 45 FPS with mAP 63.4%)
속도를 개선한 근본적인 향상점은 bounding box proposal과 이에 이어지는 pixel or feature resampling 과정을 삭제한 것에 있다. 기존에 이런 시도를 한 모델(OverFeat, YOLO)가 있었으나, 우리는 여기에 몇 가지 개선을 더함으로써 기존 시도들에 비해 정확도를 획기적으로 향상시킬 수 있었다.
SSD의 개선점 중 하나는 각기 다른 비율의 객체 검출을 위해 분리된 예측기(predictor) 필터를 사용하여, 객체의 클래스와 bounding box 위치를 예측하기 위해 작은 합성곱 필터를 사용한 것이다. 나아가, 이 필터들을 신경망 뒷부분의 여러 feature map들에 적용하여 다양한 스케일의 객체 인식을 수행하였다.
이러한 수정들-특히 다양한 스케일의 에측을 위해 다양한 레이어를 사용한 것- 덕분에 우리는 상대적으로 적은 해상도에서 높은 속도와 정확도를 얻을 수 있었다.
이 논문의 기여를 정리하면 아래와 같다.
- 기존 SOTA 모델(YOLO)보다 더 정확하면서도 훨씬 빠른 SSD 모델 소개.
- SSD의 핵심은 feature map에 작은 합성곱 필터들을 사용하여, 고정된 default bounding box들의 집합 안에서 category score와 bounding box를 예측하는 것에 있다.
- 높은 인식 정확도를 위해, 각기 다른 스케일의 feature map들로부터 각기 다른 스케일의 예측을 생성하고, aspect ratio에 따라 예측들을 분명히 분리하였다.
- 이런 디자인들 덕분에 모델은 end-to-end 학습이 가능하며, 저해상도 이미지에서도 높은 정확도를 내며 정확도 vs 속도 trade off를 향상시켰다.
- 이 모델의 성능과 속도에 대한 다양한 실험들이 다른 SOTA 모델들과 비교하여 시행되었다.
The Single Shot Detector

SSD framework.
SSD의 학습에는 입력 이미지와 각 객체에 대한 ground truth 박스들만 있으면 된다.
SSD의 학습에서, 우리는 각기 다른 스케일(예를 들어, $8\times 8, 4\times 4$. 위 이미지의 (b)나 (c))을 갖는 feature map들 상의 적은 수(예를들어, 4)의 각기 다른 비율을 갖는 default box들을 평가한다. 각 default box에 대해 우리는 각 클래스에 대한 confident score와 bounding box를 예측한다. 학습 단계에서, 먼저 ground truth box와 default box들을 매치하는데, 예를들어 위 이미지에서는 두 개의 default box가 고양이와, 한 개의 box가 강아지와 매치되었고 나머지는 미검출 되었다. 모델의 loss는 localization loss(Smooth L1 등)와 confidence loss(Softmax 등)의 가중합으로 계산된다.
Model
SSD는 고정된 크기의 bounding box들과 박스 내부에 객체가 존재하는지 여부를 나타내는 score들을 생성하는 정방향 합성곱 신경망에 non-max suppression 과정을 거쳐 최종 인식 결과를 만든다.
신경망의 초반부는 논문에서 base network라고 불리는 객체 분류에 사용되는 일반적인 구조로 되어있다. (논문에서는 vgg16의 classifier 앞부분을 사용) 이어서 신경망이 객체 인식을 수행할 수 있도록 하는 구조가 이어지는데, 이는 아래를 포함한다.

1. Multi-scale feature maps for detection
base network에 이어 합성곱 feature layer들을 추가한다. 이 레이어들은 점진적으로 크기가 줄어들어 다양한 스케일의 예측을 수행할 수 있게 해 준다. 각 feature layer에 따라 예측을 수행하는 합성곱 모델이 다르다. (OverFeat와 YOLO가 단일 스케일 feature map에서 작동하는 것을 참조하라)
2. Convolutional predictors for detection
새로 추가된 feature layer(혹은 선택적으로, base network에 이미 존재하던 몇 계층들)들은 합성곱 필터들을 이용해 고정된 인식 예측들을 생성한다. $m\times n$ 크기에 $p$ 채널을 갖는 feature layer에 대해, $3\times 3\times p$ 크기의 작은 커널은 특정 클래스의 존재확률이나 default box에 상대적인 형태 정보를 예측한다. 커널이 적용된 $m\times n$ 개의 위치들은 각각의 출력 값을 생성한다. Bounding Box의 정보는 default box에 대해 상대적인 값으로 생성된다. (YOLO에서는 이 과정을 합성곱 필터가 아닌 fully connected 레이어로 수행한다.)
3. Default boxes and aspect ratios
SSD는 각 feature map의 각 cell들에 대하여 default bounding box들을 정의한다. default box에 대응하는 feature map cell은 고정되어 있다. 각 feature map cell에 default box에 상대적인 bounding box offset과 이 box에 객체가 존재하는지 나타내는 score를 예측하는 것이다.
모델은 주어진 위치에 대응하는 $k$개의 box에 대해 $c$개의 class score들과 원래 default box 크기에 상대적인 4개의 bounding box offset들을 계산한다. 이는 feature map의 각 위치에 $(c+4)k$개의 filter가 적용되어, $m\times n$개의 위치에 대해 총 $(c+4)kmn$개의 출력을 생성함을 의미한다.
Default Box의 구조는 Faster R-CNN에서 사용된 앵커 박스들과 유사한 구조이다. 그러나, SSD는 다양한 해상도를 가진 여러 개의 feature map에 이를 적용하였다는 차이점이 있다. 이를 통해 효율적으로 가능한 출력 box들의 형태를 이산화(discretize)할 수 있다.
Training
Region Proposal을 사용하는 기존 모델들과 SSD 학습의 가장 큰 차이점은, 고정된 출력 집합 속 특정 출력에 ground truth 정보가 매칭되어야 한다는 점이다. 이런 방식은 YOLO나 Faseter R-CNN, MultiBox의 Region Proposal에도 일부 적용된 바 있다. 이 매칭 작업이 끝나면, 손실 함수와 역전파가 end-to-end로 적용된다. 학습 과정에는 객체 인식에 필요한 default box들과 스케일을 고르는 것, hard negative mining과 data augmentation 전략도 포함된다.
Matching strategy
학습 과정에서, 어떤 default box들이 ground truth에 대응하여 학습에 사용될지 결정해야 한다. 각 GT 박스에 대해 우리는 다양한 위치, aspect ratio, 스케일의 default box를 고를 수 있다. 먼저 GT 박스와 각 default box들을 best jaccard overlap으로 매칭시켜보는 것으로 시작한다. (자카드 지수: 두 집합의 교집합을 합집합으로 나눈 것, IOU) 이는 MultiBox와 유사하지만, 그와는 다르게 자카드 지수가 임계값(0.5)을 넘는 모든 GT와 default box를 매칭한다. 이는 학습 과정에서 가장 많이 겹치는 하나의 박스를 찾는 대신 다양한 박스들에 대해 점수를 예측할 수 있도록 한다.
Training objective
SSD의 학습 목표는 MultiBox에서 유도되었으나, 여러 클래스를 다룰 수 있도록 확장되었다. $x^p_{ij} = {1, 0}$이 $i$번째 default box를 $p$ 클래스를 갖는 $j$번째 GT 박스와의 매칭 여부를 나타낸다고 하자.
위의 매칭 전략에 따라, $\sum_i x^p_{ij} \geq 1$이 성립된다. 최종 목표 함수는 localization loss(loc)와 confidence loss(conf)의 가중합이다.
$$ L(x,c,l,g) = \frac{1}{N}(L_{conf}(x,c) + \alpha L_{loc}(x,l,g))$$
$N$은 매칭된 default box의 개수이다. 만약 $N=0$이면, loss를 0으로 설정한다. $L_{loc}$는 예측 박스 $(l)$과 GT 박스 $(g)$의 Smooth L1 loss이다. Faster R-CNN과 비슷하게, default bounding box$(d)$의 중심 좌표 $(cx, cy)$와 너비 $(w)$, 높이 $(y)$를 계산한다.
논문 속 수식을 한 줄씩 풀어보자.
$$ L_{loc}(x,l,g) = \sum^{N}_{i\in \text{Pos}} \sum_{m\in \{ cx, cy, w, h \}} x_{ij}^k \text{smooth}_{L1}(l_i^m - \hat{g}_j^m)$$
Localization Loss는 예측 상자 $l$과, 실제 상자 $g$와 default box $d$의 차이를 나타내는 $\hat{g}$의 각 offset값 $(cx,cy,w,h)$의 smooth L1의 합이다.
$$ \hat{g}_j^{cx} = (g_j^{cx} - d_i^{cx} / d^w_i)\quad \hat{g}_j^{cy} = (g_j^{cy} - d_i^{cy})/d_i^h$$
$$ \hat{g}^w_j = \log(\frac{g_j^w}{d_i^w})\quad \hat{g}^h_j = \log(\frac{g_j^h}{d_i^h})$$
위 식에 $d$와 $g$의 offset에 포함된 $(cx, cy, w, h)$들의 차이를 각각 어떻게 구하는지 나타나있다.
$$ L_{\text{Conf}}(x,c) = - \sum^N_{i \in \text{Pos}}x^p_{ij} \log(\hat{c}_i^p) - \sum_{i \in \text{Neg}} \log(\hat{c}_i^0), \; \text{where}\; \hat{c}_i^p = \frac{\exp(c_i^p)}{\sum_p\exp(c_i^p)} $$
Confidence Loss는 softmax loss over multiple classes confidences $(c)$의 형태로 나타난다.
위 식에서, $\hat{c}_i^p$는 $i$번째 예측 box가 $p$ 클래스로 분류한 것의 softmax값을 의미한다. 이때, $0\sim1$의 값을 갖는 $\hat{c}$에 $\log$를 취함으로써, $0\sim -\infty$ 의 loss를 갖도록 만들어준다. Loss는 양수여야 하기에, 각 항에 $-$ 기호를 붙여 양수로 바꿔준다.
식에서 좌측 항은 positive sample, 객체를 올바르게 인식한 box를 의미한다. 반대로 우측 항은 negative sample로 객체를 잘못 인식한 box를 의미하는데, 이때 $\hat{c}_i^0$은 이 잘못 인식된 box가 background class로 잘 분류가 되었는지를 의미한다.
Choosing scales and aspect ratios for default boxes
Overfeat과 SPP Net에서 각기 다른 크기의 이미지를 분석하여 결과를 합치는 것을 통해 다양한 크기의 객체를 다루는 것을 이미 보인 바 있다. SDD는 단일 신경망 내부의 여러 계층에서 생성되는 각기 다른 크기의 feature map을 분석하는 것을 통해 이와 같은 효과를 보고, 동시에 모델의 파라미터를 공유할 수 있었다.
이전 연구들 [논문 레퍼런스 10, 11]에서 신경망 뒤쪽의 레이어로부터 얻은 feature map들이 입력 객체에 대해 더욱 상세한 정보를 가지고 있음을 보였다. 비슷하게, ParseNet 또한 feature map에서 추출한 global context를 이용하는 것이 출력을 더 부드럽게(smooth) 해주는 효과가 있음을 보였다.
이러한 결과들을 참고하여, SSD는 신경망 전반부와(upper) 후반부에서(lower) 얻은 feature map 모두를 객체 인식에 활용하였다. Figure 1에서 다른 크기($8\times 8, 4\times 4$)의 feature map들을 사용한 예시를 볼 수 있다. 실제 상황에서 우리는 조금의 컴퓨팅 자원을 활용하여 더욱 많은 feature map들을 사용할 수 있다.
신경망의 각기 다른 계층에서 추출한 feature map들은 각각 다른 receptive field를 가지고 있다. SSD 프레임워크의 default box들은 실제 receptive field에만 한정되지 않는다. SSD의 default box들은 다양한 객체의 크기에 대응할 수 있도록 설계되었다. 우리가 $m$개의 feature map들을 예측에 사용한다고 할 때, default box들의 스케일은 다음과 같이 계산된다.
$$ s_k = s_\min + \frac{s_\max - s_\min}{m-1}(k-1), \quad k\in [1,m]$$
$s_\min$이 $0.2$이고, $s_\max$가 $0.9$라고 하면, 가장 낮은(lowest) 레이어는 $0.2$의 스케일을 갖고 가장 높은(highest) 레이어는 $0.9$의 스케일을 갖는다. 그리고 그 사이의 레이어들은 그 사이의 균등하게 나눠진 스케일들을 갖는다.
우리는 default box들에 다양한 비율(aspect ratio)들을 부여하는데, 이를 $a_r \in \{1, 2, 3, \frac{1}{2}, \frac{1}{3} \}$으로 나타낸다. 우리는 각 box의 너비 $w$와 높이 $h$를 다음과 같이 계산할 수 있다.
$$ w_k^a=s_k\sqrt{a_r}, \quad \quad h_k^a = s_k / \sqrt{a_r}$$
만약 aspect ratio가 1이라면, 우리는 스케일이 $s'_k = \sqrt{s_ks_k+1}$인 default box를 추가로 생성하는데, 이를 통해 feature map의 한 cell마다 6개의 default box를 만들게 된다. (5개의 aspect ratio를 가진 박스들과 추가 박스)
각 default box의 중심은 $(\frac{i+0.5}{|f_k|},\frac{j+0.5}{|f_k|})$로 설정하는데, $|f_k|$는 $k$번째 feature map의 크기를 의미하고, $i, j \in [0, |f_k|]$이다.
이렇게 다양한 레이어의 모든 위치에서 수집된 다양한 스케일과 aspect ratio를 갖는 default box들의 예측들을 조합하여, 우리는 다양한 크기와 형태를 가진 입력 객체들에 대한 예측들을 얻을 수 있다. 예를 들어, Figure 1. 에서 강아지는 $8\times 8$의 feature map에서는 어떤 box와도 매치되지 않았으나, $4 \times 4$ feature map에서는 매치되었다.
Hard Negative Mining
매칭 단계를 지나면, 특히, default box의 수가 많을 때 대부분의 default box들이 negative sample이다. 이는 Positive Sample과 Negative Sample의 개수 불균형을 초래하는데, 이를 모두 사용하는 대신 negative sample 중 confidence score가 높은, 많이 잘못 예측한 box들을 골라내어 negative sample과 positive sample의 비율을 3:1로 맞춰주었다. 이 과정을 통해 더 빠르고 안정적인 학습이 가능해졌다.
Data Augmentation
모델이 더 다양한 크기와 형태의 입력에 강건해지도록, 다음 방법들로 입력 이미지를 랜덤 하게 증식시켰다.
- 전체 입력 이미지를 그대로 사용
- 객체와 IOU가 0.1, 0.3, 0.5, 0.7, 0.9 이상을 갖는 패치를 샘플링
- 랜덤하게 패치를 샘플링
샘플링된 패치의 크기는 원래 이미지의 0.1 ~ 1배이다. 또한 비율은 1/2에서 2가 사이로 조정되었다. 만약 ground truth 상자의 중심이 샘플링된 패치의 내부에 존재한다면, 그 박스는 그대로 유지했다.
이렇게 샘플링된 패치들은 고정된 크기로 변환된 후, 0.5의 확률로 수평 반전되거나, Some improvements on deep convolutional neural network based image classification 논문에서 언급된 것과 비슷한 몇 가지 변환이 적용되었다.
Experimental Results
Base network
모든 실험에서 base network는 ILSVRC CLS-LOC 데이터셋에서 학습된 VGG16 모델을 사용했다. 우리는 fc6, fc7 계층을 합성곱 계층으로 바꾸었고, fc6와 fc7 계층의 파라매터들을 subsample 했다. pool5 계층은 $2\times 2$에 stride 2에서 $3 \times 3$ stride 1으로 수정하고 dilated pooling (논문에서는 atrous 알고리즘이라 표현)을 사용하였다.
우리는 모든 dropout 계층과 fc8 계층을 삭제했다. 그다음 learning rate 0.001, momentum 0.9, weight decay 0.0005, batch size 32를 적용한 SGD를 사용해 모델을 파인튜닝했다. learning rate decay는 데이터셋마다 약간씩 다르게 적용했다.
PASCAL VOC2007
PASCAL VOC2007 데이터셋에서 VGG16 백본 네트워크를 사용하는 Fast R-CNN, Faster R-CNN 모델과 SSD 모델의 비교를 진행했다.
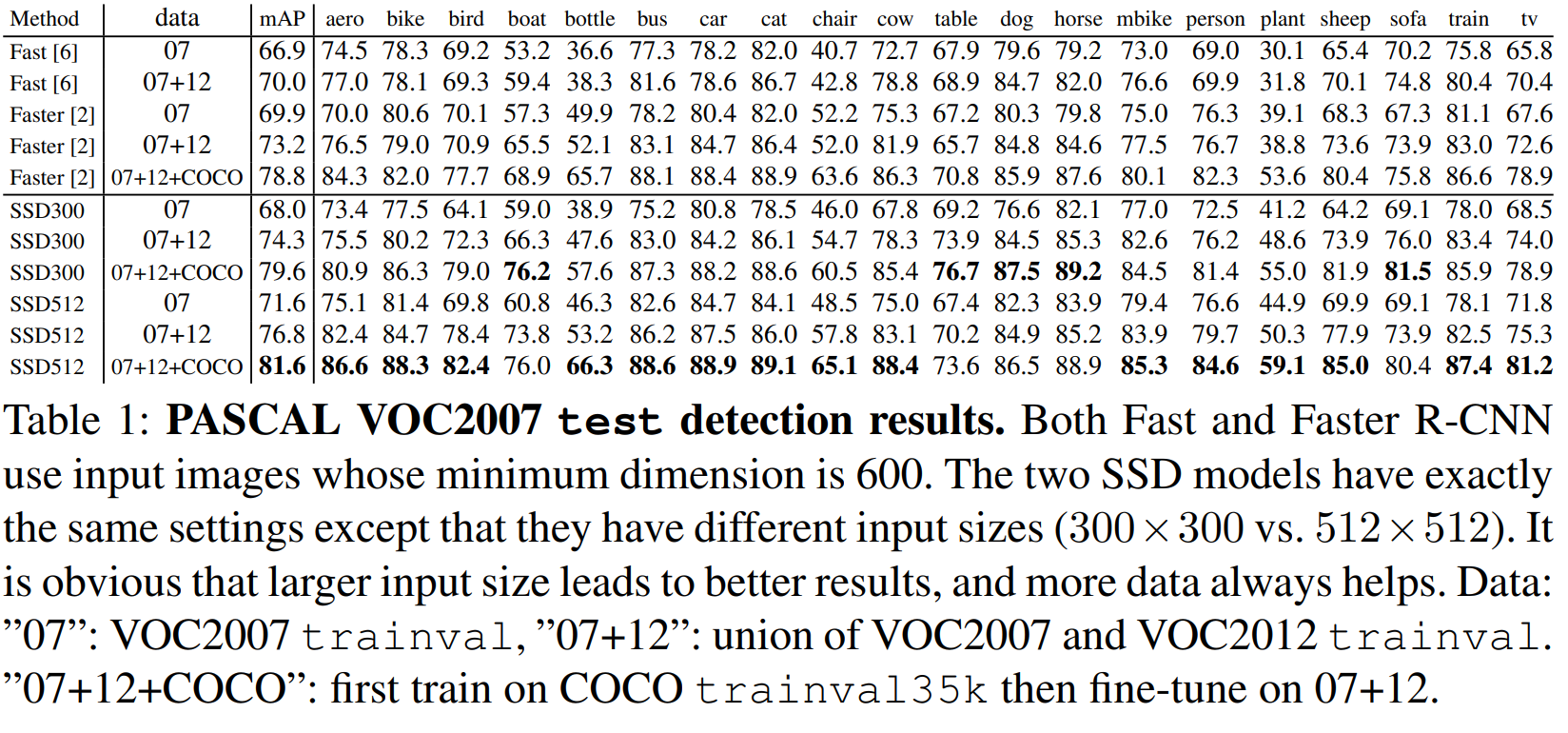
실험에서는 conv4_3, conv7 (fc7), conv8_2, conv9_2, conv10_2, conv11_2 계층들을 이용하여 detection을 수행했다. conv4_3 계층에서 default box를 스케일 0.1로 설정했다. (SSD512 모델에서는 추가로 $s_\min$을 0.15로 설정한 conv12_2 계층을 더하고, conv4_3은 0.07로 설정하여 예측을 수행했다.(이 부분에서 conv4_3의 스케일이 왜 $s_\min$보다 작은지 이해를 못 했다. 구현을 보고 확인할 예정이다.)) 새롭게 추가된 모든 합성곱 계층은 xavier 방법으로 초기화하였다. conv4_3, conv10_2, conv11_2 계층에서는 aspect ratio가 1/3, 3인 box들을 생략하고 오직 4개의 default box들만을 feature map 상의 각 위치에 적용하였다. 나머지 계층들에 대해서는 Section 2.2에서 설명한 것처럼 6개의 default box들을 적용했다. ParseNet 논문에서 설명한 것처럼, conv4_3 계층은 다른 계층들과 비교했을 때 다른 스케일의 feature map을 가지고 있기에, ParseNet 논문과 같이 L2 normalization을 적용하여 각 위치의 feature norm을 20으로 조정하였고, 역전파 과정에서 스케일을 학습하였다. 우리는 첫 40000번의 학습동안 $10^{-3}$ learning rate를 적용하고, 10000번의 학습을 $10^{-4}, 10^{-5}$의 learning rate로 진행했다. 표 1을 보면, 우리의 저해상도 모델인 SSD300이 이미 Fast R-CNN의 정확도를 앞섰음을 볼 수 있다. SSD를 더 큰 $512\times512$ 입력 이미지로 학습시키자 모델은 더욱 정확해졌다. VOC 07과 VOC 12를 합쳐 더 큰 데이터에서 학습시킨 SSD300 모델은 Faster R-CNN과 SSD512 모델을 앞섰다. VOC 07 + 12, COCO 데이터를 모두 합쳐 학습시킨 SSD512 모델은 $81.6%$ mAP로 최고의 성능을 내었다.
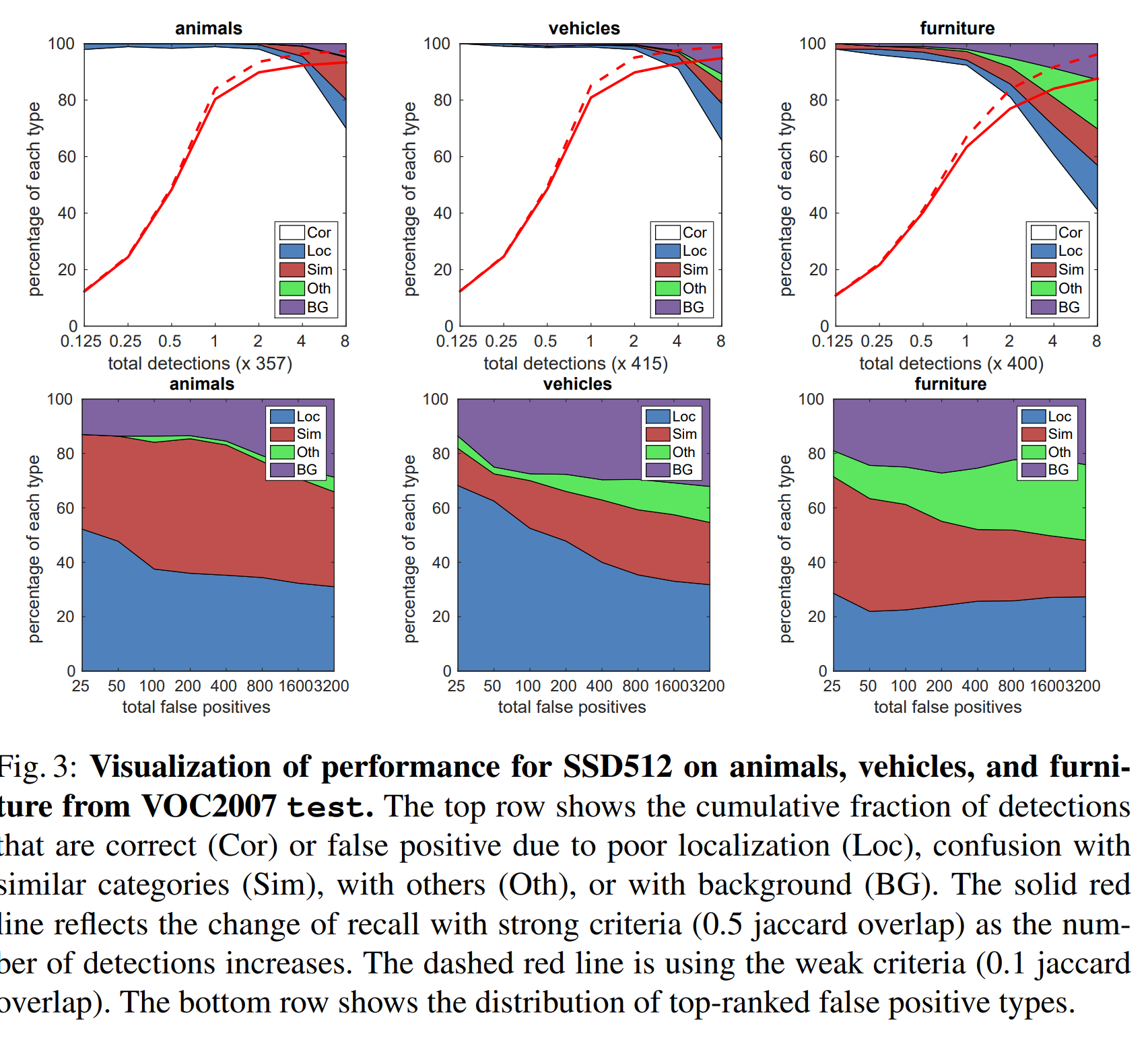
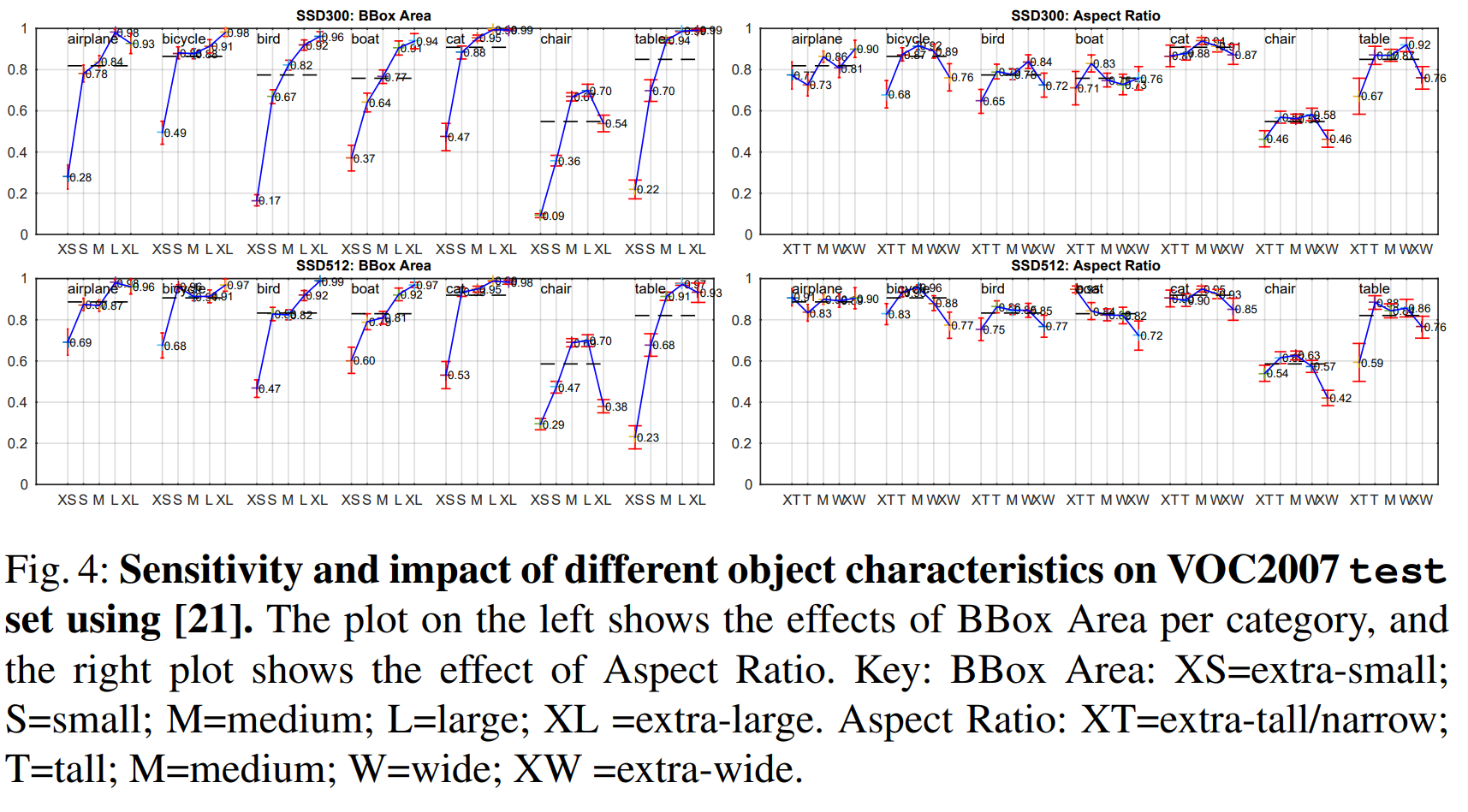
그림 3은 SSD가 다양한 객체들을 좋은 퀄리티로 검출할 수 있음을 나타낸다.(넓은 하얀색 영역)
대부분의 Confident Detection이 정답이었다. Recall은 약 $85-90%$ 수준이었고, IOU 임계점을 0.1로 하여 더 약한 기준을 설정하니 더욱 개선되었다. R-CNN과 비교해서, SSD는 객체의 위치를 인식하는 별도의 과정 없이도 더 적은 Localization Error를 보여 나은 성능을 내었다. 그러나, SSD는 여러 개의 클래스에 대한 위치를 공유하는 특성 탓에 비슷한 종류의 객체들(동물 등)을 분류하는 데 있어 더 어려움을 겪었다. 그림 4. 는 SSD가 bounding box의 크기에 매우 민감함을 보인다. 다시 말해, SSD는 큰 물체보다 작은 물체들에 대해 훨씬 성능이 안 좋다. 이는 이러한 작은 물체들이 상위 레이어에서는 아예 조금의 정보조차 없을 수도 있음을 생각하면 놀랍지 않은 결과이다. 입력 크기를 증가시키는 것(예를 들어, $300\times 300$을 $512\times 512$로)이 작은 물체들을 인식하는데 도움이 되지만, 여전히 개선의 여지가 많다. 긍정적인 점은, 큰 물체들에 대해서는 SSD의 성능이 확실히 뛰어나다는 것이다. 또한 우리가 다양한 비율의 default box를 사용한 덕에, SSD는 다양한 비율의 물체들에 대해 매우 강건한 성능을 보여준다.
모델 분석
SSD를 더 잘 이해하기 위해, 모델의 각 부분이 성능에 얼마나 영향을 주는지 분석하였다. 모든 실험을 위해 우리는 실험 내용과 유관한 설정을 제외하고 입력 크기 $(300\times300)$를 포함해 모두 같은 설정을 사용하였다.

데이터 증식은 중요하다. Fast, Faster R-CNN은 원본 이미지와 수평 반전 이미지를 학습에 사용했다. 우리는 YOLO와 같이 한층 더 다양한 샘플링 전략을 사용했다. 표 2. 는 우리가 어떻게 $8.8%$의 mAP를 향상시켰는지 보여준다. 우리는 이런 데이터 증식이 R-CNN 모델들에서 정확히 얼마나 영향을 줄지는 모르지만, 해당 모델들은 분류 과정에서 feature pooling 과정을 사용하기에 객체의 변환(translation)에 강건한 만큼, SSD에서만큼 데이터 증식이 큰 영향을 주지는 않으리라 생각한다.
다양한 default box 형태를 사용하는 것이 좋다. 섹션 2.2에서 설명했듯이, 우리는 각 위치당 6개의 default box들을 사용했다. 우리가 $\{\frac{1}{3}, 3\}$ aspect ratio의 상자를 지우면 성능은 $0.6%$ 감소하였고, $\{\frac{1}{2}, 2\}$ 상자를 제거하자 $2.1%$나 감소하였다. 다양한 default box 형태들을 사용하는 것이 예측을 쉽게 만드는 것으로 보인다.
Atrous(Delation)이 빠르다. 섹션 3. 에서 설명한 것처럼, 우리는 VGG16의 atrous 버전의 파라미터를 subsample 하여 사용하였다. 만약 VGG16 모델에서 $2\times 2$, stride 2를 갖는 pool5 계층을 놔두고 fc6, fc7 계층을 subsample 하고 예측을 위해 conv5_3을 추가하지 않으면, 결과는 같은 반면 속도는 20%가량 느려졌다.

각기 다른 해상도의 output layer 여러 개를 사용하는 게 좋다. SSD의 주요 contribution은 다양한 스케일의 default box들을 다양한 output layer에 적용한 것이다. 이 방법의 장점을 측정하기 위해, 우리는 각 계층을 점진적으로 제거하며 결과를 비교해 봤다. 공정한 비교를 위해 매번 계층을 제거할 때마다, 남아있는 계층의 box들의 스케일이나 비율 등을 추가하고 조정하며 default box의 총량(8732)은 비슷하도록 조정을 가했다.
표 3을 보면, 계층이 줄어들수록 정확도가 74.3에서 62.4로 하락하는 것을 볼 수 있다. 우리가 box를 추가할 때 많은 box들이 이미지 경계에 겹치는 문제가 생겼는데, 이는 Faster R-CNN과 같이 경계에 겹친 상자들은 무시하여 해결했다.
흥미로운 점은, 우리가 거친(coarse) feature map(예를 들어, conv11_2 $(1\times 1)$이나 conv10_2 $(3\times3)$)을 사용하면 성능이 크게 하락하였다는 점이다. 이는 어쩌면 pruning을 거친 후, 이처럼 큰 객체들을 위한 상자들이 남지 않았기 때문으로 추측된다. 반면 우리가 더 고운(fine) feature map들을 추가할 때마다 성능은 개선되었다.
다양한 스케일의 계층에 분산된 box들을 사용하는 것이 좋음을 반증하듯, conv7 계층만을 예측에 사용하자 성능은 최저를 달성했다. 한편, 모델의 예측이 ROI Pooling에 의존하지 않기 때문에, 저해상도의 feature map에서 collapsing bins 문제가 발생하지 않았다.
SSD 모델은 다양한 해상도의 feature map들로부터의 예측들을 조합함으로써, 더 낮은 해상도의 입력 이미지에서도 Faster R-CNN와 견줄만한 정확도를 달성했다.
PASCAL VOC 2012
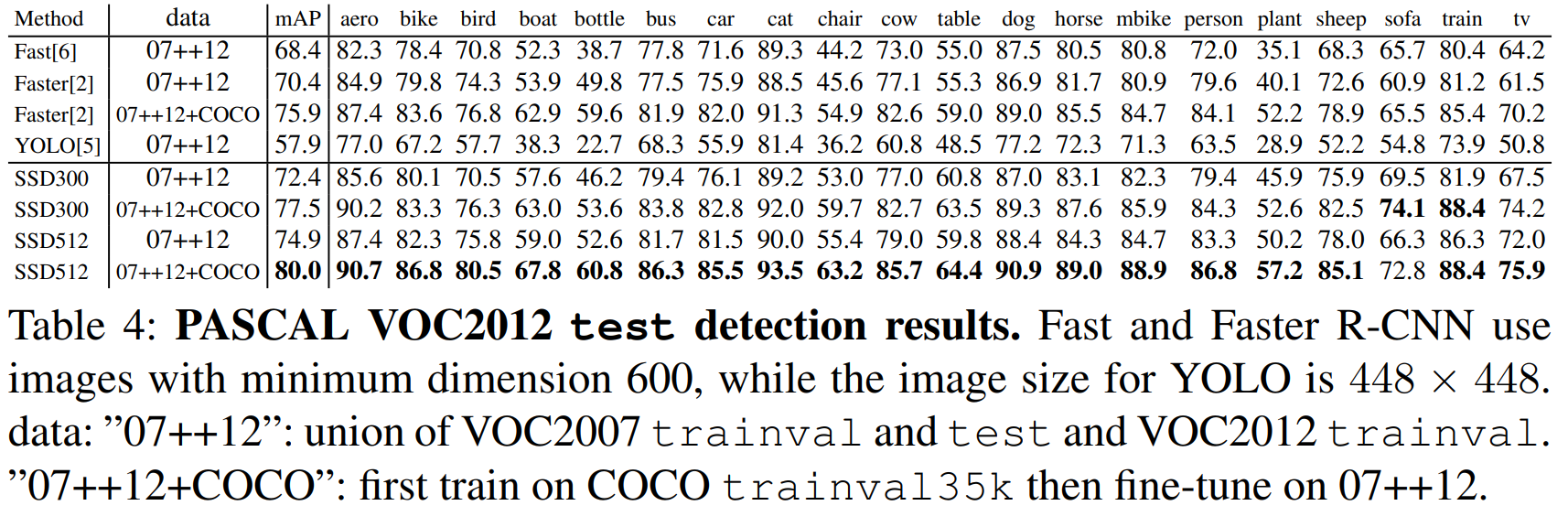
위에서 설명한 VOC2007에서와 같은 설정에서, VOC2012의 학습 데이터에 더해 VOC2007의 학습 데이터와 테스트 데이터를 합쳐 학습을 진행하고, VOC2012 테스트 데이터로 테스트를 진행했다.
모델은 $10^{-3}$의 learning rate로 60000번, $10^{-4}$로 20000번 학습했다. 표4는 SSD300과 SSD512 모델의 실험 결과를 보여준다. VOC2007에서의 실험과 비슷한 성능 증가폭을 확인할 수 있다.SSD300은 Fast/Faster R-CNN의 성능을 뛰어넘었다. 데이터의 크기를 $512 \times 512$로 증가시키자, SSD는 Faster R-CNN보다 $4.5%$ 높은 정확도를 얻었다. YOLO와 비교하여도 SSD는 더욱 정확하였고, COCO 데이터셋까지 더하자 SSD512는 $80.0%$ mAP를 달성하였다.
COCO
SSD 모델을 COCO에서도 학습시켜 검증하였다. COCO의 객체들이 PASCAL VOC보다 작은 경향이 있어, 전체 계층에 한층 작은 default box들을 적용했다. default box들은 0.15 대신 0.2의 scale을 가졌고, conv4_3의 default box는 0.07(즉, $300\times 300$ 이미지에 대해 21픽셀)의 스케일을 가졌다.
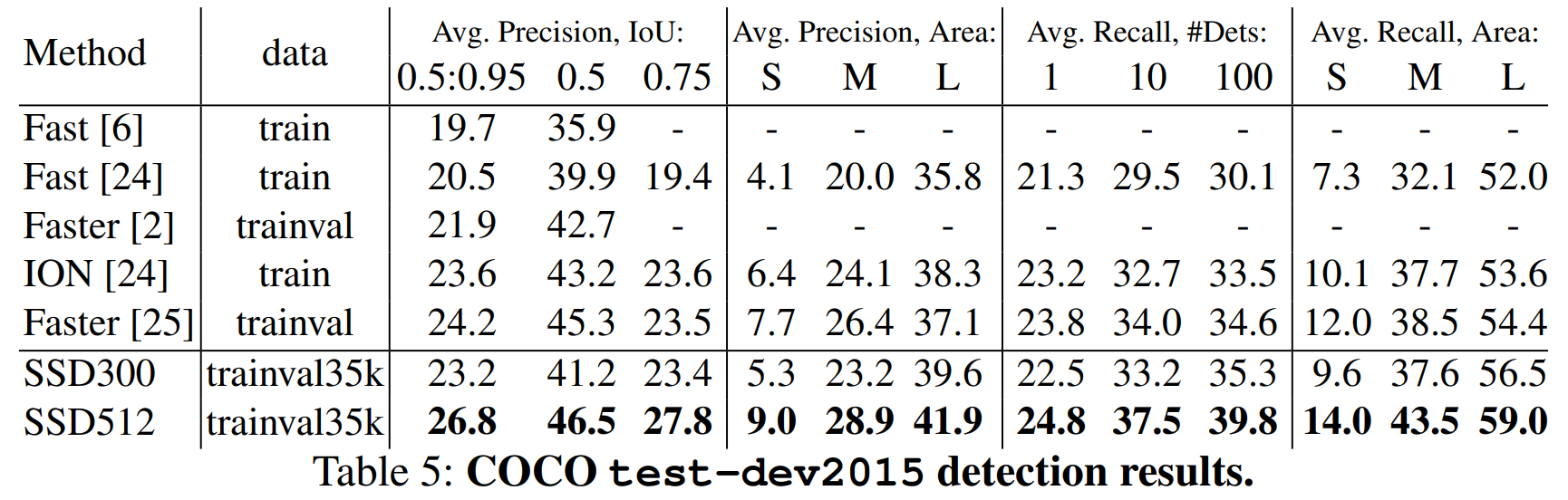
우리는 $10^{-3}$ learning rate로 160000회, $10^{-4}. 10^{-5}$로 각각 40000회 학습을 진행했다. 표 5에 그 결과가 나타나있다. PASCAL VOC의 결과와 비슷하게, SSD300은 Fast R-CNN에 비해 mAP@0.5, mAP[0.5:0.95]에서 앞선 결과를 보였다. SSD300은 ION, Faster R-CNN과 비슷한 mAP@0.75를 내었으나, mAP@0.5는 더 낮았다. 이미지 크기를 늘리자 SSD512는 Faster R-CNN보다 좋은 성능을 내었다. 흥미롭게도, SSD512는 mAP@0.75에서는 5.3% 나은 성능을 보여줬지만, mAP@0.5에서는 1.2%만 앞섰다.
또한 우리는 큰 물체에서는 AP와 AR이 많이 개선되었으나, 작은 물체에서는 적은 개선에 그쳤음도 확인했다. Faster R-CNN의 RPN 등의 과정이 작은 물체에서는 SSD와 경쟁할만한 결과를 내어주는 것으로 추정한다.
Preliminary ILSVRC results
COCO에서 사용한 것과 같은 구조를 이용해 ILSVRC DET 데이터셋에서 실험을 진행했다. $10^{-3}$ learning rate로 320000회, $10^{-4}, 10^{-5}$로 각각 80000번과 40000번 학습했고, 역시 SSD가 고품질의 실시간 객체 인식 결과를 보였다.
Data Augmentation for Small Object Accuracy
Faster R-CNN과 같은 feature resampling 과정이 없는 SSD는 상대적으로 작은 물체들을 분류하는데 어려움이 있다. 데이터 증식은 이를 개선하는데 상당한 도움이 되었다. 특히 PASCAL VOC와 같이 작은 데이터셋에서, zoom in 방법을 통해 많은 큰 데이터 샘플을 얻을 수 있었다. 우리는 데이터 증식에 새로운 "expansion" 방법도 사용하였는데, 이를 통해 학습 iteration을 배가하고, 다양한 데이터셋에서 $2% - 3%$의 mAP 상승을 이룰 수 있었다. 특히, 이 새로운 방법을 통해 작은 물체를 인식하는 성능을 잘 향상시켰다. SSD를 개선하기 위한 또 하나의 방법은 더 나은 위치와 스케일의 receptive field를 갖는 default box들을 만들고 채우는 더 나은 방법을 설계하는 것인데, 이는 다음 연구를 위해 남겨놓겠다.
Inference time
우리의 방법을 통해 대량의 box들이 생성됨을 감안하면, 추측 과정에서 효율적인 non max suppression(NMS)을 적용하는 것이 필수적이다. confidence threshold를 0.01로 하여, 대부분의 상자들을 삭제할 수 있다. 그 후, 클래스별로 IOU 0.45를 적용하고, 이미지별로 200개의 detection만을 남긴다. 이 과정은 SSD300에서 20개의 클래스를 가진 VOC에 대해 장당 약 1.7 밀리초의 시간이 소요되는데, 이는 거의 새로 추가된 계층들의 실행 시간(2.4 밀리초)에 가깝다. 우리는 batch size 8에 Titan X, cuDNN v4, Intel Xeon E5-2667v3@3.2GHz 하드웨어로 실험을 진행했다.
SSD300과 SSD512 모두 Faster R-CNN을 속도와 정확도 측면에서 앞질렀고, Fast YOLO가 155FPS의 속도를 보였으나, mAP가 SSD에 비해 22%나 떨어졌다. SSD300은 연구진이 알기로, 70% 이상의 mAP를 달성한 최초의 실시간 detector 모델이다. Base network인 VGG16를 통과하는데 전체 수행시간의 8할이 투자된 것도 기억하라. 더 빠른 Base Network를 사용하면 속도는 더욱 개선될 여지가 있다.
Related Works
이 논문에서 소개된 SSD는 Reason Proposal이 없는 1-stage detector로, OverFeat이나 YOLO와 비슷한 구조이다.
만약 SSD에서 최종 feature map에 각 cell 별로 하나의 default box 만을 사용한다면 OverFeat과 비슷하고, 최종 feature map을 Convolutional Detector 대신 Fully Connected layer로 구성된 Detector에 넣는다면 YOLO와 비슷한 구조가 될 것이다.
Conclusion
이 논문은 빠른 속도의 싱글 샷 object detector인 SSD를 소개했다. SSD의 주요 기능은 신경망의 여러 feature map으로부터 출력되는 다양한 스케일의 convolutional bounding box이다. 이를 통해 다양한 형태의 박스들을 효과적으로 모델링할 수 있다. 우리는 실험을 통해 잘 선택된 대량의 default bounding box들이 성능을 향상함을 검증했다. 우리는 기존 모델들에 비해 훨씬 많은(order of magnitude) 각기 다른 위치, 스케일, 비율을 갖는 box들을 적용하였다. VGG16 기반의 SSD를 통해 기존의 SOTA급 경쟁 모델들을 속도와 정확도 측면에서 앞섰다. SSD512 모델은 PASCAL VOC와 COCO에서 Faster R-CNN을 정확도 측면에서 앞서면서도, 3배 더 빠른 속도를 달성하였다. SSD300 모델은 59FPS로 작동하며 real time YOLO를 속도와 정확도 측면에서 앞섰다.
리뷰
처음으로 참고자료 없이 논문만을 처음부터 끝까지 읽어보았다.
확실히 이전 논문들을 알고 있던 것이 논문에서 등장하는 다양한 개념들을 이해하는데 크게 도움이 되었다.
그러나 이전 논문들에서 100% 이해하지 못한 부분들은 오히려 이 논문을 읽는데 방해가 되기도 하여서, 논문 하나하나를 정성 들여 잘 읽어야겠다는 생각이 들었다.
SSD가 달성한 성과와 아이디어를 보며, 정말 재밌고 놀랍다는 생각이 들었다. Single Stage Detector라 해서 OverFeat이나 YOLO만을 참고한 것이 아니라, Faster R-CNN, SPP 등 정말 온갖 논문의 지식을 다 모으고, Data Augmentation 등의 스킬까지 총동원한 결과, 경쟁자들을 크게 앞지를 수 있었다.
SSD가 처음 등장한 시기에 이 논문을 알았더라면 정말 경이롭게, 즐겁게 읽었을 것 같다.
(사실 지금도 그렇다.
이제 SSD를 더 잘 이해하고, 구현도 해봐야겠다.
참고자료
- SSD: Single Shot MultiBox Detector - Wei Liu et al.